Sviluppare app mutipiattaforma - Le basi: l’algoritmo e il codice (prima parte)
> INDICE DEL CORSO < Articolo precedente: Sviluppare app multipiattaforma - Un’introduzione
Argomenti:
- Occorre sapere qualcosa sull'hardware?
- Macchine programmabili e algoritmi
- L’incertezza e l'arroganza dell’algoritmo: fa quello che vuole lui, quello che vogliamo noi o quello che capita?
- L'algoritmo agnostico
Occorre sapere qualcosa sull’hardware?
 Generalmente noi programmatori, salvo motivate eccezioni, nel nostro lavoro ci concentriamo esclusivamente sul software: ci sono validi e circostanziati motivi per occuparci dell’hardware se ad es. dobbiamo far uso di determinati sensori o se abbiamo bisogno di funzionalità che richiedono almeno un certo tipo di cpu o una certa quantità di memoria. Ad ogni modo, nel caso della programmazione multipiattaforma, ignorare le specificità hardware dei vari dispositivi è particolarmente sensato, in quanto il nostro obiettivo principale è proprio quello di scrivere codice che funzioni “possibilmente” ovunque, ovvero su hardware anche molto diversi. Storicamente molti sono stati e continuano ad essere gli sforzi in tal senso.
Generalmente noi programmatori, salvo motivate eccezioni, nel nostro lavoro ci concentriamo esclusivamente sul software: ci sono validi e circostanziati motivi per occuparci dell’hardware se ad es. dobbiamo far uso di determinati sensori o se abbiamo bisogno di funzionalità che richiedono almeno un certo tipo di cpu o una certa quantità di memoria. Ad ogni modo, nel caso della programmazione multipiattaforma, ignorare le specificità hardware dei vari dispositivi è particolarmente sensato, in quanto il nostro obiettivo principale è proprio quello di scrivere codice che funzioni “possibilmente” ovunque, ovvero su hardware anche molto diversi. Storicamente molti sono stati e continuano ad essere gli sforzi in tal senso.
Tra l’altro, per completezza, ci sono situazioni in cui veramente non sappiamo e non possiamo sapere nulla dell’hardware: pensiamo allo sviluppo di una web-app. Essendo basata su HTML5 + Javascript, sostanzialmente girerà dentro un browser, che potrebbe essere quello di uno smartphone iPhone, Android, Windows Phone e altri, potrebbe essere quello di un computer portatile, potrebbe persino essere lo schermo di un televisore. Non ho mai usato uno smart watch, ma se esso incorpora un browser, allora la nostra web-app potrebbe funzionare anche dentro un orologio da polso. In questi casi non soltanto non ci interessa minimamente l’hardware sottostante, ma saremo presi da ben altri problemi, ad es. quali sono i browser su cui fare i test e le modalità con cui l’utente dovrà interagire con l’app.
Proprio in questo esempio, è evidente che un’app pensata per funzionare su schermi grandi seguirà logiche diverse da una pensata per funzionare sui piccoli schermi dei nostri smartphone; allo stesso modo, un’app pensata per essere usata con una tastiera reale sarà fatta in modo diverso da una pensata per essere usata con una tastiera virtuale, che a sua volta sarà diversa da una destinata ad essere usata con un telecomando.
In sintesi, ciò che in primis ci interessa dell’hardware è come l’utente potrà e dovrà interagire con la macchina, in modo da pensare fin dall’inizio a come dovrà essere l’interfaccia utente.
Macchine programmabili e algoritmi
 Generalmente ci si riferisce ai computer e alle loro varie declinazioni tecnologiche (smart-watch, smart-tv, smart-phone, smart-frullatore, smart-spazzolino, smart-..., ecc.) senza mai usare il termine che più propriamente identifica questi oggetti: macchine.
Generalmente ci si riferisce ai computer e alle loro varie declinazioni tecnologiche (smart-watch, smart-tv, smart-phone, smart-frullatore, smart-spazzolino, smart-..., ecc.) senza mai usare il termine che più propriamente identifica questi oggetti: macchine.
Più nello specifico, trattasi di macchine programmabili, inanimate, ovvero senza vita e prive di ogni forma di intelligenza o di altre caratteristiche umane (cognizione di sé, cognizione degli altri, empatia, sentimenti, ecc.), capaci di eseguire calcoli estremamente semplici dal punto di vista concettuale, e nulla di più. Tutto il resto, a cominciare da una vera forma di intelligenza, ce la mettono i programmatori.
Per dirla ancora più brutalmente, trattasi di macchine in cui segnali elettrici digitali vengono usati per rappresentare valori booleani (cioè “vero” o “falso”). L’algebra di Boole viene utilizzata per la costruzione di porte logiche (porte “and”, “or”, “not” e loro combinazioni), costruite all’interno di circuiti integrati basati su transistor.
Non mi dilungo oltre, l’importante è aver chiaro noi programmatori abbiamo a che fare con macchine programmabili: la distanza concettuale tra scrivere codice ad altissimo livello di astrazione, ovvero multipiattaforma, e i segnali elettrici che poi di fatto faranno funzionare il nostro codice, è così ampia che c’è il serio rischio di dimenticarci ciò con cui abbiamo a che fare. Specialmente in questo periodo storico, in cui c’è un’enorme enfasi sull’Internet delle Cose e sull’Intelligenza Artificiale, il rischio di esser fuorviati è enorme.
L’intelligenza è propria soltanto degli organismi viventi creati dalla natura: le nostre macchine, per quanto sofisticate, sono e rimangono macchine inanimate calcolanti, incapaci di intendere e di volere.
 Detto ciò, per rendere queste macchine capaci di “fare qualcosa” noi scriviamo algoritmi. Al di là delle varie definizioni formali di “algoritmo”, per le quali rimando alla relativa voce su Wikipedia, sostanzialmente un algoritmo è un’entità che fa qualcosa e, nella pratica quotidiana, questa entità non è altro che un pezzo di codice.
Detto ciò, per rendere queste macchine capaci di “fare qualcosa” noi scriviamo algoritmi. Al di là delle varie definizioni formali di “algoritmo”, per le quali rimando alla relativa voce su Wikipedia, sostanzialmente un algoritmo è un’entità che fa qualcosa e, nella pratica quotidiana, questa entità non è altro che un pezzo di codice.
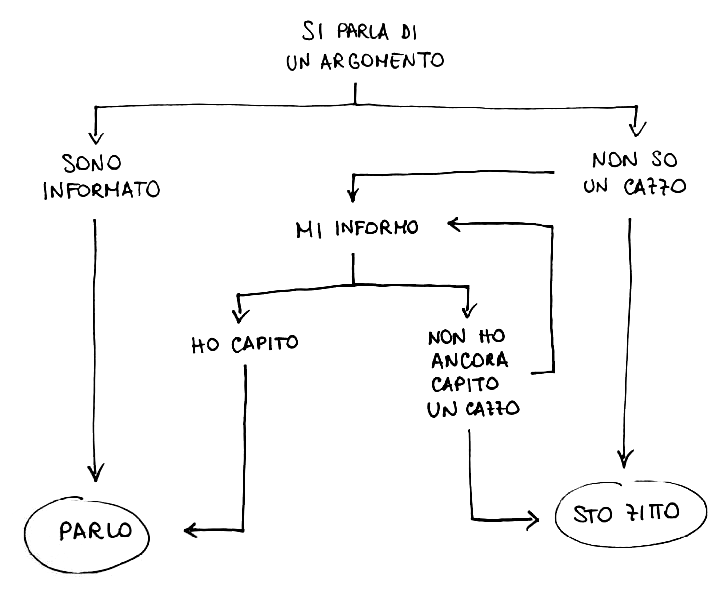
Concettualmente, un algoritmo è un elenco di istruzioni eseguibili da una macchina in un tempo finito per fare una determinata cosa. Comunque, lo stesso concetto si può estendere anche al di fuori dell'Informatica, ad es. una ricetta per cucinare è un algoritmo. Possiamo anche creare algoritmi scherzosi, come quello qui a lato rappresentanto tramite flowchart, che nello specifico è un algoritmo di decisione.
Per ulteriori riflessioni introduttive sul significato di algoritmo, rimando alle mie slides: “Cosa sono i linguaggi di programmazione”, che preparai nel lontano 2005 e che sono tuttora valide (gli esempi di codice a cui mi riferisco nell'ultima pagina sono a questo link):
L’incertezza e l'arroganza dell’algoritmo: fa quello che vuole lui, quello che vogliamo noi o quello che capita?
Molteplici algoritmi tra loro interagenti, all’interno di una complessità algoritmica spaventosa e quasi inconcepibile per noi persone comuni, rendono utilizzabili le nostre macchine programmabili, ad es. i nostri smartphone.
Per avere un termine di paragone sul livello di complessità delle macchine al nostro servizio, prendiamo un recente e triste caso di cronaca: il 29 ottobre 2018, un aereo della ditta Boeing, nuovissimo, modello “737 MAX”, pochi minuti dopo il decollo da Giacarta, cadde. Morirono tutti (189 persone, più un’altra persona incaricata delle ricerche in mare). La causa fu un errore di programmazione del software di controllo dell’areo, nello specifico un errore di rilevazione della velocità (sto semplificando, in rete si trovano i dettagli di quel che accadde). Orbene, il software di controllo di tale aereo era composto da circa 14 milioni di righe di codice (fonte): un errore fatale purtroppo ci poteva anche stare in così tanto codice… soprattutto, per chi s'è letto i rapporti, se ai piloti, come in questo caso, era stata sottratta ogni possibilità di intervento manuale correttivo (il fatto che il computer del Boeing sia stato programmato per "prevalere sull'uomo" è spiegato in questo articolo). Questo è uno di quei casi in cui, in fase di progettazione, dare più credito alla pseudo-intelligenza senz'anima delle macchine che alla vera intelligenza umana ha comportato una strage. Sempre nel 2018, c'è stata un ulteriore strage aerea per lo stesso motivo. In tutti i casi in cui le decisioni umane vengono delegate a macchine si crea una situazione di stupidità umana da una parte e arroganza dell'algoritmo dall'altra. Ho avuto modo di esprimermi a proposito dell'arroganza dell'algoritmo anche nel caso dei social (link).
Nella normalità della mia vita quotidiana di programmatore, se riuscissi a scrivere cento righe senza fare neanche un errore mi complimenterei con me stesso… ma la realtà è tutt’altra: non mi capita quasi mai che quello che scrivo sia corretto e funzionante come desidero già dal primo tentativo; una tale eventualità può capitarmi per cose estremamente semplici che stanno in poche righe (e a volte neanche in quei casi).
La storia dell’informatica è piena di errori di programmazione che sono stati disastrosi e funerei, errori a volte così subdoli da sfuggire ai migliori programmatori al servizio della NASA o di grandi corporation, errori che hanno comportato danni economici ingenti e morte. In questa pagina c'è riportato il codice che, poco dopo un minuto dopo il lancio (era il 1996), ha fatto esplodere un mezzo spaziale per un bug che, tutto sommato, può capitare a qualunque programmatore (tecnicamente, volendo usare la terminologia di Java di cui ci occuperemo nei prossimi articoli, è stato fatto qualcosa di molto simile a un "casting" errato). Basta cercare in Rete per trovare tracce dei bug che hanno segnato la storia dell'Informatica. Un elenco di disastri della NASA per piccoli bug è a questo link. Nel 1983 abbiamo anche rischiato un olocausto nucleare esteso a tutto il pianeta per via di un bug... la notizia venne resa pubblica nel 1990.
Tornando a noi... qualcuno si è anche preso la briga di fare una stima di quanti errori di programmazioni vengano fatti mediamente. Steve McConnell, nel libro di Ingegneria del Software “Code Complete”, ormai storico (la prima edizione è degli anni '90), riportò una media a livello industriale di circa 15-50 errori ogni 1000 righe di codice e - nel caso specifico di Microsoft - conteggiò una media da 10 a 20 errori ogni 1000 righe di codice in prodotti “released”, cioè messi in commercio (fonte). Sebbene queste stime siano molto vecchie (quella di Microsoft si riferisce al 1992), il problema rimane attuale e, soprattutto, se ciò accade alle grandi aziende multinazionali con sviluppatori super-esperti (o presunti tali), figuriamoci a chi non è così esperto...
La complessità è abnorme: il browser Google Chrome è fatto da circa 7 milioni di righe di codice, il sistema operativo Android da 15 milioni, Facebook lato client (senza considerare il software lato server) da circa 60 milioni, il software di controllo delle recenti smart-car da 100 milioni, i servizi di Google, nel loro complesso, da 2 miliardi (fonti).
Per noi comuni mortali, programmatori “normali”, riuscire a scrivere mille righe di codice in un giorno già potrebbe essere una sfida quasi impossibile: concretamente, a volte può capitare di passare un’intera giornata a cercare di risolvere un problema che alla fine sta dietro ad una sola riga di codice, magari messa nel posto sbagliato. Anzi, questa è una stima che ho trovato su Coralogix, che ritengo molto verosimile e all'incirca applicabile anche a me:
- In media, uno sviluppatore crea 70 bug ogni 1000 linee di codice (o 7 ogni 100, ovvero circa 1 ogni 10).
- 15 bug ogni 1000 linee di codice finiscono nei prodotti destinati ai clienti (che spesso scoprono bug che noi programmatori non avevamo visto o, peggio, che non riusciamo neanche a "riprodurre" sulle nostre macchine, cioè a verificare, a far accedere e quindi a poter indagare).
- Trovare la causa di un bug prende 30 volte più tempo che scrivere una linea di codice (anzi, a volte può richiedere una o più giornate e comunque la causa del bug non viene scoperta...)
- Il 75% del tempo di sviluppo è speso nel debugging, cioè nella ricerca delle "cause" dei bug; da notare che trovare la causa dei bug è di solito un requisito per la loro risoluzione, ma non sempre ciò porta ad una immediata risoluzione, che può rivelarsi anche complessa.
- Solo negli Stati Uniti, 113 miliardi di dollari all'anno sono spesi per identificare e risolvere i bug.
Nel contesto di questa complessità, la programmazione è un’enorme sfida. A te che stai leggendo, se stai per incamminarti in questa avventura di programmatore, bella e tragica allo stesso tempo, vorrei dirti che se dedicherai ore e ore a poche righe di codice che non funzioneranno come tu vorrai, allora ti dirò: «Benvenuto in famiglia!» ;-)
Tieni a mente le stime che ho riportato soprattutto nei momenti di difficoltà: capirai che il problema non è solo tuo, anzi, incontrare problemi durante e dopo il coding (cioè la programmazione) è fisiologico.
Sia ben chiaro, inoltre, che gli errori non necessariamente dipendono dalla capacità di chi programma: magari il nostro programma è corretto, ma il codice sottostante che lo farà girare non lo è. Intendo dire che gli errori non sono necessariamente nei programmi che scriviamo, ma possono essere anche nelle piattaforme e linguaggi di sviluppo che utilizziamo. Come esempio, posso riportare questo bug da me segnalato, in cui dimostrai che una banale concatenazione tra stringhe causava un errore su iPhone non dipendente dal mio codice. Negli ultimi anni, ho scoperto e segnalato vari bug della piattaforma di sviluppo da me usata (qui l'elenco), per fortuna quasi tutti prontamente corretti.
Concludo queste riflessioni sui bug con le parole che Edison scrisse nel 1870 (fonte):
«È stato così per tutte le mie invenzioni. Il primo passo è un'intuizione, e viene come una fiammata, poi le difficoltà crescono... le cose non vanno più ed è allora che i "bachi" – così sono chiamati questi piccoli sbagli e difficoltà – si manifestano, e servono mesi di intensa osservazione, studio e lavoro prima che il successo commerciale oppure il fallimento sia sicuramente raggiunto.»
L’algoritmo agnostico
Mentre in italiano il termine “agnostico” ha un precisa accezione filosofica, nell’inglese tecnico-informatico l’aggettivo “-agnostic” è usato come suffisso in varie parole composte con il significato di “non conoscente, indipendente da, non legato in maniera specifica a, compatibile a prescindere dalla caratteristiche specifiche”, ecc. (ad es.: “device-agnostic”). Significati, questi, che in effetti si ricollegano all’agnosticismo, che parte dal presupposto di “non sapere” e di non “avere la possibilità di sapere”.
Un algoritmo, pur traducendosi in linee di codice, di per sé è un concetto astratto, simile al concetto matematico di “funzione”: dato un input, restituisce un output, in base ad una qualche logica specificata all’interno dell’algoritmo stesso. Se siamo a noi a scrivere, cioè creare, un algoritmo, allora ci interessano i dettagli implementativi (cioè la logica interna), ma se usiamo algoritmi scritti da altri, ci basta sapere a grandi linee “cosa fanno”, a prescindere dai dettagli. Soprattutto quando usiamo algoritmi scritti da altri, di solito li trattiamo come “scatole nere”: sappiamo in maniera astratta cosa fanno, ma non sappiamo concretamente “come” (e di solito neanche ci interessa saperlo).
Nella programmazione ad alto livello di astrazione, multi-piattaforma, gli algoritmi che useremo per programmare con Java + Codename One saranno come minimo:
- device-agnostic, cioè indipendenti dai dispositivi su cui tali algoritmi saranno eseguiti (e quindi indipendenti dall’hardware);
- IDE-agnostic, cioè indipendenti dall’ambiente di sviluppo (IDE significa “ambiente di sviluppo integrato”): Codename One consente infatti di utilizzate ambienti diversi, a nostra preferenza.
In più, ogni algoritmo sarà “language-agnostic” rispetto agli altri algoritmi: non soltanto gli altri algoritmi, pur interfacciandosi tra di loro tramite Java, potranno effettivamente essere implementati in altri linguaggi, ma la comunicazione tra app e server backend sarà indipendente dai rispettivi linguaggi di programmazione.
Provo a spiegare meglio quest’ultimo punto: ogni algoritmo potrà richiamare altri algoritmi per far fare loro certe cose, indipendentemente dal linguaggio effettivo in cui questi saranno implementati (ad es. un pezzo di codice scritto in Java potrà richiamare un altro pezzo di codice scritto in Objective-C, qualora fosse necessario): questo è possibile grazie alle cosiddette “interfacce native” di Codename One, su cui per il momento non mi dilungo. In ogni caso, anche rimanendo all’interno dello stesso linguaggio, cioè Java, ogni algoritmo “conosce” la sua implementazione, ma non quella degli altri algoritmi con cui interagisce. Per quanto riguarda la comunicazione client-server, dove l’app per smartphone è il client e il server è il “backend”, cioè ciò che sta dietro le quinte, ciò che l’utente non vede, tale comunicazione normalmente avviene tramite chiamate “REST” che astraggono completamente i rispettivi linguaggi di programmazione utilizzati. Le chiamate REST non sono altro che richieste con protocollo HTTP, come quando si apre una pagina web: il nostro browser non sa nulla del linguaggio di programmazione usato sul server (ad es. PHP o Java), né del linguaggio che il server usa con il suo database (ad es. Sql), eppure la comunicazione funziona perché gli algoritmi che gestiscono le comunicazioni sono indipendenti dai linguaggi di programmazione del client e del server.
Concludo così questa introduzione sugli algoritmi. Prossimamente preparerò un articolo per mostrare come scrivere i primi algoritmi in Java.
Francesco Galgani,
29 novembre 2019
Sviluppare app multipiattaforma - Un’introduzione
> INDICE DEL CORSO
Codice libero, pensiero libero
 Nella nostra società liquida, nel senso di priva di punti di riferimento duraturi, dove tutto cambia dall’oggi al domani, fare ingegneria e sviluppo del software è un’impresa assai ardua. Eppure metter mano a un codice che giorno per giorno prende forma e fa qualcosa di desiderato è un’esperienza che per chi la vive, se ama programmare, ha sempre qualcosa di straordinario. Soprattutto quando il software da noi scritto è usato da altri, e se funziona bene, pare una magia.
Nella nostra società liquida, nel senso di priva di punti di riferimento duraturi, dove tutto cambia dall’oggi al domani, fare ingegneria e sviluppo del software è un’impresa assai ardua. Eppure metter mano a un codice che giorno per giorno prende forma e fa qualcosa di desiderato è un’esperienza che per chi la vive, se ama programmare, ha sempre qualcosa di straordinario. Soprattutto quando il software da noi scritto è usato da altri, e se funziona bene, pare una magia.
Nonostante il modello iper-competitivo e sovente economicamente gramo in cui noi programmatori siamo inseriti, c’è una forza invisibile, una sorta di pulsione sociale, che comunque ci spinge a contribuire a progetti comuni. Basta guardare quanto siano vitali piattaforme di mutua condivisione di codice, come Github, SourceForge, Launchpad e altre, le quali, nonostante di solito non contribuiscano al nostro portafoglio, sono una sana via di espressione della nostra creatività e il nostro modo di lasciare una traccia visibile del nostro passaggio in questo mondo. A noi entusiasti, liberi creatori, appassionati, giovani alle prime armi o hacker convinti, comunque piace condividere il codice. Se il pensiero è libero, allora il codice è libero. Grandi uomini assennati come Richard Stallman l’hanno ben compreso.
Immagino di scrivere questo breve articolo introduttivo per chi, come me, partendo con pochi mezzi e poche conoscenze, si ponga il problema di sviluppare software in un contesto dove non solo tutto pare molto complicato se non addirittura oscuro, ma quello che abbiamo scritto oggi potrebbe non funzionare più già domani. Linguaggi e piattaforme sono aggiornati in maniera frenetica, i dispositivi in circolazione sono così tanti e diversificati che scrivere un’app che funzioni “ovunque” potrebbe sembrare un’utopia.
Cosa dire, inoltre, del fatto che anche la creazione del progetto più semplice, inserito nel contesto dei dispositivi mobili, implica la padronanza di molti linguaggi diversi, di strumenti di sviluppo che paiono agli antipodi (giusto per fare un esempio: Android Studio e Apple Xcode), e sovente con un costo in hardware e licenze non trascurabile?
Purtroppo il classico approccio scolastico e universitario all’informatica e all’ingegneria del software non sembra dare risposte adeguate, anzi, salvo rare e fortunate eccezioni, sembra smarrirsi (e smarrire i discenti) su vie obsolete, oppure aggiornate ma iper-specialistiche, o al contrario iper-semplificate, ma in tutti i casi, per dirla con un po’ di concretezza, poco utili nell’affrontare problemi reali. Pur esistendo corsi ottimi e qualificanti, spesso però sono inseriti nel quadro generale di formazione istituzionalizzata lontana dalle esigenze di chi vorrebbe imparare ad essere operativo e presente nel mare magnum delle app.
E quindi, cosa fare?
Nel mio piccolo, potrei provare a condividere una parte di quel che ho appreso nella mia esperienza lavorativa. Cercherò di esprimermi con un approccio il più possibile utile per chi inizia da zero.
Indicazioni che possano durare nel tempo?
 Il mio auspicio, in questo e in altri miei prossimi articoli, è di riuscire a indicare una valida modalità di ragionamento che possa adeguarsi ai contesti più diversi e che sia il più possibile duratura nel tempo, tenendo a mente che i testi di informatica sono spesso già vecchi e superati nel momento stesso in cui vengono stampati. Mi pongo quindi una domanda: quel che scrivo oggi, è innanzitutto potenzialmente utile oggi? E domani? E tra un anno? Tra dieci anni?
Il mio auspicio, in questo e in altri miei prossimi articoli, è di riuscire a indicare una valida modalità di ragionamento che possa adeguarsi ai contesti più diversi e che sia il più possibile duratura nel tempo, tenendo a mente che i testi di informatica sono spesso già vecchi e superati nel momento stesso in cui vengono stampati. Mi pongo quindi una domanda: quel che scrivo oggi, è innanzitutto potenzialmente utile oggi? E domani? E tra un anno? Tra dieci anni?
Se discutessi del teorema di Pitagora avrei ottime speranze di affrontare un argomento valido per millenni, ora e per sempre... ma se invece volessi affrontare il problema della bontà di un algoritmo allora lo spazio temporale di riferimento sarebbe assai più ristretto (rispetto al teorema di Pitagora). Se poi mi focalizzassi sulla specifica implementazione di tale algoritmo in una specifica versione di un determinato linguaggio di programmazione, il tempo di validità delle mie affermazioni sarebbe ridotto, nella migliore delle ipotesi, a qualche anno. Se poi tale linguaggio, nel presente o comunque in un ragionevole intervallo temporale, non trovasse sbocco lavorativo (o addirittura venisse abbandonato), allora avrei sprecato fiato e tempo? Forse sì, forse no... dipende.
La vera sfida non è quella di costruire una vasta conoscenza nozionistica di tanti linguaggi di programmazione, ma di conoscerne “quanto basta” di pochi, essenziali, duttili, idonei ad adeguarsi a contesti diversi, destinati a ragion veduta a durare nel tempo. E una volta identificate le conoscenze di base, saperle sfruttare all’interno di una modalità di ragionamento adatta a risolvere una molteplicità di problemi diversi.
Gli strumenti di programmazione
Con l’obiettivo di sviluppare applicazioni complete e perfettamente funzionanti per dispositivi mobili, sintetizzo in poche parole quella che secondo me è una delle possibili scelte vincenti:
JAVA + Codename One + Spring Boot
Non solo Java, ovviamente, ci servirà, ma soprattutto Java, con un minimo di conoscenza anche dei CSS e con una minima cognizione di cosa siano i file JSON. Il resto lo vedremo strada facendo (ad es. un minimo di HTML, di gestione di un server Linux tramite SSH, di uso di uno specifico IDE, ecc.), ma comunque rimarranno a un livello di infarinatura minima necessaria: è meglio non sovrabbondare e concentrarci solo su quel che realmente serve.
 Ciò che andrò a trattare dovrebbe essere sufficiente duraturo nel tempo, al di là delle mode del momento: in effetti è una scommessa, fatta però a ragion veduta. Mi spiego con un esempio pratico: le conoscenze di base di Java che ho acquisito circa vent’anni fa (quando neanche esistevano gli smartphone), oggi sono ancora valide e mi permettono di sviluppare app per Android e iPhone. Quindi... mi sento ragionevolmente sicuro che scommettere su Java sia una buona scelta, soprattutto grazie a Codename One, a cui già avevo dedicato un breve articolo di presentazione.
Ciò che andrò a trattare dovrebbe essere sufficiente duraturo nel tempo, al di là delle mode del momento: in effetti è una scommessa, fatta però a ragion veduta. Mi spiego con un esempio pratico: le conoscenze di base di Java che ho acquisito circa vent’anni fa (quando neanche esistevano gli smartphone), oggi sono ancora valide e mi permettono di sviluppare app per Android e iPhone. Quindi... mi sento ragionevolmente sicuro che scommettere su Java sia una buona scelta, soprattutto grazie a Codename One, a cui già avevo dedicato un breve articolo di presentazione.
Tra le conoscenze di base, non ho incluso quella di un linguaggio relazionale per database (tipo MySql), né la conoscenza dei linguaggi specifici normalmente usati per certi dispositivi, ad es. Objective-C o Swift per iPhone. In effetti, potrebbero essere utili, ma solo in circostanze molto specifiche; normalmente non ne avremo bisogno, o meglio, li useremo in maniera indiretta: Java farà tutto per noi, compreso l’uso di MySql o di Objective-C, sgravandoci dal compito di dover sapere “tutto”. A livello cognitivo, Java ci semplifica la vita.
Tutto ciò, lato client, è possibile grazie a Codename One, il cui compito, sostanzialmente, è proprio quello di prendere il nostro codice Java e “transcompilarlo” (cioè tradurlo e riadattarlo) ai vari contesti d’uso. Illustrerò meglio questo concetto in un altro articolo. L’interazione lato server con un database, invece, sarà a carico di Spring Boot, che tradurrà il nostro codice Java nel linguaggio specifico del database da noi scelto (ad es. MySql). Pure questo, un passo alla volta, lo vedremo meglio più avanti.
Un corretto modo di ragionare per affrontare la complessità
 Su questo punto, invito ad un’attenta lettura del mio articolo: “Linee guida di base per la gestione della complessità in un progetto software”. I punti che ho elencato saranno punti di riferimento di cui vedremo applicazioni concrete.
Su questo punto, invito ad un’attenta lettura del mio articolo: “Linee guida di base per la gestione della complessità in un progetto software”. I punti che ho elencato saranno punti di riferimento di cui vedremo applicazioni concrete.
Esempi fallimentari
Dopo aver introdotto quella che secondo me è una buona direzione da intraprendere, per confronto vorrei invece soffermarmi su quelli che considero esempi fallimentari, partendo proprio dalle mie esperienze.
Specializzazione troppo circostanziata
Specializzarsi in una specifica versione di PHP o di un CMS (per quanto riguarda lo sviluppo di siti web), o specializzarsi in una specifica versione di Android Studio o di Xcode per lo sviluppo di app mobili, rischia di rivelarsi controproducente. Senza entrare nei dettagli, quel che ho potuto purtroppo appurare è che un CMS (tipo Joomla) che in un dato anno fa uso di una specifica versione di PHP, a distanza di dieci anni, con l'aggiornamento dei sistemi operativi e di PHP, di fatto si rivela non più utilizzabile, non più manutenibile, e per poter ancora essere tenuto online può richiedere un lavoro abnorme (e non sempre fattibile) di aggiornamento.
A titolo di esempio, ho impiegato mesi di duro lavoro per ammodernare un vecchio sito Joomla 1.5 (che aveva decine di migliaia di utenti registrati e innumerevoli contenuti caricati dagli utenti, nonché plugins specifici di Joomla 1.5 assenti in versioni successive) a Joomla 3.x, riuscendo a trasportare tutti i dati e i plugins su un sito nuovo. E’ stato un lavoro quasi impossibile semplicemente perché non esistevano strumenti idonei per poterlo fare: manualmente, con prove ed errori e tanto intuito, ho fatto il reverse engineering dei database, ne ho compreso la logica sottostante per certi versi criptica, ho scritto un mio software per eseguire la migrazione, ho scritto anche un nuovo plugin per Joomla 3.x per sostituirne uno di Joomla 1.5 di cui non esisteva un equivalente. Queste sono esperienze da non ripetere, difficilissime, stressanti e altamente rischiose.
A suo tempo ho speso cifre considerevoli in manuali di HTML, CSS, PHP, AJAX e affini e oggi potrei tranquillamente buttarli nel camino insieme alla legna perché non servono più a nulla, ormai sono vecchi.
Parimenti, specializzarsi in una specifica versione degli strumenti di sviluppo e dei linguaggi richiesti da Google e da Apple per lo loro piattaforme, ci mette alla mercé delle loro scelte commerciali e tecniche. Tra l'altro, le scelte tecniche di queste corporations a volte creano seri problemi a noi sviluppatori nel passaggio da una versione all'altra, per incompatibilità più o meno volute e altre "breaking changes". Specialmente Google obbliga spesso a cambiamenti tutt’altro che indolori.
In poche parole, stare dietro alle mode tecniche e commerciali del momento può infilarci in un'odissea drammatica.
In questo contesto, Codename One ci mette al riparo da una miriade di problemi e di incompatibilità, permettendoci di focalizzarci solo su Java e facendo in modo che il nostro codice sia il più possibile compatibile nel tempo, sia con i dispositivi più vecchi sia con quelli più aggiornati. Questa semplificazione ci aiuta a concentrarci sull'essenziale, affrancandoci da un bisogno di continuo aggiornamento e di rincorsa delle novità. Parimenti, pure Spring Boot fa la sua parte nell'agevolarci la vita, automatizzando per quanto possibile certi dettagli implementativi e alleggerendoci il lavoro. Ho già citato, ad esempio, che Spring Boot ci permette di usare un database senza scrivere una sola riga di codice Sql: un’altra interessante “figata” è che Spring Boot e Codename One possono tranquillamente scambiarsi dati tramite JSON sgravandoci completamente dal compito di scrivere il codice per generare e interpretare tali files (anzi, nel nostro codice Java la sintassi JSON non comparirà per niente, sarà infatti gestita automaticamente).
Livello di astrazione troppo basso o troppo specialistico
Un altro esempio secondo me fallimentare è l'uso di linguaggi a basso livello di astrazione (come il C o il C++), che non solo creano incompatibilità nel passaggio da un sistema operativo all'altro, ma per la loro vicinanza più alla macchina che al programmatore espongono a problematiche che in linguaggi con livello di astrazione più alto (come Java) non esistono. Per completezza, ci sono personalità importanti, come Linus Torvalds, celeberrimo programmatore e creatore del kernel Linux, che hanno espresso un'opinione diametralmente opposta alla mia. In una recente intervista, Torvalds ha infatti affermato che Java è un linguaggio orribile: in effetti, se fosse utilizzato per sviluppare il kernel Linux, sarebbe veramente poco adatto (anzi, improponibile). Tutto dipende dal contesto d'uso: Java nasce con una vocazione multipiattaforma. Io ho usato molto il C++, ma in confronto Java mi è sembrato una boccata di ossigeno.
In altri ambiti, considero fallimentari, sempre in un'ottica a lungo termine, i linguaggi di scripting tarati per una determinata versione di un certo sistema operativo: ad es., nel corso degli anni sono stato prolifico nel prepararmi script Bash, ma, salvo rare eccezioni, sono stati tutti legati a esigenze del momento e non portabili su altri sistemi operativi o su una versione successiva dello stesso sistema operativo. Oggi più che mai la regola d'ora è la massima inter-compatibilità tra piattaforme diverse: secondo me, in generale, è meglio star lontani da codice troppo circostanziato.
Per la stessa ragione, è meglio avere serie perplessità se un ambiente di sviluppo è intrinsecamente legato a un certo sistema operativo, perché non sappiamo se tra qualche anno avrà ancora mercato. Ad es., qualcuno ricorda i numerosi software didattici e professionali degli anni '90? Forse i più giovani no, magari alcuni di voi non erano ancora nati, ad ogni modo è (quasi) tutto sparito, perché per la stragrande maggioranza erano tutti legati a specifiche versioni di un noto sistema operativo. Lo so che sono passati quasi trent'anni... sto solo facendo ragionamenti a lungo termine, notando come l’andamento del mercato del software può prendere vie a volte non prevedibili. Come dicevo, i concetti base di Java che ho imparato vent'anni fa sono ancora gli stessi che mi permettono oggi di scrivere applicazioni per iPhone e Android. Se tra qualche anno uscirà qualche altro sistema operativo che ancora non esiste, magari Java continuerà ad aiutarmi. Non solo: già attualmente Java + Codename One mi permettono di sviluppare web-app, cioè app basate sugli standard del W3C (in primis HTML5), che di per sé sono indipendenti dal sistema operativo. Anche questo lo vedremo più avanti, ad ogni modo anticipo soltanto che non è necessario conoscere l’HTML5: noi scriveremo codice Java, al resto ci penserà Codename One.
Altri esempi fallimentari che rasentano il masochismo…
Esperienze da non ripetere: siti web statici fatti "a mano" in HTML con il "notepad" di Windows (??!), siti web dinamici con codice scritto a mano con il "nano" editor di Linux e aggiornato direttamente sul server mentre questi sono in esecuzione (???!!!), nonché programmi scritti direttamente in assembly (?!!!). Ho fatto tutte queste cose, ma per un problema di igiene mentale è meglio non persistere. Poi, ovviamente, se qualcuno, per passione personale, vuol provare questo tipo di lavori "artigianali", è libero di sperimentare.
Specializzazione troppo scientifica
Chicca finale: mesi e mesi da me passati a scrivere codice in linguaggio O'Caml. Se siete veramente appassionati di programmazione funzionale e se lo fate per gusto personale (?!) o perché siete dottorandi o ricercatori universitari, allora ha senso, altrimenti... passiamo oltre. Effettivamente ci sono casi d'uso dove saper utilizzare questo tipo di linguaggi può aiutare nella ricerca scientifica e nel formulare ragionamenti e algoritmi formalmente corretti dal punti di vista matematico... ma fuori dalle università e dai centri di ricerca, la realtà lavorativa di noi persone comuni non può avvalersi di quel tipo di strumenti.
Scrivere codice senza prima strutturarlo
La scrittura del codice dovrebbe essere il passo terminale di una catena di progettazione e di ragionamenti, non il contrario :-)
Orbene, tempo permettendo, e con un po’ di ispirazione, continuerò questa trattazione in altri articoli, entrando più nello specifico.
Francesco Galgani,
26 novembre 2019
Amnesty International: Google e Facebook violano pesantemente i diritti umani
 C'è chi tiene in mano un'arma da fuoco, chi una croce, chi un mouse (e, per estensione, tutto ciò che rappresenta un accesso ai contesti virtuali, tra cui soprattutto gli smartphone). Il suggestivo disegno qui a destra, in cui si possono ricercare significati, è di Matt Chase. I nostri dispositivi digitali sono sia un'arma sia una fede? Probabilmente sì. Non faccio ulteriori commenti su questo disegno, su cui invito a riflettere, e passo oltre...
C'è chi tiene in mano un'arma da fuoco, chi una croce, chi un mouse (e, per estensione, tutto ciò che rappresenta un accesso ai contesti virtuali, tra cui soprattutto gli smartphone). Il suggestivo disegno qui a destra, in cui si possono ricercare significati, è di Matt Chase. I nostri dispositivi digitali sono sia un'arma sia una fede? Probabilmente sì. Non faccio ulteriori commenti su questo disegno, su cui invito a riflettere, e passo oltre...
Nel quadro generale della futura "Internet delle cose", o "Internet del tutto", che purtroppo pare attenderci e che ho già trattato nella pagina "Crimine 5G, Internet delle Cose: un quadro ampio, con articoli, video, bibliografia scientifica, appelli di scienziati", in cui ho riportato anche un servizio di Report e un documentario di James Corbett, la notizia che Amnesty International abbia pubblicato un documento di 60 pagine per dimostrare la sistematica violazione dei diritti umani compiuta da Facebook e Google mi sembra l'ennesima conferma della direzione autodistruttiva del mondo in cui siamo inseriti.
L'unica azione rivoluzionaria che intravedo è non usare né Facebook né i servizi di cui questa azienda è proprietaria (Instagram e Whatsapp, giusto per fare due nomi), né Google e i suoi servizi, ammesso che questo sia possibile. Ad ogni modo, sono ben consapevole che le pressioni e i condizionamenti sociali spingono e forzano in tutt'altra direzione.
Esistono altre strade? Sì, ricordo il decalogo slow-Internet di Giulio Ripa, decalogo che continua ad essere una proposta molto sensata di fronte alla denuncie di Amnesty (la quale, peraltro, non manca di essere presente su Facebook).
Questa è la sintesi del report di Amnesty International, pubblicata da Amnesty stessa: "Facebook and Google’s pervasive surveillance poses an unprecedented danger to human rights".
Questo è il documento completo in PDF: POL3014042019ENGLISH.PDF
Questa invece è una lista di tutti gli articoli pubblicati da Amnesty International sul tema del rapporto tra tecnologia e diritti umani: https://www.amnesty.org/en/search/?issue=54748
Francesco Galgani,
25 novembre 2019
Campo di concentramento

Campo di concentramento
Tacere,
sapere di non sapere,
mentre la fine
comincio a vedere.
Silenzio,
senza lamento,
mentre sta per compiersi
il grande fallimento.
Millenni di storia
come polvere al vento,
dalla pioggia di morte
mi riparo a stento.
Violenza su violenza,
incapaci d’amare,
senza un governo
che ci sappia orientare.
I superstiti sapranno
quanto buio è l’umano,
vorrei che un cenno di luce
non fosse troppo lontano.
(Francesco Galgani, 23 novembre 2019, www.galgani.it)
