«La conoscenza è come un fuoco: se non la alimenti condividendola, si spegne». Per questo motivo, condivido questi miei corposi appunti, che ho trasformato in un libro strutturato per agevolare l'apprendimento e la preparazione a colloqui di lavoro.
Per la pubblicazione mi affido al mio blog, anziché ad un libro stampato, perché l'uso di manuali cartacei è sempre più desueto tra noi programmatori, che solitamente cerchiamo e troviamo tutto online. Gli scaffali delle biblioteche e delle librerie sono ormai pieni di libri di informatica costosi, chiusi e impolverati, ma «un libro chiuso è solo carta».
Tieni a mente che questo testo può contenere errori o imprecisioni. Non ho risorse per fare una revisione accurata, che solitamente andrebbe affidata a terzi.
Che tu stia imparando Java per la prima volta, approfondendo la tua conoscenza per progetti avanzati o preparando un colloquio tecnico impegnativo, spero di darti una mano nel tuo studio.
Come risorsa aggiuntiva, può esserti utile "Java e UML - Corrispondenza Semantica tra Diagrammi di Classe e Codice Java".
Francesco Galgani, ultimo aggiornamento 30 dicembre 2024
Nota: La prima versione dei miei appunti su Java risale al 2006, questa versione arriva 18 anni dopo. Ti segnalo anche "Le mie attività di sviluppatore e di didattica del software" e il mio corso "Sviluppare app multipiattaforma con Codename One".
Capitolo 1: Introduzione a Java
1.2 Caratteristiche Fondamentali di Java
1.3 Installazione e Configurazione dell’Ambiente di Sviluppo
Capitolo 2: Fondamenti di Programmazione in Java
2.2 Tipi di Dati Primitivi e Riferimento
Capitolo 3: Programmazione Orientata agli Oggetti
3.5 Classi Astratte e Interfacce
Capitolo 4: Gestione delle Eccezioni
4.1 Introduzione alle Eccezioni
4.3 Creazione di Eccezioni Personalizzate
4.4 Best Practices nella Gestione degli Errori
Capitolo 5: Collezioni e Generics
5.1 Framework delle Collezioni Java
Capitolo 6: Input/Output e Gestione dei File
6.2 Lettura e Scrittura di File
6.3 Serializzazione degli Oggetti
Capitolo 7: Concorrenza e Multithreading
7.4 Classi Avanzate di Concorrenza
Capitolo 8: Programmazione Funzionale in Java
Capitolo 9: Moduli Java e Jigsaw
9.1 Sistema Modulare Introdotto in Java 9
9.2 Creazione e Utilizzo dei Moduli
9.3 Compatibilità e Migrazione
Capitolo 10: Evoluzione da Java 5 a Java 21
10.1 Principali Novità di Ogni Versione
10.3 Miglioramenti delle Prestazioni
Appendice A: Argomenti Avanzati di Java
Capitolo 11: Introduzione a Spring Framework
11.3 Il Contesto dell’Applicazione
Capitolo 12: Spring Boot - Fondamenti
12.2 Creazione di un’Applicazione Spring Boot
12.3 Autoconfigurazione e Starter
Capitolo 13: Sviluppo Web con Spring Boot
Capitolo 14: Persistenza e Accesso ai Dati
14.2 Configurazione del Database
14.3 Transazioni e Gestione delle Transazioni
Capitolo 15: Sicurezza nelle Applicazioni Spring Boot
15.1 Introduzione a Spring Security
15.2 Autenticazione e Autorizzazione
Capitolo 16: Testing delle Applicazioni
16.1 Testing Unitario con JUnit e Mockito
Capitolo 17: Microservizi con Spring Boot
17.1 Architettura a Microservizi
17.3 Comunicazione tra Servizi
Capitolo 18: Evoluzione da Spring Boot 2 a Spring Boot 3
18.2 Migrazione delle Applicazioni
18.3 Supporto per Java 17 e Jakarta EE
Capitolo 19: Deployment e Monitoraggio delle Applicazioni
19.2 Deployment su Cloud e Container
19.3 Monitoraggio con Spring Boot Actuator
Capitolo 20: Preparazione al Colloquio Tecnico
20.3 Esercizi Pratici e Problemi da Risolvere
Appendice B: Argomenti Avanzati Spring
Capitolo 1: Introduzione a Java
1.1 Storia di Java
Origini e sviluppo del linguaggio; motivazioni dietro la sua creazione
Java è un linguaggio di programmazione e una piattaforma software che ha rivoluzionato il mondo dell’informatica sin dalla sua introduzione negli anni ’90. Per comprendere appieno la sua importanza e le ragioni dietro la sua creazione, è fondamentale esplorare le origini del linguaggio, il contesto tecnologico dell’epoca e gli obiettivi che i suoi creatori intendevano raggiungere.
Le origini: Il Progetto Green
All’inizio degli anni ’90, la Sun Microsystems, un’azienda tecnologica americana, avviò un progetto interno noto come “Progetto Green”. Il team, guidato da James Gosling, era composto da ingegneri visionari che miravano a sviluppare una piattaforma per dispositivi elettronici di consumo, come televisori interattivi, elettrodomestici intelligenti e set-top box.
In quel periodo, il panorama tecnologico era caratterizzato da una grande varietà di dispositivi con diverse architetture hardware e sistemi operativi proprietari. Questa eterogeneità rendeva difficile per gli sviluppatori creare software compatibile con più dispositivi senza dover riscrivere il codice per ciascuno di essi.
La necessità di un linguaggio portabile
Per affrontare questa sfida, il team del Progetto Green riconobbe la necessità di un linguaggio di programmazione che fosse:
-
Indipendente dalla piattaforma: Capace di funzionare su qualsiasi dispositivo, indipendentemente dall’hardware o dal sistema operativo.
-
Sicuro e robusto: In grado di prevenire errori comuni e vulnerabilità di sicurezza.
-
Semplice e familiare: Con una sintassi accessibile per gli sviluppatori già abituati a linguaggi come C e C++.
La nascita di Oak
Il risultato iniziale fu un linguaggio chiamato Oak, nome ispirato a una quercia situata fuori dall’ufficio di James Gosling. Oak incorporava molte delle caratteristiche che avrebbero poi definito Java, come l’orientamento agli oggetti e la gestione automatica della memoria attraverso il garbage collector.
Tuttavia, Oak non ebbe il successo sperato nel mercato dei dispositivi elettronici di consumo a causa della lentezza nell’adozione da parte dei produttori e delle limitazioni hardware dell’epoca.
La transizione verso il Web
Con l’esplosione di Internet e del World Wide Web a metà degli anni ’90, il team vide una nuova opportunità. Il web stava diventando una piattaforma universale, ma mancava di interattività e dinamismo. La necessità di un linguaggio che potesse essere eseguito all’interno dei browser web, offrendo funzionalità avanzate senza sacrificare la sicurezza, era evidente.
La rinascita come Java
Nel 1995, Oak fu rinominato Java a causa di problemi di marchio sul nome originale. Il nome “Java” fu scelto in riferimento al caffè Java, riflettendo l’energia e la vitalità che il team voleva infondere nel linguaggio.
Principi fondamentali di Java
Java fu progettato attorno a alcuni principi chiave:
-
Scrivi una volta, esegui ovunque (WORA): Grazie alla Java Virtual Machine (JVM), il codice Java compilato in bytecode poteva essere eseguito su qualsiasi dispositivo dotato di una JVM, eliminando le barriere di compatibilità tra diverse piattaforme.
-
Sicurezza: Con un modello di sicurezza robusto, Java era ideale per eseguire codice proveniente da fonti non attendibili, come applet web, senza rischiare l’integrità del sistema ospite.
-
Orientamento agli oggetti: Favorendo l’incapsulamento, l’ereditarietà e il polimorfismo, Java promuoveva la scrittura di codice modulare e riutilizzabile.
-
Gestione automatica della memoria: L’introduzione del garbage collector alleviava gli sviluppatori dalla gestione manuale della memoria, riducendo il rischio di errori come i memory leak.
L’impatto sul Web e oltre
La capacità di eseguire applet Java all’interno dei browser web portò una nuova dimensione di interattività al Web, sebbene questa funzionalità sia poi caduta in disuso. Più importante fu l’adozione di Java nello sviluppo di applicazioni server-side, grazie alla sua robustezza e scalabilità.
Java divenne rapidamente uno standard de facto per lo sviluppo di applicazioni enterprise, grazie anche all’introduzione di Java 2 Enterprise Edition (J2EE), che forniva un insieme di specifiche per lo sviluppo di applicazioni distribuite e multi-tier.
Evoluzione e comunità
Nel corso degli anni, Java ha subito numerose evoluzioni:
-
Aggiornamenti del linguaggio: Introduzione di nuove funzionalità come le espressioni lambda, gli stream e le API per la programmazione funzionale, mantenendo il linguaggio moderno e competitivo.
-
Ampliamento delle librerie: Arricchimento delle librerie standard per coprire un’ampia gamma di esigenze, dalla manipolazione di dati alla connettività di rete.
-
Comunità e standardizzazione: La Java Community Process (JCP) ha permesso alla comunità di partecipare attivamente allo sviluppo del linguaggio, garantendo che Java evolvesse per soddisfare le reali esigenze degli sviluppatori.
Motivazioni dietro la creazione di Java
Le motivazioni fondamentali che spinsero alla creazione di Java possono essere riassunte nei seguenti punti:
-
Portabilità: Superare le limitazioni imposte dalla varietà di hardware e sistemi operativi, permettendo agli sviluppatori di scrivere codice che potesse funzionare su qualsiasi piattaforma.
-
Sicurezza: Fornire un ambiente di esecuzione che proteggesse sia l’utente che il sistema da codice potenzialmente malevolo.
-
Semplicità e Produttività: Creare un linguaggio che fosse più semplice e meno propenso agli errori rispetto ai suoi predecessori, migliorando la produttività degli sviluppatori.
-
Networking integrato: Facilitare la scrittura di applicazioni distribuite e connesse, in linea con la crescente importanza di Internet.
-
Orientamento agli oggetti: Adottare pienamente il paradigma della programmazione orientata agli oggetti per promuovere il riuso del codice e una migliore organizzazione dei programmi.
Java oggi
Con oltre due decenni di storia, Java rimane uno dei linguaggi di programmazione più utilizzati al mondo. La sua capacità di adattarsi ai cambiamenti tecnologici, pur mantenendo la compatibilità con il codice esistente, ha permesso a Java di rimanere rilevante nell’era moderna, abbracciando settori come il cloud computing, i big data e l’Internet of Things (IoT).
Conclusione
La storia di Java è un esempio di come una visione chiara e orientata al futuro possa portare alla creazione di una tecnologia duratura. Le motivazioni alla base della sua creazione—portabilità, sicurezza, semplicità e orientamento agli oggetti—sono ancora oggi rilevanti e continuano a guidare l’evoluzione del linguaggio. Comprendere questa storia non solo fornisce un apprezzamento per il linguaggio stesso, ma offre anche preziose lezioni su come identificare e risolvere problemi tecnologici complessi attraverso l’innovazione.
1.2 Caratteristiche Fondamentali di Java
Java è un linguaggio di programmazione che ha rivoluzionato il modo in cui sviluppiamo software grazie a una serie di caratteristiche fondamentali. In questa sezione, esamineremo le proprietà chiave che rendono Java una scelta privilegiata per sviluppatori di tutti i livelli: la piattaforma indipendente, la programmazione orientata agli oggetti (OOP), la gestione automatica della memoria e le robuste funzionalità di sicurezza.
1.2.1 Piattaforma Indipendente
Una delle caratteristiche più distintive di Java è la sua indipendenza dalla piattaforma, spesso riassunta nel motto “Write Once, Run Anywhere” (WORA). Questo significa che un programma scritto in Java può essere eseguito su qualsiasi dispositivo dotato di una Java Virtual Machine (JVM) senza necessità di modifiche al codice sorgente.
Come Funziona
-
Compilazione in Bytecode: Quando si compila un programma Java, il codice sorgente viene trasformato in un formato intermedio chiamato bytecode.
-
Esecuzione sulla JVM: Questo bytecode viene eseguito dalla JVM, che funge da intermediario tra il bytecode e il sistema operativo sottostante.
-
Portabilità: Poiché la JVM è disponibile per la maggior parte dei sistemi operativi e delle architetture hardware, il bytecode Java può essere eseguito ovunque senza ricompilazione.
Vantaggi
-
Riduzione dei Costi: Non è necessario mantenere versioni separate del software per piattaforme diverse.
-
Ampia Diffusione: Permette di raggiungere un pubblico più vasto, aumentando l’accessibilità delle applicazioni.
1.2.2 Programmazione Orientata agli Oggetti (OOP)
Java è un linguaggio pienamente orientato agli oggetti, il che significa che concetti come classi, oggetti, ereditarietà e polimorfismo sono fondamentali per il suo utilizzo.
Principi dell’OOP in Java
-
Incapsulamento: Raggruppa dati e metodi che operano su quei dati all’interno di un’unica unità, la classe, proteggendo lo stato interno dall’accesso diretto esterno.
-
Ereditarietà: Permette di creare nuove classi basate su classi esistenti, favorendo il riutilizzo del codice e l’estensibilità.
-
Polimorfismo: Consente agli oggetti di essere trattati come istanze della loro classe base anziché della loro classe effettiva, facilitando l’intercambiabilità e la flessibilità del codice.
-
Astrazione: Permette di definire classi e metodi senza specificare tutti i dettagli implementativi, focalizzandosi su ciò che fa un oggetto piuttosto che su come lo fa.
Perché l’OOP è Importante
-
Manutenibilità: Il codice orientato agli oggetti è più facile da mantenere e aggiornare grazie alla sua struttura modulare.
-
Riutilizzo del Codice: L’ereditarietà e le interfacce permettono di riutilizzare componenti esistenti, riducendo la duplicazione.
-
Affidabilità: L’incapsulamento protegge l’integrità dei dati, riducendo il rischio di errori.
1.2.3 Gestione della Memoria
La gestione automatica della memoria è un’altra caratteristica chiave di Java, resa possibile dal meccanismo di Garbage Collection (GC).
Garbage Collection
-
Allocazione Automatica: Quando si crea un nuovo oggetto, Java alloca automaticamente la memoria necessaria.
-
Deallocazione Automatica: Il Garbage Collector si occupa di liberare la memoria occupata da oggetti che non sono più raggiungibili o utilizzati, prevenendo perdite di memoria (memory leaks).
-
Sicurezza: Elimina la necessità di gestire manualmente la memoria, riducendo il rischio di errori come dangling pointers o buffer overflows.
Vantaggi della Gestione Automatica
-
Produttività: Gli sviluppatori possono concentrarsi sulla logica dell’applicazione senza preoccuparsi della gestione esplicita della memoria.
-
Stabilità: Riduce gli errori legati alla memoria, aumentando l’affidabilità delle applicazioni.
Considerazioni
- Performance: Sebbene il GC migliori la sicurezza e la facilità d’uso, può introdurre overhead. Tuttavia, Java offre strumenti per ottimizzare il comportamento del Garbage Collector in base alle esigenze specifiche.
1.2.4 Sicurezza
Fin dalla sua concezione, Java è stato progettato con un forte focus sulla sicurezza, soprattutto per applicazioni distribuite e in rete.
Meccanismi di Sicurezza
-
Class Loader: Isola le classi provenienti da diverse fonti, prevenendo l’esecuzione di codice non affidabile.
-
Bytecode Verifier: Controlla il bytecode per garantire che rispetti le regole del linguaggio e non comprometta la sicurezza della JVM.
-
Security Manager: Definisce una politica di sicurezza che controlla l’accesso alle risorse sensibili come file system, rete e sistema operativo.
Sicurezza nelle Applicazioni
-
Sandboxing: Le applet e altre applicazioni possono essere eseguite in un ambiente controllato, limitando le operazioni potenzialmente dannose.
-
Crittografia e Autenticazione: Java fornisce API per implementare facilmente meccanismi di crittografia, firma digitale e autenticazione.
Vantaggi
-
Protezione delle Risorse: Impedisce accessi non autorizzati e operazioni malevole.
-
Integrità del Sistema: Mantiene l’affidabilità e la stabilità dell’ambiente di esecuzione.
1.2.5 Altre Caratteristiche Fondamentali
Robustezza
-
Gestione delle Eccezioni: Java incoraggia l’uso di eccezioni per gestire gli errori in modo strutturato, migliorando la robustezza del codice.
-
Tipizzazione Statica: Il controllo dei tipi a tempo di compilazione aiuta a rilevare errori prima dell’esecuzione.
Multithreading
-
Supporto Nativo: Java offre un supporto integrato per la programmazione multithread, permettendo lo sviluppo di applicazioni concorrenti.
-
Sincronizzazione: Fornisce meccanismi per gestire l’accesso concorrente alle risorse condivise, come la parola chiave
synchronized.
Ricca Libreria Standard
-
API Estese: Java include una vasta libreria standard che copre I/O, networking, utilità di data e ora, strutture dati, e molto altro.
-
Estensibilità: Facilita l’integrazione con librerie e framework esterni, ampliando le capacità del linguaggio.
Conclusione
Le caratteristiche fondamentali di Java — indipendenza dalla piattaforma, programmazione orientata agli oggetti, gestione automatica della memoria e solide misure di sicurezza — hanno contribuito alla sua diffusione globale e alla sua longevità nel panorama dello sviluppo software.
Per i nuovi sviluppatori, queste caratteristiche offrono un ambiente accessibile e sicuro per apprendere i concetti chiave della programmazione moderna. Per gli sviluppatori esperti, forniscono strumenti potenti per costruire applicazioni complesse e scalabili.
Comprendere profondamente queste caratteristiche non solo migliorerà le tue competenze tecniche, ma ti preparerà anche ad affrontare sfide avanzate e colloqui tecnici con maggiore sicurezza e competenza.
1.3 Installazione e Configurazione dell’Ambiente di Sviluppo
Per iniziare a programmare efficacemente in Java, è essenziale disporre di un ambiente di sviluppo ben configurato. Questo non solo semplifica il processo di scrittura del codice, ma consente anche di sfruttare appieno le potenzialità offerte dal linguaggio e dagli strumenti associati. In questa sezione, ti guideremo attraverso i passaggi necessari per installare il Java Development Kit (JDK) e configurare un ambiente di sviluppo integrato (IDE) come Eclipse o IntelliJ IDEA.
1.3.1 Installazione del Java Development Kit (JDK)
Il JDK è un insieme di strumenti che consente di sviluppare, compilare ed eseguire applicazioni Java. Include il compilatore Java (javac), l’interprete (java), e altre utility essenziali.
a) Scelta della Versione del JDK
Con l’evoluzione costante di Java, è importante scegliere la versione del JDK più adatta alle tue esigenze:
-
Versioni LTS (Long-Term Support): Come Java 8, 11 e 17, offrono supporto a lungo termine e sono ideali per progetti stabili.
-
Versioni più Recenti: Se vuoi sfruttare le ultime funzionalità introdotte fino a Java 21, puoi optare per l’ultima release disponibile.
b) Download del JDK
-
Oracle JDK: Disponibile sul sito ufficiale di Oracle (oracle.com/java/technologies/downloads).
-
OpenJDK: Versione open-source del JDK, scaricabile da openjdk.java.net.
c) Installazione del JDK
-
Scarica il pacchetto di installazione adatto al tuo sistema operativo (Windows, macOS, Linux).
-
Esegui il programma di installazione:
-
Windows: Segui la procedura guidata, accettando i termini di licenza e scegliendo la directory di installazione.
-
macOS: Apri il file
.dmge trascina l’icona del JDK nella cartella Applicazioni. -
Linux: Estrarre il contenuto del pacchetto e configurare le variabili d’ambiente manualmente.
-
d) Configurazione delle Variabili d’Ambiente
Per assicurarti che il sistema riconosca i comandi Java:
-
JAVA_HOME: Imposta questa variabile d’ambiente al percorso di installazione del JDK.
-
PATH: Aggiungi il percorso
bindel JDK alPATHdel sistema.
Verifica dell’Installazione:
Apri il terminale o il prompt dei comandi e digita:
java -versionDovresti vedere la versione del JDK installato.
1.3.2 Configurazione dell’IDE (Eclipse, IntelliJ IDEA, ecc.)
Un IDE facilita lo sviluppo fornendo strumenti avanzati come l’evidenziazione della sintassi, il completamento automatico, il debugging e la gestione dei progetti.
a) Eclipse
-
Download: Scarica Eclipse IDE for Java Developers da eclipse.org.
-
Installazione:
-
Esegui il file scaricato e segui le istruzioni.
-
Scegli la versione “Eclipse IDE for Java Developers”.
-
-
Configurazione:
-
All’avvio, seleziona la workspace (cartella di lavoro).
-
Verifica che Eclipse riconosca il JDK installato: vai su Window > Preferences > Java > Installed JREs.
-
b) IntelliJ IDEA
-
Versioni Disponibili:
-
Community Edition: Gratuita, adatta per lo sviluppo Java standard.
-
Ultimate Edition: A pagamento, offre funzionalità aggiuntive per lo sviluppo web e enterprise.
-
-
Download: Scarica da jetbrains.com/idea.
-
Installazione:
-
Esegui il programma di installazione e segui le istruzioni.
-
Scegli i componenti aggiuntivi se necessario.
-
-
Configurazione:
-
All’avvio, imposta le preferenze iniziali (tema, plugin).
-
Verifica il JDK: vai su File > Project Structure > SDKs.
-
c) Altri IDE e Editor di Testo
-
NetBeans: netbeans.apache.org
-
Visual Studio Code: Richiede l’estensione “Extension Pack for Java”.
1.3.3 Creazione del Primo Progetto
Per assicurarti che tutto sia configurato correttamente, crea un semplice progetto “Hello, World!”.
a) Con Eclipse
-
Crea un nuovo progetto: File > New > Java Project.
-
Imposta il nome del progetto (es. “HelloWorld”) e seleziona il JDK.
-
Crea una nuova classe: Nella cartella src, clicca con il tasto destro > New > Class.
-
Scrivi il codice:
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello, World!"); } } -
Esegui il programma: Run > Run As > Java Application.
b) Con IntelliJ IDEA
-
Crea un nuovo progetto: File > New > Project > Seleziona “Java”.
-
Imposta il nome e la posizione del progetto.
-
Crea una nuova classe: Nella directory src, clicca con il tasto destro > New > Java Class.
-
Scrivi il codice (come sopra).
-
Esegui il programma: Clicca sull’icona verde accanto al metodo
maino usa Run > Run ‘HelloWorld’.
Se vedi “Hello, World!” nella console, la configurazione è corretta.
1.3.4 Gestione delle Dipendenze con Maven o Gradle
Per progetti più complessi, è consigliabile utilizzare un build tool:
-
Maven: Utilizza un file
pom.xmlper gestire le dipendenze e la configurazione del progetto. -
Gradle: Offre maggiore flessibilità con script
build.gradle.
Gli IDE moderni integrano strumenti per creare e gestire progetti Maven o Gradle, semplificando ulteriormente il processo.
1.3.5 Consigli per l’Ambiente di Sviluppo
-
Aggiornamenti: Mantieni il JDK e l’IDE aggiornati per beneficiare delle ultime funzionalità e correzioni.
-
Plugin e Estensioni: Esplora i plugin disponibili per l’IDE scelto per migliorare la produttività (es. plugin per il controllo di versione, formattazione del codice, integrazione con database).
-
Personalizzazione: Configura temi, scorciatoie da tastiera e layout dell’IDE secondo le tue preferenze per rendere l’ambiente di lavoro più confortevole.
1.3.6 Risoluzione dei Problemi Comuni
-
L’IDE non Riconosce il JDK:
-
Verifica che la versione del JDK sia compatibile con l’IDE.
-
Controlla le impostazioni dell’IDE per assicurarti che il percorso del JDK sia corretto.
-
-
Errori di Compilazione:
-
Assicurati che la sintassi del codice sia corretta.
-
Verifica che tutte le librerie e le dipendenze siano incluse nel progetto.
-
-
Problemi con le Variabili d’Ambiente:
-
Controlla che
JAVA_HOMEePATHsiano impostati correttamente. -
Riavvia il terminale o l’IDE dopo aver modificato le variabili d’ambiente.
-
Conclusione
Una corretta installazione e configurazione dell’ambiente di sviluppo è il primo passo fondamentale per diventare produttivi in Java. Prendendoti il tempo necessario per impostare tutto accuratamente, eviterai problemi futuri e potrai concentrarti sull’apprendimento dei concetti e sulla scrittura di codice di qualità. Ora che l’ambiente è pronto, sei pronto per immergerti nei fondamenti della programmazione in Java e avanzare verso lo sviluppo di applicazioni complesse e performanti.
Capitolo 2: Fondamenti di Programmazione in Java
2.1 Sintassi di Base
La sintassi di Java è stata progettata per essere semplice, leggibile e vicina al linguaggio naturale, rendendo il codice più intuitivo per gli sviluppatori. In questa sezione, esploreremo la struttura fondamentale di un programma Java, comprendendo come le classi, i metodi e i pacchetti si combinano per creare applicazioni robuste e manutenibili.
Struttura di un Programma Java
Un programma Java è costituito da una o più classi, ognuna delle quali può contenere metodi e variabili. Il punto di ingresso di ogni applicazione Java è il metodo main, che ha una firma specifica riconosciuta dalla Java Virtual Machine (JVM):
public static void main(String[] args) {
// Corpo del metodo
}Questa firma è essenziale perché indica alla JVM dove iniziare l’esecuzione del programma.
Esempio di un Programma Semplice
Ecco un esempio di un semplice programma Java che stampa “Ciao, Mondo!” sulla console:
public class CiaoMondo {
public static void main(String[] args) {
System.out.println("Ciao, Mondo!");
}
}Analisi del Codice:
-
public class CiaoMondo: Definisce una classe pubblica chiamataCiaoMondo. In Java, ogni codice deve essere racchiuso all’interno di una classe. -
public static void main(String[] args): Definisce il metodomain, il punto di ingresso dell’applicazione.-
public: Indica che il metodo è accessibile da qualsiasi altra classe. -
static: Significa che il metodo appartiene alla classe piuttosto che a un’istanza specifica. -
void: Indica che il metodo non restituisce alcun valore. -
String[] args: Argomento che rappresenta un array di stringhe, utilizzato per passare parametri da linea di comando.
-
-
System.out.println("Ciao, Mondo!");: Stampa la stringa “Ciao, Mondo!” sulla console.
Classi in Java
Una classe è una blueprint o un modello da cui vengono create le istanze (oggetti). Definisce attributi (variabili) e comportamenti (metodi) che l’oggetto avrà.
Sintassi Generale di una Classe:
[modificatore_di_accesso] class NomeClasse {
// Variabili di istanza (attributi)
// Costruttori
// Metodi
}Esempio:
public class Persona {
// Attributi
private String nome;
private int eta;
// Costruttore
public Persona(String nome, int eta) {
this.nome = nome;
this.eta = eta;
}
// Metodo
public void saluta() {
System.out.println("Ciao, mi chiamo " + nome + " e ho " + eta + " anni.");
}
}Spiegazione:
-
Attributi:
nomeedetasono variabili che contengono lo stato dell’oggettoPersona. -
Costruttore: Metodo speciale utilizzato per creare nuove istanze della classe.
-
Metodi:
saluta()è un metodo che definisce un comportamento dell’oggetto.
Metodi in Java
I metodi sono blocchi di codice che eseguono azioni specifiche e possono restituire un valore.
Sintassi Generale di un Metodo:
[modificatore_di_accesso] [modificatore_opzionale] tipo_di_ritorno nomeMetodo(parametri) {
// Corpo del metodo
}Esempio di Metodo:
public void saluta() {
System.out.println("Ciao!");
}-
public: Modificatore di accesso che rende il metodo accessibile da altre classi. -
void: Il metodo non restituisce alcun valore. -
saluta: Nome del metodo. -
(): Parentesi che possono contenere parametri.
Pacchetti in Java
I pacchetti sono utilizzati per organizzare le classi in una struttura gerarchica e per evitare conflitti di nomi tra classi.
Dichiarazione di un Pacchetto:
La prima riga del file sorgente deve dichiarare il pacchetto:
package com.nomeazienda.progetto.modulo;Esempio:
package com.esempio.app;
public class Main {
// Contenuto della classe
}Importazione di Classi da Altri Pacchetti:
Per utilizzare classi da altri pacchetti, si usa la parola chiave import:
import com.esempio.utilita.Util;
public class Main {
// Utilizza la classe Util
}Modificatori di Accesso
I modificatori di accesso determinano la visibilità di classi, metodi e variabili.
-
public: Accessibile da qualsiasi altra classe. -
protected: Accessibile all’interno dello stesso pacchetto e dalle sottoclassi. -
private: Accessibile solo all’interno della classe in cui è dichiarato. -
Default (nessun modificatore): Accessibile solo all’interno dello stesso pacchetto.
Esempio Completo
Classe Persona:
package com.esempio.modello;
public class Persona {
private String nome;
private int eta;
public Persona(String nome, int eta) {
this.nome = nome;
this.eta = eta;
}
public void saluta() {
System.out.println("Ciao, mi chiamo " + nome + " e ho " + eta + " anni.");
}
}Classe Main:
package com.esempio.app;
import com.esempio.modello.Persona;
public class Main {
public static void main(String[] args) {
Persona persona = new Persona("Luca", 25);
persona.saluta();
}
}Spiegazione:
-
Organizzazione in Pacchetti: La classe
Personasi trova nel pacchettocom.esempio.modello, mentreMainè incom.esempio.app. -
Importazione:
MainimportaPersonaper poterla utilizzare. -
Istanziazione: Nel metodo
main, viene creata un’istanza diPersonae viene chiamato il metodosaluta().
Commenti in Java
I commenti sono usati per spiegare il codice e non vengono eseguiti dalla JVM.
-
Commento su Singola Linea:
// Questo è un commento su una singola linea -
Commento Multilinea:
/* * Questo è un commento * su più linee */ -
Commenti Javadoc:
Utilizzati per generare documentazione API.
/** * Metodo che esegue un saluto. * @param nome Il nome della persona da salutare. */ public void saluta(String nome) { System.out.println("Ciao, " + nome + "!"); }
Parole Chiave Importanti
-
class: Definisce una classe. -
public,private,protected: Modificatori di accesso. -
static: Indica che un membro appartiene alla classe, non all’istanza. -
void: Indica che un metodo non restituisce alcun valore. -
new: Utilizzato per creare nuove istanze di una classe. -
this: Riferimento all’istanza corrente dell’oggetto.
Convenzioni di Nomenclatura
-
Classi: Iniziano con lettera maiuscola e usano il CamelCase (es.
Persona,CalcolatriceSemplice). -
Metodi e Variabili: Iniziano con lettera minuscola e usano il CamelCase (es.
calcolaSomma,numeroConto). -
Costanti: Tutte maiuscole con parole separate da underscore (es.
MAX_VALORE,PI_GRECO).
Esercizio Pratico
Obiettivo: Creare una classe Calcolatrice con metodi per le operazioni aritmetiche di base e testarla in una classe Main.
Soluzione:
Classe Calcolatrice:
package com.esempio.utilita;
public class Calcolatrice {
public int somma(int a, int b) {
return a + b;
}
public int sottrai(int a, int b) {
return a - b;
}
public int moltiplica(int a, int b) {
return a * b;
}
public double dividi(int a, int b) {
if (b != 0) {
return (double) a / b;
} else {
System.out.println("Errore: Divisione per zero.");
return 0;
}
}
}Classe Main:
package com.esempio.app;
import com.esempio.utilita.Calcolatrice;
public class Main {
public static void main(String[] args) {
Calcolatrice calc = new Calcolatrice();
int a = 20;
int b = 10;
System.out.println("Somma: " + calc.somma(a, b));
System.out.println("Sottrazione: " + calc.sottrai(a, b));
System.out.println("Moltiplicazione: " + calc.moltiplica(a, b));
System.out.println("Divisione: " + calc.dividi(a, b));
}
}Risultato Atteso:
Somma: 30
Sottrazione: 10
Moltiplicazione: 200
Divisione: 2.0
Importanza dei Modificatori di Accesso
L’uso appropriato dei modificatori di accesso è cruciale per:
-
Incapsulamento: Nascondere i dettagli interni della classe e proteggere l’integrità dei dati.
-
Manutenibilità: Permettere modifiche interne senza influenzare il codice esterno.
-
Sicurezza: Prevenire accessi non autorizzati o modifiche indesiderate.
Best Practices
-
Scrivere Codice Pulito e Leggibile: Seguire le convenzioni di stile e di nomenclatura.
-
Commentare il Codice: Aggiungere commenti significativi per spiegare parti complesse.
-
Organizzare il Codice in Pacchetti: Facilitare la gestione e la scalabilità del progetto.
-
Utilizzare Modificatori di Accesso Appropriati: Proteggere i dati e i metodi sensibili.
Riflessioni Finali
Comprendere la sintassi di base di Java è il primo passo per diventare uno sviluppatore Java competente. La familiarità con la struttura delle classi, dei metodi e dei pacchetti permette di scrivere codice efficace e di qualità. Man mano che si avanza nello studio, questi concetti fondamentali saranno la base su cui costruire competenze più avanzate.
Domande di Autovalutazione:
-
Qual è la funzione del metodo
mainin un programma Java? -
Come si definisce una classe in Java e quali elementi può contenere?
-
Qual è la differenza tra i modificatori di accesso
public,privateeprotected? -
Perché è importante organizzare le classi in pacchetti?
-
Come si utilizza il commento Javadoc e a cosa serve?
Risposte:
-
Il metodo
mainè il punto di ingresso dell’applicazione; la JVM inizia l’esecuzione da questo metodo. -
Una classe si definisce usando la parola chiave
classe può contenere attributi, metodi e costruttori. -
publicrende l’elemento accessibile da qualsiasi classe,privatesolo all’interno della classe stessa,protectedall’interno del pacchetto e dalle sottoclassi. -
I pacchetti aiutano a organizzare le classi in modo logico, evitare conflitti di nomi e gestire la visibilità.
-
Il commento Javadoc viene utilizzato per generare automaticamente la documentazione dell’API e si scrive utilizzando
/** ... */.
2.2 Tipi di Dati Primitivi e Riferimento
La comprensione dei tipi di dati è fondamentale in Java, poiché il linguaggio è fortemente tipizzato. Questo significa che ogni variabile deve essere dichiarata con un tipo specifico prima di poter essere utilizzata. I tipi di dati in Java si dividono in due categorie principali: tipi primitivi e tipi di riferimento. Questa distinzione è cruciale sia per la gestione della memoria che per la manipolazione dei dati all’interno di un programma.
Tipi di Dati Primitivi
I tipi primitivi rappresentano i dati più basilari che il linguaggio può gestire. Sono predefiniti in Java e non derivano da altre classi. Esistono otto tipi primitivi, suddivisi in quattro categorie:
-
Numeri Interi
-
byte: occupa 8 bit (1 byte). Valori da -128 a 127.
-
short: occupa 16 bit (2 byte). Valori da -32,768 a 32,767.
-
int: occupa 32 bit (4 byte). Valori da -2^31 a 2^31 - 1.
-
long: occupa 64 bit (8 byte). Valori da -2^63 a 2^63 - 1.
Esempio:
byte eta = 25; int popolazione = 1400000000; long distanzaStelle = 9460730472580800L; // Nota il suffisso 'L' per indicare un long -
-
Numeri in Virgola Mobile
-
float: occupa 32 bit. Precisione singola.
-
double: occupa 64 bit. Precisione doppia.
Esempio:
float piGrecoApprossimato = 3.14f; // Il suffisso 'f' indica un float double piGreco = 3.141592653589793;Nota: Per default, i numeri decimali sono considerati
double. È necessario il suffisso ‘f’ o ‘F’ per specificare unfloat. -
-
Caratteri
- char: occupa 16 bit. Rappresenta un singolo carattere Unicode.
Esempio:
char iniziale = 'A'; char simboloUnicode = '\u00A9'; // Rappresenta il simbolo © -
Booleani
- boolean: può assumere solo due valori:
trueofalse.
Esempio:
boolean isJavaFacile = true; boolean isWeekend = false; - boolean: può assumere solo due valori:
Tipi di Riferimento
I tipi di riferimento si riferiscono ad oggetti o array. A differenza dei tipi primitivi, i tipi di riferimento puntano a una posizione in memoria dove sono memorizzati i dati reali.
Stringhe
Le stringhe in Java sono oggetti della classe String. Anche se spesso trattate come tipi primitivi per la loro facilità d’uso, le stringhe sono effettivamente tipi di riferimento.
Esempio:
String saluto = "Ciao, Mondo!";Caratteristiche delle Stringhe:
-
Immutabilità: Una volta creata, una stringa non può essere modificata. Ogni operazione che sembra modificare una stringa in realtà ne crea una nuova.
Esempio:
String originale = "Java"; String modificata = originale.concat(" Programming"); // 'originale' rimane "Java", 'modificata' è "Java Programming" -
Pool di Stringhe: Per ottimizzare l’uso della memoria, Java mantiene un pool di stringhe immutabili.
Array
Gli array sono strutture di dati che contengono elementi dello stesso tipo. In Java, gli array sono oggetti, quindi sono tipi di riferimento.
Esempio di array di interi:
int[] numeri = new int[5]; // Array di 5 elementi inizializzati a 0
int[] valori = {1, 2, 3, 4, 5}; // Array inizializzato con valori specificiCaratteristiche degli Array:
-
Lunghezza Fissa: Una volta creato, un array ha una dimensione fissa che non può essere modificata.
-
Accesso Tramite Indice: Gli elementi dell’array sono accessibili tramite indice, partendo da zero.
Esempio di accesso:
int primoNumero = valori[0]; // Ottiene il valore '1'
valori[2] = 10; // Imposta il terzo elemento a '10'Differenze Chiave tra Tipi Primitivi e Riferimento
-
Memorizzazione in Memoria:
-
Tipi Primitivi: Memorizzano direttamente il valore nella variabile.
-
Tipi di Riferimento: Memorizzano un riferimento (indirizzo di memoria) all’oggetto effettivo.
-
-
Valori di Default:
-
Tipi Primitivi: Hanno valori di default (ad esempio,
0per numeri,falseper booleani) quando dichiarati come variabili di istanza. -
Tipi di Riferimento: Il valore di default è
null, indicando che non puntano ad alcun oggetto.
-
-
Comparazione:
-
Tipi Primitivi: Possono essere confrontati utilizzando l’operatore
==, che confronta i valori effettivi. -
Tipi di Riferimento: L’operatore
==confronta i riferimenti, non il contenuto. Per confrontare il contenuto, si usa il metodoequals().
Esempio:
int a = 5; int b = 5; System.out.println(a == b); // Output: true String s1 = new String("Test"); String s2 = new String("Test"); System.out.println(s1 == s2); // Output: false (diversi riferimenti) System.out.println(s1.equals(s2)); // Output: true (contenuto uguale) -
Autoboxing e Unboxing
Java fornisce classi wrapper per ogni tipo primitivo (Integer per int, Double per double, ecc.). Queste classi permettono di trattare i tipi primitivi come oggetti.
-
Autoboxing: Conversione automatica da tipo primitivo a oggetto wrapper.
-
Unboxing: Conversione automatica da oggetto wrapper a tipo primitivo.
Esempio:
Integer numeroObj = 10; // Autoboxing da 'int' a 'Integer'
int numeroPrim = numeroObj; // Unboxing da 'Integer' a 'int'Quando Utilizzare le Classi Wrapper:
-
Necessarie quando si utilizzano collezioni generiche (
List,Map, ecc.) che non accettano tipi primitivi. -
Forniscono metodi utili per operazioni aggiuntive, come la conversione tra basi numeriche.
Stringhe e la loro Gestione
Le stringhe sono ampiamente utilizzate in Java e offrono diverse peculiarità:
-
Immutabilità: Come già menzionato, le stringhe non possono essere modificate dopo la creazione. Questo comportamento assicura thread-safety e consente l’uso efficiente della memoria tramite il pool di stringhe.
-
Manipolazione di Stringhe:
Per manipolare stringhe in modo efficiente, specialmente all’interno di cicli o quando si effettuano numerose concatenazioni, è consigliabile utilizzare
StringBuilderoStringBuffer.-
StringBuilder: Non è thread-safe, ma offre migliori prestazioni.
-
StringBuffer: Thread-safe, ma leggermente meno efficiente a causa della sincronizzazione.
Esempio con StringBuilder:
StringBuilder sb = new StringBuilder(); sb.append("Ciao"); sb.append(", "); sb.append("Mondo!"); String risultato = sb.toString(); // "Ciao, Mondo!" -
Array Multidimensionali
Java supporta anche array multidimensionali, che sono array di array.
Esempio di array bidimensionale:
int[][] matrice = new int[3][3]; // Matrice 3x3
matrice[0][0] = 1;
matrice[1][1] = 5;Accesso e Iterazione:
for (int i = 0; i < matrice.length; i++) {
for (int j = 0; j < matrice[i].length; j++) {
System.out.print(matrice[i][j] + " ");
}
System.out.println();
}Best Practices
-
Scelta del Tipo Adeguato: Utilizzare il tipo più appropriato in base alle esigenze di memoria e precisione.
Esempio: Se si sa che un numero intero non supererà il valore 100, potrebbe essere sufficiente un
byte. -
Inizializzazione delle Variabili: Sempre inizializzare le variabili per evitare comportamenti imprevedibili.
-
Uso dei Wrapper con Attenzione: Evitare l’uso non necessario delle classi wrapper per prevenire overhead di memoria.
-
Comparazione Corretta: Utilizzare
equals()per confrontare il contenuto degli oggetti di riferimento, non==.
Conclusione
La padronanza dei tipi di dati primitivi e di riferimento è essenziale per qualsiasi sviluppatore Java. Una comprensione approfondita non solo aiuta a scrivere codice più efficiente e meno soggetto a errori, ma è anche fondamentale per affrontare con successo colloqui tecnici e risolvere problemi complessi.
Ricapitolando:
-
Tipi Primitivi: Rappresentano i dati fondamentali e memorizzano i valori direttamente.
-
Tipi di Riferimento: Rappresentano oggetti e array, memorizzando riferimenti in memoria.
-
Stringhe: Sono oggetti immutabili che richiedono attenzione particolare nella manipolazione.
-
Array: Permettono di gestire collezioni di dati in modo strutturato.
Con queste conoscenze, sei pronto a esplorare ulteriormente il mondo di Java, costruendo applicazioni robuste e performanti.
2.3 Operatori e Espressioni
Gli operatori e le espressioni sono elementi fondamentali in Java che consentono di manipolare dati, effettuare calcoli, prendere decisioni logiche e controllare il flusso di esecuzione del programma. Comprendere come funzionano gli operatori e come costruire espressioni efficaci è essenziale sia per i principianti che per gli sviluppatori esperti che desiderano rafforzare le proprie competenze.
2.3.1 Operatori Aritmetici
Gli operatori aritmetici eseguono operazioni matematiche di base su tipi numerici primitivi come int, float, double, ecc.
-
Addizione (
+): Somma di due operandi. -
Sottrazione (
-): Differenza tra due operandi. -
Moltiplicazione (
*): Prodotto di due operandi. -
Divisione (
/): Quoziente della divisione del primo operando per il secondo. -
Modulo (
%): Resto della divisione del primo operando per il secondo. -
Incremento (
++): Aumenta il valore dell’operando di 1. -
Decremento (
--): Diminuisce il valore dell’operando di 1.
Esempio:
int a = 10;
int b = 3;
int somma = a + b; // 13
int differenza = a - b; // 7
int prodotto = a * b; // 30
int quoziente = a / b; // 3
int resto = a % b; // 1
a++; // a diventa 11
b--; // b diventa 2Nota: La divisione tra interi restituisce un intero, troncando la parte decimale. Per ottenere un risultato in virgola mobile, almeno uno degli operandi deve essere di tipo double o float.
2.3.2 Operatori Relazionali
Gli operatori relazionali confrontano due operandi e restituiscono un valore booleano (true o false).
-
Uguale a (
==): Verifica se i due operandi sono uguali. -
Diverso da (
!=): Verifica se i due operandi sono diversi. -
Maggiore di (
>): Verifica se il primo operando è maggiore del secondo. -
Minore di (
<): Verifica se il primo operando è minore del secondo. -
Maggiore o uguale a (
>=): Verifica se il primo operando è maggiore o uguale al secondo. -
Minore o uguale a (
<=): Verifica se il primo operando è minore o uguale al secondo.
Esempio:
int x = 5;
int y = 10;
boolean risultato1 = x == y; // false
boolean risultato2 = x != y; // true
boolean risultato3 = x < y; // trueQuesti operatori sono essenziali nelle strutture di controllo come if, for e while per determinare il flusso del programma.
2.3.3 Operatori Logici
Gli operatori logici vengono utilizzati per combinare più espressioni booleane.
-
AND Logico (
&&): Restituiscetruese entrambe le espressioni sonotrue. -
OR Logico (
||): Restituiscetruese almeno una delle espressioni ètrue. -
NOT Logico (
!): Inverte il valore logico dell’espressione.
Esempio:
boolean a = true;
boolean b = false;
boolean risultato1 = a && b; // false
boolean risultato2 = a || b; // true
boolean risultato3 = !a; // falseCortocircuito: In Java, gli operatori && e || sono a cortocircuito, il che significa che l’espressione viene valutata da sinistra a destra e si interrompe non appena il risultato è determinato.
Esempio di cortocircuito:
int divisor = 0;
if (divisor != 0 && (10 / divisor) > 1) {
// Questa condizione evita l'eccezione di divisione per zero
}2.3.4 Operatori Bitwise
Gli operatori bitwise operano sui bit dei numeri interi.
-
AND Bitwise (
&): Esegue l’AND bit a bit. -
OR Bitwise (
|): Esegue l’OR bit a bit. -
XOR Bitwise (
^): Esegue l’XOR bit a bit. -
NOT Bitwise (
~): Inverte tutti i bit. -
Shift a Sinistra (
<<): Sposta i bit a sinistra, aggiungendo zeri a destra. -
Shift a Destra con Segno (
>>): Sposta i bit a destra, mantenendo il bit di segno. -
Shift a Destra senza Segno (
>>>): Sposta i bit a destra, inserendo zeri a sinistra.
Esempio:
int a = 5; // 00000101 in binario
int b = 3; // 00000011 in binario
int risultatoAnd = a & b; // 1 (00000001)
int risultatoOr = a | b; // 7 (00000111)
int risultatoXor = a ^ b; // 6 (00000110)
int risultatoNot = ~a; // -6 (11111010 in complemento a due)
int shiftSinistra = a << 1; // 10 (00001010)
int shiftDestra = a >> 1; // 2 (00000010)Questi operatori sono utili in situazioni che richiedono manipolazioni a basso livello dei dati, come la programmazione di sistemi embedded o algoritmi crittografici.
2.3.5 Operatori di Assegnazione
Gli operatori di assegnazione vengono utilizzati per assegnare valori alle variabili.
-
Assegnazione Semplice (
=): Assegna il valore dell’espressione alla variabile. -
Assegnazioni Compatte:
-
Addizione Assegnazione (
+=):a += bequivale aa = a + b. -
Sottrazione Assegnazione (
-=):a -= bequivale aa = a - b. -
Moltiplicazione Assegnazione (
*=):a *= bequivale aa = a * b. -
Divisione Assegnazione (
/=):a /= bequivale aa = a / b. -
Modulo Assegnazione (
%=):a %= bequivale aa = a % b.
-
Esempio:
int x = 10;
x += 5; // x diventa 15
x *= 2; // x diventa 302.3.6 Operatore Ternario
L’operatore ternario è una forma abbreviata dell’istruzione if-else che restituisce un valore in base a una condizione.
- Sintassi:
condizione ? espressione1 : espressione2
Esempio:
int a = 10;
int b = 20;
int max = (a > b) ? a : b; // max sarà 20Questo operatore è utile per assegnazioni condizionali semplici, ma un uso eccessivo può rendere il codice meno leggibile.
2.3.7 Precedenza e Associatività degli Operatori
La precedenza degli operatori determina l’ordine in cui le parti di un’espressione vengono valutate. Gli operatori con precedenza più alta vengono valutati prima.
Ordine di Precedenza (dal più alto al più basso):
-
Post-incremento e Post-decremento:
expr++,expr-- -
Pre-incremento e Pre-decremento, Positivo e Negativo:
++expr,--expr,+expr,-expr,!,~ -
Moltiplicazione, Divisione, Modulo:
*,/,% -
Addizione e Sottrazione:
+,- -
Shift:
<<,>>,>>> -
Relazionali:
<,>,<=,>=,instanceof -
Uguaglianza:
==,!= -
AND Bitwise:
& -
XOR Bitwise:
^ -
OR Bitwise:
| -
AND Logico:
&& -
OR Logico:
|| -
Operatore Ternario:
? : -
Assegnamento:
=,+=,-=, ecc.
Esempio di Precedenza:
int risultato = 10 + 5 * 2; // risultato è 20, non 30Per modificare l’ordine di valutazione, si possono usare le parentesi:
int risultato = (10 + 5) * 2; // risultato è 302.3.8 Espressioni
Un’espressione è una combinazione di operandi (variabili, valori letterali, metodi) e operatori che vengono valutati per produrre un valore.
Esempi:
-
Aritmetica:
int c = a + b * 2; -
Logica:
boolean isAdult = age >= 18; -
Metodi:
int length = str.length();
Le espressioni possono essere utilizzate ovunque sia necessario un valore, come assegnazioni, condizioni o argomenti di metodi.
2.3.9 Conversione di Tipi (Casting)
La conversione di tipi consente di trasformare un valore da un tipo di dato a un altro.
-
Conversione Automatica (Widening Conversion): Avviene quando si assegna un tipo più piccolo a uno più grande.
Esempio:
int i = 100; long l = i; // Conversione automatica da int a long -
Conversione Esplicita (Narrowing Conversion): Necessita di casting esplicito quando si assegna un tipo più grande a uno più piccolo.
Esempio:
double d = 9.99; int i = (int) d; // i diventa 9, parte decimale persa
Attenzione: Le conversioni esplicite possono causare perdita di dati o precisione. È importante utilizzarle con cautela.
2.3.10 Best Practices
-
Utilizzare Parentesi per Chiarezza: Anche se non strettamente necessario, le parentesi migliorano la leggibilità.
int risultato = a + (b * c); -
Evitare Side Effects Inattesi: Evitare di combinare incrementi/decrementi con altre operazioni complesse.
int total = count++ + ++index; // Può essere confuso, meglio separare -
Comprendere il Cortocircuito: Sfruttare il comportamento a cortocircuito per scrivere codice più sicuro ed efficiente.
if (obj != null && obj.isValid()) { // Sicuro chiamare isValid() solo se obj non è null } -
Attenzione alle Conversioni di Tipi: Essere consapevoli delle implicazioni delle conversioni, specialmente nelle operazioni aritmetiche.
-
Evitare l’Overloading dell’Operatore
+con Stringhe: Quando si concatenano stringhe in un ciclo, utilizzareStringBuilderper migliorare le prestazioni.StringBuilder sb = new StringBuilder(); for (String s : lista) { sb.append(s); } String risultato = sb.toString();
Conclusione
La padronanza degli operatori e delle espressioni è essenziale per scrivere codice Java efficace e robusto. Una comprensione approfondita di come funzionano gli operatori, combinata con le best practices, permette di evitare errori comuni e di scrivere codice che è sia efficiente che leggibile. Questo non solo facilita il processo di sviluppo, ma è anche fondamentale durante le fasi di debugging e manutenzione del codice.
2.4 Controllo di Flusso
Il controllo di flusso è un concetto fondamentale in qualsiasi linguaggio di programmazione, incluso Java. Esso consente al programma di prendere decisioni e di eseguire blocchi di codice multipli in base a determinate condizioni. In Java, le principali strutture di controllo di flusso sono le condizioni (if, switch) e i cicli (for, while, do-while). Comprendere come e quando utilizzare queste strutture è essenziale per scrivere codice efficiente e leggibile.
2.4.1 Condizioni
2.4.1.1 L’istruzione if
L’istruzione if consente al programma di eseguire un blocco di codice solo se una determinata condizione è vera.
Sintassi:
if (condizione) {
// Blocco di codice eseguito se la condizione è vera
}Esempio:
int numero = 10;
if (numero > 0) {
System.out.println("Il numero è positivo.");
}In questo esempio, il messaggio verrà stampato solo se numero è maggiore di zero.
2.4.1.2 L’istruzione if-else
L’istruzione if-else permette di definire un blocco di codice alternativo da eseguire se la condizione è falsa.
Sintassi:
if (condizione) {
// Blocco eseguito se la condizione è vera
} else {
// Blocco eseguito se la condizione è falsa
}Esempio:
int numero = -5;
if (numero >= 0) {
System.out.println("Il numero è positivo.");
} else {
System.out.println("Il numero è negativo.");
}2.4.1.3 L’istruzione if-else if-else
Per verificare più condizioni in sequenza, si utilizzano le istruzioni else if.
Sintassi:
if (condizione1) {
// Blocco eseguito se condizione1 è vera
} else if (condizione2) {
// Blocco eseguito se condizione2 è vera
} else {
// Blocco eseguito se tutte le condizioni precedenti sono false
}Esempio:
int voto = 85;
if (voto >= 90) {
System.out.println("Ottimo");
} else if (voto >= 75) {
System.out.println("Buono");
} else if (voto >= 60) {
System.out.println("Sufficiente");
} else {
System.out.println("Insufficiente");
}2.4.1.4 L’istruzione switch
L’istruzione switch è utilizzata quando si ha bisogno di confrontare una variabile con molteplici valori possibili.
Sintassi:
switch (espressione) {
case valore1:
// Blocco di codice per valore1
break;
case valore2:
// Blocco di codice per valore2
break;
// ...
default:
// Blocco di codice se nessun caso corrisponde
}Esempio:
int giorno = 3;
switch (giorno) {
case 1:
System.out.println("Lunedì");
break;
case 2:
System.out.println("Martedì");
break;
case 3:
System.out.println("Mercoledì");
break;
// ...
default:
System.out.println("Giorno non valido");
}Nota: A partire da Java 14, è possibile utilizzare l’espressione switch migliorata, che consente una sintassi più concisa e sicura.
Esempio con sintassi migliorata:
int mese = 8;
String stagione = switch (mese) {
case 12, 1, 2 -> "Inverno";
case 3, 4, 5 -> "Primavera";
case 6, 7, 8 -> "Estate";
case 9, 10, 11 -> "Autunno";
default -> "Mese non valido";
};
System.out.println("La stagione è: " + stagione);2.4.2 Cicli
I cicli permettono di eseguire ripetutamente un blocco di codice finché una determinata condizione è vera. In Java, i cicli principali sono for, while e do-while.
2.4.2.1 Il ciclo for
Il ciclo for è utilizzato quando si conosce a priori il numero di iterazioni da eseguire.
Sintassi:
for (inizializzazione; condizione; aggiornamento) {
// Blocco di codice da eseguire
}Esempio:
for (int i = 0; i < 5; i++) {
System.out.println("Iterazione: " + i);
}In questo esempio, il ciclo stamperà i numeri da 0 a 4.
2.4.2.2 Il ciclo while
Il ciclo while esegue un blocco di codice finché la condizione specificata rimane vera. È utilizzato quando il numero di iterazioni non è noto a priori.
Sintassi:
while (condizione) {
// Blocco di codice da eseguire
}Esempio:
int count = 0;
while (count < 5) {
System.out.println("Contatore: " + count);
count++;
}2.4.2.3 Il ciclo do-while
Il ciclo do-while è simile al while, ma garantisce che il blocco di codice venga eseguito almeno una volta, poiché la condizione viene verificata alla fine di ogni iterazione.
Sintassi:
do {
// Blocco di codice da eseguire
} while (condizione);Esempio:
int numero;
do {
numero = ottenereInputUtente();
} while (numero <= 0);In questo esempio, la funzione ottenereInputUtente() verrà chiamata almeno una volta e continuerà a essere chiamata finché l’utente non inserisce un numero positivo.
2.4.3 Considerazioni e Best Practices
-
Chiarezza del Codice: Utilizza nomi di variabili significativi e struttura il codice in modo leggibile. Evita annidamenti profondi di condizioni e cicli, poiché possono rendere il codice difficile da seguire.
-
Evitare Condizioni Ridondanti: Verifica se le condizioni possono essere semplificate per migliorare l’efficienza e la leggibilità.
-
Uso Appropriato dei Cicli: Scegli il tipo di ciclo più adatto alla situazione. Se conosci il numero di iterazioni, preferisci il ciclo
for. Se le iterazioni dipendono da una condizione, utilizzawhileodo-while. -
Gestione delle Eccezioni nei Cicli: Presta attenzione alle possibili eccezioni che possono essere generate all’interno dei cicli e gestiscile adeguatamente per evitare comportamenti indesiderati.
-
Evitare Cicli Infinito: Assicurati che le condizioni dei cicli permettano l’uscita dal ciclo per evitare loop infinito che possono bloccare l’applicazione.
2.4.4 Esempio Pratico: Calcolo dei Numeri Primi
Descrizione: Scrivere un programma che stampi tutti i numeri primi da 1 a 100.
Implementazione:
public class NumeriPrimi {
public static void main(String[] args) {
for (int numero = 2; numero <= 100; numero++) {
boolean èPrimo = true;
for (int i = 2; i <= Math.sqrt(numero); i++) {
if (numero % i == 0) {
èPrimo = false;
break;
}
}
if (èPrimo) {
System.out.println(numero + " è un numero primo.");
}
}
}
}Spiegazione:
-
Ciclo Esterno (
for): Itera attraverso tutti i numeri da 2 a 100. -
Variabile
èPrimo: Assume inizialmente che il numero sia primo. -
Ciclo Interno (
for): Controlla se il numero è divisibile per qualsiasi numero tra 2 e la radice quadrata del numero stesso. -
Condizione
if: Se il numero non è primo,èPrimoviene impostato afalsee si esce dal ciclo interno. -
Stampa del Numero Primo: Se
èPrimorimanetrue, il numero viene stampato come numero primo.
Note:
-
L’utilizzo di
breaknel ciclo interno migliora l’efficienza evitando controlli inutili una volta trovato un divisore. -
La condizione
i <= Math.sqrt(numero)riduce il numero di iterazioni necessarie nel ciclo interno.
2.4.5 Approfondimenti per Colloqui Tecnici
Durante un colloquio tecnico, potresti essere chiamato a spiegare non solo come funzionano le strutture di controllo di flusso, ma anche a risolvere problemi pratici utilizzandole.
Esempio di Domanda: Come invertire una stringa senza utilizzare metodi o classi di libreria?
Possibile Risposta:
public class InvertiStringa {
public static void main(String[] args) {
String input = "Java";
String output = "";
for (int i = input.length() - 1; i >= 0; i--) {
output += input.charAt(i);
}
System.out.println("Stringa invertita: " + output);
}
}Spiegazione:
-
Utilizza un ciclo
forche parte dall’ultimo carattere della stringa e procede verso il primo. -
A ogni iterazione, concatena il carattere corrente alla variabile
output.
Considerazioni:
-
Questa soluzione ha una complessità temporale di O(n) e utilizza spazio aggiuntivo per la nuova stringa.
-
In un contesto più avanzato, potresti discutere l’uso di
StringBuilderper migliorare l’efficienza.
2.4.6 Conclusione
Le strutture di controllo di flusso sono strumenti potenti che consentono di modellare la logica di un programma in modo efficace. La comprensione approfondita di condizioni e cicli è essenziale per scrivere codice Java robusto e mantenibile. Sia che tu stia iniziando a programmare o preparando un colloquio tecnico, padroneggiare questi concetti ti fornirà una solida base per affrontare problemi più complessi.
Capitolo 3: Programmazione Orientata agli Oggetti
3.1 Classi e Oggetti
La programmazione orientata agli oggetti (OOP) è un paradigma che organizza il software come una raccolta di oggetti che interagiscono tra loro. In Java, tutto è basato sulle classi e sugli oggetti. Comprendere questi concetti è fondamentale per scrivere codice efficace e manutenibile.
Cos’è una Classe?
Una classe è un modello o uno schema che definisce le proprietà (attributi) e i comportamenti (metodi) che gli oggetti creati da essa avranno. In altre parole, una classe è una rappresentazione astratta di un concetto o di un’entità del mondo reale.
Sintassi di base di una classe in Java:
public class NomeClasse {
// Attributi (variabili di istanza)
// Metodi
}Esempio:
public class Persona {
String nome;
int età;
void saluta() {
System.out.println("Ciao, mi chiamo " + nome);
}
}In questo esempio, Persona è una classe con due attributi (nome ed età) e un metodo (saluta).
Cos’è un Oggetto?
Un oggetto è un’istanza di una classe. Quando crei un oggetto, stai creando una rappresentazione concreta della classe, con valori specifici per gli attributi definiti.
Creazione di un oggetto:
Persona persona1 = new Persona();Qui, persona1 è un oggetto della classe Persona. Utilizza la parola chiave new per allocare memoria per il nuovo oggetto.
Assegnazione di valori agli attributi e chiamata ai metodi:
persona1.nome = "Alice";
persona1.età = 30;
persona1.saluta(); // Output: Ciao, mi chiamo AliceCostruttori
Un costruttore è un metodo speciale utilizzato per inizializzare gli oggetti. Ha lo stesso nome della classe e non ha un tipo di ritorno, nemmeno void. I costruttori possono essere sovraccaricati per accettare diversi numeri di parametri.
Sintassi di un costruttore:
public class Persona {
String nome;
int età;
// Costruttore senza parametri
public Persona() {
nome = "Sconosciuto";
età = 0;
}
// Costruttore con parametri
public Persona(String nome, int età) {
this.nome = nome;
this.età = età;
}
void saluta() {
System.out.println("Ciao, mi chiamo " + nome);
}
}Utilizzo dei costruttori:
public class Main {
public static void main(String[] args) {
// Utilizza il costruttore senza parametri
Persona persona1 = new Persona();
persona1.saluta(); // Output: Ciao, mi chiamo Sconosciuto
// Utilizza il costruttore con parametri
Persona persona2 = new Persona("Marco", 25);
persona2.saluta(); // Output: Ciao, mi chiamo Marco
}
}Nota sull’uso di this:
La parola chiave this fa riferimento all’istanza corrente della classe. È spesso utilizzata nei costruttori e nei metodi per distinguere tra variabili di istanza e parametri con lo stesso nome.
public Persona(String nome, int età) {
this.nome = nome; // 'this.nome' si riferisce all'attributo della classe
this.età = età;
}Creazione di Classi e Istanze
Passaggi per creare una classe:
-
Definire la classe con la parola chiave
classseguita dal nome della classe. -
Dichiarare gli attributi (variabili di istanza) che rappresentano lo stato dell’oggetto.
-
Implementare i metodi che definiscono il comportamento dell’oggetto.
-
Creare costruttori per inizializzare gli oggetti.
Esempio completo:
public class Automobile {
String marca;
String modello;
int anno;
// Costruttore senza parametri
public Automobile() {
marca = "Sconosciuta";
modello = "Sconosciuto";
anno = 0;
}
// Costruttore con parametri
public Automobile(String marca, String modello, int anno) {
this.marca = marca;
this.modello = modello;
this.anno = anno;
}
void descrivi() {
System.out.println("Automobile: " + marca + " " + modello + ", Anno: " + anno);
}
}Creazione di istanze della classe Automobile:
public class Main {
public static void main(String[] args) {
// Utilizza il costruttore senza parametri
Automobile auto1 = new Automobile();
auto1.descrivi(); // Output: Automobile: Sconosciuta Sconosciuto, Anno: 0
// Utilizza il costruttore con parametri
Automobile auto2 = new Automobile("Fiat", "500", 2020);
auto2.descrivi(); // Output: Automobile: Fiat 500, Anno: 2020
}
}Sovraccarico dei Costruttori
Il sovraccarico permette di avere più costruttori nella stessa classe, ciascuno con una diversa lista di parametri. Questo offre flessibilità nella creazione di oggetti.
Esempio:
public class Rettangolo {
int larghezza;
int altezza;
// Costruttore senza parametri
public Rettangolo() {
this.larghezza = 1;
this.altezza = 1;
}
// Costruttore con un parametro
public Rettangolo(int lato) {
this.larghezza = lato;
this.altezza = lato;
}
// Costruttore con due parametri
public Rettangolo(int larghezza, int altezza) {
this.larghezza = larghezza;
this.altezza = altezza;
}
int calcolaArea() {
return larghezza * altezza;
}
}Utilizzo:
public class Main {
public static void main(String[] args) {
Rettangolo r1 = new Rettangolo();
Rettangolo r2 = new Rettangolo(5);
Rettangolo r3 = new Rettangolo(4, 6);
System.out.println("Area r1: " + r1.calcolaArea()); // Output: Area r1: 1
System.out.println("Area r2: " + r2.calcolaArea()); // Output: Area r2: 25
System.out.println("Area r3: " + r3.calcolaArea()); // Output: Area r3: 24
}
}Best Practices
-
Inizializzazione degli Attributi: Utilizza costruttori per assicurarti che gli oggetti siano sempre in uno stato valido.
-
Uso di
this(): Puoi chiamare un costruttore da un altro per evitare duplicazione di codice.
Esempio di chiamata a un altro costruttore:
public class Punto {
int x;
int y;
// Costruttore principale
public Punto(int x, int y) {
this.x = x;
this.y = y;
}
// Costruttore che chiama il costruttore principale
public Punto() {
this(0, 0);
}
}Incapsulamento (Introduzione)
Anche se non è il focus di questa sezione, è importante notare che gli attributi dovrebbero essere dichiarati come private per proteggere lo stato interno dell’oggetto. L’accesso e la modifica degli attributi dovrebbero avvenire tramite metodi pubblici chiamati getter e setter.
Esempio:
public class ContoBancario {
private double saldo;
public ContoBancario(double saldoIniziale) {
this.saldo = saldoIniziale;
}
public double getSaldo() {
return saldo;
}
public void deposita(double importo) {
if (importo > 0) {
saldo += importo;
}
}
public void preleva(double importo) {
if (importo > 0 && importo <= saldo) {
saldo -= importo;
}
}
}Riepilogo
-
Classi: Definiscono il modello degli oggetti.
-
Oggetti: Sono istanze concrete delle classi.
-
Costruttori: Inizializzano gli oggetti e possono essere sovraccaricati.
-
this: Riferimento all’istanza corrente, utile per distinguere tra attributi e parametri.
Esercizio Pratico
Crea una classe Studente con attributi nome, cognome e matricola. Implementa:
-
Un costruttore senza parametri che inizializza gli attributi con valori di default.
-
Un costruttore con parametri per inizializzare gli attributi con valori specifici.
-
Un metodo
visualizzaInformazioniche stampa le informazioni dello studente.
Soluzione:
public class Studente {
String nome;
String cognome;
int matricola;
// Costruttore senza parametri
public Studente() {
nome = "Nome";
cognome = "Cognome";
matricola = 0;
}
// Costruttore con parametri
public Studente(String nome, String cognome, int matricola) {
this.nome = nome;
this.cognome = cognome;
this.matricola = matricola;
}
void visualizzaInformazioni() {
System.out.println("Studente: " + nome + " " + cognome + ", Matricola: " + matricola);
}
}
public class Main {
public static void main(String[] args) {
Studente s1 = new Studente();
s1.visualizzaInformazioni(); // Output: Studente: Nome Cognome, Matricola: 0
Studente s2 = new Studente("Luca", "Rossi", 12345);
s2.visualizzaInformazioni(); // Output: Studente: Luca Rossi, Matricola: 12345
}
}Conclusione
La comprensione delle classi e degli oggetti è essenziale per la programmazione in Java. Saper creare e inizializzare oggetti correttamente ti permetterà di sviluppare applicazioni robuste e ben strutturate. I costruttori giocano un ruolo chiave nell’assicurare che gli oggetti siano in uno stato valido sin dalla loro creazione.
3.2 Incapsulamento
Introduzione all’Incapsulamento
L’incapsulamento è uno dei quattro pilastri fondamentali della programmazione orientata agli oggetti (OOP), insieme a astrazione, ereditarietà e polimorfismo. In termini semplici, l’incapsulamento consiste nel nascondere i dettagli interni di un oggetto e nel fornire un’interfaccia pubblica per interagire con esso. Questo principio permette di proteggere lo stato interno degli oggetti da accessi o modifiche non autorizzate, garantendo così l’integrità dei dati e facilitando la manutenzione e l’evoluzione del codice.
Perché l’Incapsulamento è Importante
-
Protezione dei Dati: Limitando l’accesso diretto ai campi di una classe, si previene la possibilità che dati inconsistente o non validi vengano assegnati agli attributi.
-
Manutenibilità: Separando l’interfaccia pubblica dall’implementazione interna, è possibile modificare il codice interno senza influenzare il codice che utilizza la classe.
-
Flessibilità: Attraverso metodi pubblici, è possibile aggiungere logica aggiuntiva durante l’accesso o la modifica dei dati (ad esempio, validazione o trasformazione dei valori).
-
Riutilizzabilità: Classi ben incapsulate sono più modulari e possono essere facilmente riutilizzate in contesti diversi.
Modificatori di Accesso
Java fornisce quattro modificatori di accesso che determinano la visibilità di classi, metodi e variabili:
-
public: L’elemento è accessibile da qualsiasi altra classe. -
private: L’elemento è accessibile solo all’interno della classe in cui è dichiarato. -
protected: L’elemento è accessibile all’interno del pacchetto e dalle sottoclassi anche se si trovano in pacchetti diversi. -
Default (nessun modificatore): L’elemento è accessibile solo all’interno del pacchetto (visibilità package-private).
Esempio:
public class ContoBancario {
private double saldo; // Variabile privata
public ContoBancario(double saldoIniziale) {
this.saldo = saldoIniziale;
}
public double getSaldo() {
return saldo;
}
public void deposita(double importo) {
if (importo > 0) {
saldo += importo;
} else {
System.out.println("Importo non valido per il deposito.");
}
}
public void preleva(double importo) {
if (importo > 0 && importo <= saldo) {
saldo -= importo;
} else {
System.out.println("Importo non valido o saldo insufficiente per il prelievo.");
}
}
}In questo esempio, la variabile saldo è dichiarata come private, impedendo l’accesso diretto dall’esterno della classe. L’accesso al saldo è controllato attraverso i metodi pubblici getSaldo(), deposita() e preleva(), che includono logica di validazione.
Getter e Setter
I getter e i setter sono metodi pubblici utilizzati per leggere e modificare i campi privati di una classe. Seguono una convenzione di denominazione standard:
-
Getter:
getNomeVariabile() -
Setter:
setNomeVariabile(valore)
Vantaggi dell’Utilizzo di Getter e Setter:
-
Controllo sull’Accesso: Possibilità di aggiungere logica di controllo o validazione.
-
Incapsulamento: Mantiene i campi privati e protegge l’integrità dell’oggetto.
-
Flessibilità: Permette di cambiare l’implementazione interna senza modificare l’interfaccia pubblica.
Esempio:
public class Persona {
private String nome;
private int eta;
public String getNome() {
return nome;
}
public void setNome(String nome) {
if (nome != null && !nome.isEmpty()) {
this.nome = nome;
} else {
System.out.println("Nome non può essere vuoto.");
}
}
public int getEta() {
return eta;
}
public void setEta(int eta) {
if (eta >= 0) {
this.eta = eta;
} else {
System.out.println("Età non può essere negativa.");
}
}
}Best Practices nell’Incapsulamento
-
Mantieni i Campi Privati: Dichiarare i campi come
privateper impedire accessi non autorizzati. -
Utilizza Getter e Setter con Cautela: Non tutti i campi necessitano di getter e setter pubblici. Esponi solo ciò che è necessario.
-
Immutabilità Quando Possibile: Per alcune classi, potrebbe essere utile rendere gli oggetti immutabili, ossia non modificabili dopo la creazione. Ciò aumenta la sicurezza e facilita la concorrenza.
Esempio di Classe Immutabile:
public final class Punto { private final int x; private final int y; public Punto(int x, int y) { this.x = x; this.y = y; } public int getX() { return x; } public int getY() { return y; } } -
Validazione dei Dati: Implementa controlli all’interno dei setter per assicurare che i dati inseriti siano validi.
-
Documentazione: Fornisci commenti e documentazione adeguata per chiarire l’utilizzo corretto dei metodi pubblici.
Incapsulamento e Design delle Classi
L’incapsulamento non si limita solo alla protezione dei dati, ma influisce anche sul design complessivo delle classi e delle applicazioni:
-
Interfacce Chiare: Definisci metodi pubblici che rappresentino azioni significative per l’oggetto, evitando di esporre dettagli implementativi.
-
Bassa Accoppiatura: Riduci le dipendenze tra le classi limitando l’accesso diretto ai dati interni, facilitando così la modifica e l’estensione del codice.
-
Alta Coesione: Raggruppa all’interno della classe solo i metodi e i dati strettamente correlati tra loro.
Esempio Completo
Supponiamo di dover modellare una classe Rettangolo che rappresenta un rettangolo geometrico.
Senza Incapsulamento:
public class Rettangolo {
public double larghezza;
public double altezza;
}In questo caso, chiunque può accedere e modificare liberamente larghezza e altezza, anche assegnando valori negativi o non sensati.
Con Incapsulamento:
public class Rettangolo {
private double larghezza;
private double altezza;
public Rettangolo(double larghezza, double altezza) {
setLarghezza(larghezza);
setAltezza(altezza);
}
public double getLarghezza() {
return larghezza;
}
public void setLarghezza(double larghezza) {
if (larghezza > 0) {
this.larghezza = larghezza;
} else {
throw new IllegalArgumentException("La larghezza deve essere positiva.");
}
}
public double getAltezza() {
return altezza;
}
public void setAltezza(double altezza) {
if (altezza > 0) {
this.altezza = altezza;
} else {
throw new IllegalArgumentException("L'altezza deve essere positiva.");
}
}
public double calcolaArea() {
return larghezza * altezza;
}
public double calcolaPerimetro() {
return 2 * (larghezza + altezza);
}
}Con questa implementazione:
-
Protezione dei Dati:
larghezzaealtezzasono private. -
Validazione: I setter controllano che i valori siano positivi.
-
Funzionalità Aggiuntiva: Metodi per calcolare area e perimetro.
-
Eccezioni Significative: Utilizzo di
IllegalArgumentExceptionper segnalare errori.
Conclusione
L’incapsulamento è un concetto fondamentale che contribuisce significativamente alla qualità del codice in Java e in altri linguaggi orientati agli oggetti. Applicando correttamente l’incapsulamento, si ottengono classi più sicure, modulari e facili da mantenere. Questo non solo facilita lo sviluppo individuale, ma è essenziale quando si lavora in team o su progetti di grandi dimensioni, dove la chiarezza e l’affidabilità del codice sono cruciali.
Domande di Riflessione
-
Come l’incapsulamento influisce sulla sicurezza dei dati in un’applicazione?
-
Quali potrebbero essere le conseguenze di esporre campi interni come pubblici?
-
In che modo l’incapsulamento facilita la manutenzione del codice nel lungo periodo?
Rispondere a queste domande può aiutarti a consolidare la comprensione dell’incapsulamento e a prepararti per applicarlo efficacemente nei tuoi progetti e durante i colloqui tecnici.
3.3 Ereditarietà
Introduzione all’Ereditarietà
L’ereditarietà è uno dei pilastri fondamentali della programmazione orientata agli oggetti (OOP). In Java, l’ereditarietà permette a una classe (sottoclasse) di derivare da un’altra classe (superclasse), ereditando campi e metodi. Questo meccanismo consente di creare una gerarchia di classi che riflette le relazioni del mondo reale e promuove il riutilizzo del codice.
Motivazioni dietro l’Ereditarietà
L’ereditarietà è stata introdotta per risolvere diversi problemi nello sviluppo software:
-
Riutilizzo del Codice: Evita la duplicazione di codice comune tra classi correlate.
-
Estendibilità: Permette di estendere le funzionalità di classi esistenti senza modificarle.
-
Manutenibilità: Facilita la gestione e l’aggiornamento del codice grazie a una struttura gerarchica chiara.
Superclassi e Sottoclassi
-
Superclasse: La classe da cui una o più sottoclassi ereditano. Definisce attributi e comportamenti comuni.
-
Sottoclasse: La classe che estende la superclasse, ereditandone campi e metodi e potendone aggiungere o modificare.
La Parola Chiave extends
In Java, l’ereditarietà si implementa utilizzando la parola chiave extends. La sintassi generale per dichiarare una sottoclasse è:
public class Sottoclasse extends Superclasse {
// Corpo della classe
}Esempio Pratico
Supponiamo di voler modellare veicoli di diversi tipi. Iniziamo creando una superclasse Veicolo:
public class Veicolo {
protected String marca;
protected String modello;
public Veicolo(String marca, String modello) {
this.marca = marca;
this.modello = modello;
}
public void accendi() {
System.out.println("Il veicolo è acceso.");
}
}Ora, creiamo una sottoclasse Automobile che estende Veicolo:
public class Automobile extends Veicolo {
private int numeroPorte;
public Automobile(String marca, String modello, int numeroPorte) {
super(marca, modello); // Chiamata al costruttore della superclasse
this.numeroPorte = numeroPorte;
}
public void suonaClacson() {
System.out.println("Beep! Beep!");
}
}Utilizzo della Sottoclasse
public class Main {
public static void main(String[] args) {
Automobile auto = new Automobile("Toyota", "Corolla", 4);
auto.accendi(); // Metodo ereditato da Veicolo
auto.suonaClacson(); // Metodo specifico di Automobile
System.out.println("Marca: " + auto.marca); // Campo ereditato
}
}Spiegazione dell’Esempio
-
Ereditarietà dei Campi e Metodi:
Automobileereditamarca,modelloeaccendi()daVeicolo. -
Estensione delle Funzionalità:
AutomobileintroducenumeroPorteesuonaClacson(). -
Accesso ai Membri Protetti: I campi
marcaemodellosono dichiaratiprotected, consentendo l’accesso diretto nelle sottoclassi.
Uso di super
La parola chiave super si utilizza per:
-
Chiamare il Costruttore della Superclasse:
super(marca, modello); -
Accedere ai Metodi e Campi della Superclasse:
super.metodoSuperclasse();
Sovrascrittura dei Metodi
Le sottoclassi possono modificare il comportamento dei metodi ereditati attraverso l’overriding.
@Override
public void accendi() {
System.out.println("L'automobile è accesa.");
}Regole per l’Overriding:
-
La firma del metodo deve essere identica.
-
La visibilità non può essere ridotta.
-
Può lanciare le stesse eccezioni o sottoclassi di esse.
Vantaggi dell’Ereditarietà
-
Modellazione Naturale: Rappresenta relazioni logiche tra oggetti.
-
Riduzione della Ridondanza: Evita codice duplicato.
-
Facilità di Manutenzione: Modifiche nella superclasse si riflettono automaticamente nelle sottoclassi.
Considerazioni Importanti
-
Relazione “È-Un”: L’ereditarietà dovrebbe essere utilizzata solo se esiste una relazione logica “è-un” tra la sottoclasse e la superclasse.
-
Ereditarietà Multipla: Java non supporta l’ereditarietà multipla di classi per evitare ambiguità, ma permette l’implementazione di più interfacce.
Composizione vs Ereditarietà
A volte, potrebbe essere più appropriato utilizzare la composizione anziché l’ereditarietà.
-
Composizione: Una classe ha un’istanza di un’altra classe (relazione “ha-un”).
-
Quando Usare la Composizione: Se le classi non condividono una relazione “è-un”, ma una relazione “ha-un”.
Esempio di Composizione
public class Motore {
public void avvia() {
System.out.println("Motore avviato.");
}
}
public class Automobile {
private Motore motore;
public Automobile() {
this.motore = new Motore();
}
public void accendi() {
motore.avvia();
System.out.println("Automobile accesa.");
}
}Best Practices
-
Evitare Gerarchie Profonde: Possono rendere il codice difficile da comprendere e mantenere.
-
Utilizzare
@Override: Annotare i metodi sovrascritti per migliorare la leggibilità e prevenire errori. -
Favorire la Composizione: Se l’ereditarietà non è strettamente necessaria, la composizione può offrire maggiore flessibilità.
Ereditarietà e Incapsulamento
L’ereditarietà può interferire con l’incapsulamento se i campi della superclasse non sono adeguatamente protetti. Utilizzare modificatori di accesso appropriati (private, protected, public) è essenziale per mantenere l’integrità dei dati.
Esempio Avanzato: Gerarchia di Classi
Immaginiamo di estendere ulteriormente la gerarchia con una classe Camion:
public class Camion extends Veicolo {
private double capacitaCarico;
public Camion(String marca, String modello, double capacitaCarico) {
super(marca, modello);
this.capacitaCarico = capacitaCarico;
}
public void caricaMerce(double peso) {
if (peso <= capacitaCarico) {
System.out.println("Merce caricata.");
} else {
System.out.println("Capacità di carico superata.");
}
}
}Polimorfismo con l’Ereditarietà
L’ereditarietà consente di utilizzare il polimorfismo, trattando oggetti di sottoclassi come istanze della superclasse.
Veicolo veicolo1 = new Automobile("Honda", "Civic", 4);
Veicolo veicolo2 = new Camion("Volvo", "FH16", 20.5);
veicolo1.accendi(); // Chiamata al metodo accendi() appropriato
veicolo2.accendi();Conclusione
L’ereditarietà è un concetto potente che, se usato correttamente, può migliorare significativamente la struttura e la manutenibilità del codice. Comprendere quando e come implementare l’ereditarietà è fondamentale per sfruttare appieno le potenzialità della programmazione orientata agli oggetti in Java.
Esercizio Pratico
Creare una gerarchia di classi per rappresentare diversi tipi di animali, implementando l’ereditarietà e il polimorfismo. Definire una superclasse Animale con metodi generici e sottoclassi come Cane e Gatto con comportamenti specifici.
Prossimi Passi
Nel prossimo paragrafo, approfondiremo il Polimorfismo e come l’ereditarietà ne sia una componente essenziale, permettendo di scrivere codice più flessibile e generale.
3.4 Polimorfismo
Il polimorfismo è uno dei quattro pilastri fondamentali della programmazione orientata agli oggetti (OOP), insieme a incapsulamento, ereditarietà e astrazione. Derivato dal greco “poli” (molti) e “morfo” (forme), il termine polimorfismo si riferisce alla capacità di un’entità di assumere molteplici forme.
In Java, il polimorfismo permette di utilizzare una singola interfaccia per rappresentare diverse implementazioni. Questo concetto è cruciale per creare codice flessibile e riutilizzabile, poiché consente di trattare oggetti di classi diverse in modo uniforme, purché condividano una classe base o un’interfaccia comune.
Ci sono due tipi principali di polimorfismo in Java:
-
Polimorfismo in fase di compilazione (statico): ottenuto tramite l’overloading dei metodi.
-
Polimorfismo in fase di esecuzione (dinamico): ottenuto tramite l’overriding dei metodi.
In questa sezione, esamineremo in dettaglio entrambi i tipi, analizzando le loro caratteristiche, differenze e applicazioni pratiche.
Overloading di Metodi (Sovraccarico di Metodi)
L’overloading è una forma di polimorfismo statico che consente di definire più metodi con lo stesso nome all’interno della stessa classe, differenziandoli per il numero, il tipo o l’ordine dei parametri. Il compilatore determina quale metodo invocare in base alla firma del metodo al momento della compilazione.
Motivazioni per l’Overloading
-
Leggibilità del Codice: Utilizzare nomi comuni per operazioni simili rende il codice più intuitivo.
-
Flessibilità: Permette di fornire diverse implementazioni di un metodo per gestire vari tipi di input.
-
Mantenibilità: Riduce la necessità di creare nomi di metodi differenti per funzionalità correlate.
Regole per l’Overloading
-
I metodi devono avere lo stesso nome ma firme diverse (numero o tipo dei parametri).
-
Possono avere modificatori di accesso e tipi di ritorno differenti.
-
Il tipo di ritorno da solo non è sufficiente per distinguere i metodi.
-
Possono lanciare eccezioni diverse.
Esempio Pratico di Overloading
public class Calcolatrice {
// Metodo per sommare due interi
public int somma(int a, int b) {
return a + b;
}
// Metodo per sommare tre interi
public int somma(int a, int b, int c) {
return a + b + c;
}
// Metodo per sommare due numeri in virgola mobile
public double somma(double a, double b) {
return a + b;
}
}Utilizzo:
Calcolatrice calc = new Calcolatrice();
int risultato1 = calc.somma(5, 10); // Chiama somma(int, int)
int risultato2 = calc.somma(5, 10, 15); // Chiama somma(int, int, int)
double risultato3 = calc.somma(5.5, 10.5); // Chiama somma(double, double)Spiegazione:
-
Il compilatore seleziona il metodo appropriato in base ai parametri passati.
-
Nonostante i metodi abbiano lo stesso nome, le firme differenti evitano conflitti.
Considerazioni sull’Overloading
-
L’overloading migliora la coesione semantica del codice.
-
Può portare a confusione se abusato o utilizzato senza criterio.
-
È importante mantenere una chiara distinzione nelle firme dei metodi per evitare ambiguità.
Overriding di Metodi (Ridefinizione di Metodi)
L’overriding è una forma di polimorfismo dinamico che permette a una sottoclasse di fornire una specifica implementazione di un metodo già definito nella sua superclasse. A differenza dell’overloading, l’overriding si basa sulla stessa firma del metodo.
Motivazioni per l’Overriding
-
Personalizzazione del Comportamento: Le sottoclassi possono adattare o estendere il comportamento ereditato.
-
Polimorfismo: Permette di trattare oggetti di classi diverse in modo uniforme, sfruttando implementazioni specifiche in fase di esecuzione.
-
Estensibilità: Facilita l’aggiunta di nuove funzionalità senza modificare il codice esistente della superclasse.
Regole per l’Overriding
-
Il metodo nella sottoclasse deve avere la stessa firma (nome e parametri) del metodo nella superclasse.
-
Il tipo di ritorno deve essere lo stesso o un sottotipo (covariante) del tipo di ritorno della superclasse.
-
Il modificatore di accesso non può essere più restrittivo di quello del metodo nella superclasse.
-
Il metodo non può lanciare nuove eccezioni verificate o eccezioni più generali.
-
Il metodo nella superclasse non deve essere dichiarato come
final.
Esempio Pratico di Overriding
class Animale {
public void emettiVerso() {
System.out.println("L'animale emette un verso.");
}
}
class Cane extends Animale {
@Override
public void emettiVerso() {
System.out.println("Il cane abbaia.");
}
}
class Gatto extends Animale {
@Override
public void emettiVerso() {
System.out.println("Il gatto miagola.");
}
}Utilizzo:
Animale animale1 = new Animale();
Animale animale2 = new Cane();
Animale animale3 = new Gatto();
animale1.emettiVerso(); // Output: L'animale emette un verso.
animale2.emettiVerso(); // Output: Il cane abbaia.
animale3.emettiVerso(); // Output: Il gatto miagola.Spiegazione:
-
Anche se le variabili sono di tipo
Animale, il metodo invocato è quello della classe effettiva dell’oggetto. -
L’annotazione
@Overrideindica al compilatore che il metodo dovrebbe sovrascrivere un metodo della superclasse.
Considerazioni sull’Overriding
-
L’overriding permette il late binding, dove la decisione su quale metodo chiamare avviene in fase di esecuzione.
-
È fondamentale per implementare interfacce e classi astratte.
-
L’uso corretto dell’overriding migliora l’estensibilità e la manutenzione del codice.
Differenze Chiave tra Overloading e Overriding
Esempio Combinato: Overloading e Overriding
class Veicolo {
public void avvia() {
System.out.println("Il veicolo si avvia.");
}
public void rifornisci(int litri) {
System.out.println("Rifornimento di " + litri + " litri.");
}
}
class Auto extends Veicolo {
@Override
public void avvia() {
System.out.println("L'auto si avvia con la chiave.");
}
// Overloading del metodo rifornisci
public void rifornisci(int litri, String tipoCarburante) {
System.out.println("Rifornimento di " + litri + " litri di " + tipoCarburante + ".");
}
}Utilizzo:
Veicolo mioVeicolo = new Veicolo();
Veicolo miaAuto = new Auto();
mioVeicolo.avvia(); // Output: Il veicolo si avvia.
miaAuto.avvia(); // Output: L'auto si avvia con la chiave.
miaAuto.rifornisci(50); // Output: Rifornimento di 50 litri.
((Auto) miaAuto).rifornisci(50, "Benzina"); // Output: Rifornimento di 50 litri di Benzina.Spiegazione:
-
Autosovrascrive il metodoavvia()diVeicolo. -
Autosovraccarica il metodorifornisci(), aggiungendo un parametro per il tipo di carburante. -
Per chiamare il metodo sovraccaricato, è necessario eseguire un cast a
Auto.
Vantaggi del Polimorfismo
-
Flessibilità del Codice: Permette di scrivere codice generico che funziona con oggetti di classi diverse.
-
Estensibilità: Facilita l’aggiunta di nuove classi senza modificare il codice esistente.
-
Manutenibilità: Riduce la duplicazione del codice e favorisce una migliore organizzazione.
Best Practices
-
Uso dell’Annotazione
@Override: Aiuta a prevenire errori e migliora la leggibilità. -
Chiarezza nell’Overloading: Evitare firme troppo simili che possano causare confusione.
-
Comprensione Profonda: Assicurarsi di comprendere quando utilizzare overloading o overriding per sfruttare appieno il polimorfismo.
Conclusione
Il polimorfismo è un concetto chiave che permette di scrivere codice Java potente e flessibile. Comprendere le differenze tra overloading e overriding è fondamentale per sfruttare appieno le potenzialità della programmazione orientata agli oggetti. Attraverso l’uso appropriato di questi meccanismi, è possibile creare applicazioni estensibili, mantenibili e in grado di adattarsi facilmente a nuovi requisiti.
3.5 Classi Astratte e Interfacce
Le classi astratte e le interfacce sono due strumenti fondamentali della programmazione orientata agli oggetti in Java. Entrambi permettono di definire un contratto o una struttura comune che altre classi possono implementare o estendere. Tuttavia, presentano differenze sostanziali nel modo in cui funzionano e in come dovrebbero essere utilizzate.
Classi Astratte
Una classe astratta è una classe che non può essere istanziata direttamente. Serve come base per altre classi e può contenere sia metodi astratti (senza implementazione) che metodi concreti (con implementazione). Le classi che estendono una classe astratta devono fornire l’implementazione dei metodi astratti, a meno che anch’esse non siano dichiarate astratte.
Caratteristiche principali:
-
Non istanziabile: Non è possibile creare oggetti direttamente da una classe astratta.
-
Metodi astratti e concreti: Può contenere sia metodi astratti che metodi con implementazione.
-
Variabili di istanza: Può dichiarare variabili di istanza, anche con modificatori di accesso.
-
Costruttori: Può avere costruttori che saranno chiamati dalle sottoclassi.
-
Ereditarietà singola: Una classe può estendere una sola classe (astratta o concreta).
Esempio:
public abstract class Animale {
protected String nome;
public Animale(String nome) {
this.nome = nome;
}
public abstract void verso();
public void dorme() {
System.out.println(nome + " sta dormendo.");
}
}
public class Cane extends Animale {
public Cane(String nome) {
super(nome);
}
@Override
public void verso() {
System.out.println(nome + " abbaia.");
}
}In questo esempio, Animale è una classe astratta che definisce un metodo astratto verso(). La classe Cane estende Animale e fornisce l’implementazione di verso().
Interfacce
Un’interfaccia è un contratto che specifica un insieme di metodi che una classe deve implementare. A differenza delle classi astratte, le interfacce non possono contenere variabili di istanza (ad eccezione di costanti) e fino a Java 8 non potevano avere metodi con implementazione. Da Java 8 in poi, le interfacce possono includere metodi predefiniti (default) e statici con implementazione.
Caratteristiche principali:
-
Metodi astratti (prima di Java 8): Tutti i metodi sono implicitamente pubblici e astratti.
-
Costanti: Può contenere variabili statiche finali (costanti).
-
Ereditarietà multipla: Una classe può implementare più interfacce.
-
Metodi default e statici (da Java 8): Possono avere metodi con implementazione.
Esempio:
public interface Volante {
void vola();
}
public interface Nuotante {
void nuota();
}
public class Anatra implements Volante, Nuotante {
@Override
public void vola() {
System.out.println("L'anatra sta volando.");
}
@Override
public void nuota() {
System.out.println("L'anatra sta nuotando.");
}
}In questo caso, Anatra implementa due interfacce, Volante e Nuotante, e fornisce l’implementazione dei metodi richiesti.
Differenze Chiave
Utilizzi Pratici
Quando usare una classe astratta:
-
Condivisione di codice comune: Quando diverse classi condividono un’implementazione comune.
-
Ereditarietà: Quando si vuole definire una gerarchia di classi con comportamenti base.
-
Protezione dei dati: Quando si desidera proteggere variabili di istanza e fornire accesso controllato.
Esempio pratico:
public abstract class Forma {
public abstract double area();
public void descrizione() {
System.out.println("Questa è una forma geometrica.");
}
}
public class Cerchio extends Forma {
private double raggio;
public Cerchio(double raggio) {
this.raggio = raggio;
}
@Override
public double area() {
return Math.PI * raggio * raggio;
}
}Quando usare un’interfaccia:
-
Implementazione multipla: Quando una classe deve aderire a più contratti.
-
Definizione di comportamenti comuni non correlati gerarchicamente: Per classi che condividono comportamenti ma non una relazione padre-figlio.
-
Costanza del contratto: Quando si vuole garantire che l’implementazione dei metodi rimanga coerente tra diverse classi.
Esempio pratico:
public interface Caricabile {
void carica(int percentuale);
}
public class Smartphone implements Caricabile {
@Override
public void carica(int percentuale) {
System.out.println("Il telefono è stato caricato al " + percentuale + "%.");
}
}
public class Laptop implements Caricabile {
@Override
public void carica(int percentuale) {
System.out.println("Il laptop è stato caricato al " + percentuale + "%.");
}
}In questo esempio, sia Smartphone che Laptop implementano l’interfaccia Caricabile, pur non avendo una relazione di ereditarietà.
Scelta tra Classe Astratta e Interfaccia
La scelta tra una classe astratta e un’interfaccia dipende dal contesto e dalle esigenze del progetto.
Usa una classe astratta quando:
-
Vuoi fornire un’implementazione comune a tutte le sottoclassi.
-
Hai bisogno di definire variabili di istanza protette o pubbliche.
-
Vuoi utilizzare costruttori per inizializzare le variabili.
Usa un’interfaccia quando:
-
Vuoi definire un contratto che diverse classi possono implementare, indipendentemente dalla loro posizione nella gerarchia delle classi.
-
Hai bisogno di supportare l’ereditarietà multipla di tipo.
-
Vuoi garantire che certe funzionalità siano presenti in classi non correlate.
Esempio Concreto di Differenze
Supponiamo di avere un sistema che gestisce diversi tipi di veicoli.
Classe Astratta:
public abstract class Veicolo {
protected String tipoCombustibile;
public Veicolo(String tipoCombustibile) {
this.tipoCombustibile = tipoCombustibile;
}
public abstract void avvia();
public void rifornisci() {
System.out.println("Rifornimento di " + tipoCombustibile);
}
}Interfacce:
public interface Navigabile {
void naviga();
}
public interface Volante {
void vola();
}Classi Concrete:
public class Automobile extends Veicolo {
public Automobile() {
super("Benzina");
}
@Override
public void avvia() {
System.out.println("Automobile avviata.");
}
}
public class Aereo extends Veicolo implements Volante {
public Aereo() {
super("Cherosene");
}
@Override
public void avvia() {
System.out.println("Aereo avviato.");
}
@Override
public void vola() {
System.out.println("Aereo in volo.");
}
}
public class Barca extends Veicolo implements Navigabile {
public Barca() {
super("Diesel");
}
@Override
public void avvia() {
System.out.println("Barca avviata.");
}
@Override
public void naviga() {
System.out.println("Barca in navigazione.");
}
}In questo esempio:
-
Veicoloè una classe astratta che fornisce un’implementazione comune per i veicoli. -
AereoeBarcaimplementano rispettivamente le interfacceVolanteeNavigabile, aggiungendo comportamenti specifici.
Conclusione
Le classi astratte e le interfacce sono strumenti potenti che, se utilizzati correttamente, possono rendere il codice più flessibile e mantenibile. La scelta tra l’uno o l’altro dipende dai requisiti del progetto:
-
Scegli una classe astratta quando hai bisogno di condividere codice e vuoi sfruttare l’ereditarietà.
-
Scegli un’interfaccia quando vuoi definire un contratto che classi non correlate possono implementare.
Comprendere le differenze e i casi d’uso appropriati ti aiuterà a progettare applicazioni Java più robuste e scalabili.
Capitolo 4: Gestione delle Eccezioni
4.1 Introduzione alle Eccezioni
La gestione delle eccezioni è un elemento fondamentale nella programmazione Java, essenziale per sviluppare applicazioni robuste e affidabili. Un’eccezione rappresenta un evento anomalo o inatteso che si verifica durante l’esecuzione di un programma, interrompendo il normale flusso delle istruzioni. Questo può includere errori come il tentativo di accedere a un elemento fuori dai limiti di un array, divisione per zero, o problemi di I/O come la mancata apertura di un file.
Perché le Eccezioni sono Importanti
-
Robustezza del Codice: Gestendo le eccezioni, è possibile prevenire il crash dell’applicazione, permettendo al programma di gestire gli errori in modo controllato e di continuare l’esecuzione o di terminare in modo elegante.
-
Manutenibilità: Un codice che gestisce le eccezioni in modo efficace è più facile da mantenere e da debuggare, poiché gli errori vengono isolati e trattati in sezioni specifiche del codice.
-
Affidabilità dell’Applicazione: Gli utenti si aspettano che le applicazioni gestiscano gli errori in modo trasparente, fornendo messaggi utili o alternative quando qualcosa va storto.
Tipi di Eccezioni
In Java, le eccezioni sono oggetti che descrivono un evento anomalo e sono suddivise principalmente in due categorie:
-
Checked Exceptions (Eccezioni Verificate):
-
Sono controllate al momento della compilazione.
-
Il compilatore verifica che il programma gestisca queste eccezioni tramite blocchi
try-catcho dichiarandole con la parola chiavethrowsnella firma del metodo. -
Esempi:
IOException,SQLException,FileNotFoundException. -
Quando si Usano: Quando l’errore può essere previsto e recuperato in modo ragionevole, come problemi di I/O o database.
-
-
Unchecked Exceptions (Eccezioni Non Verificate):
-
Non sono controllate dal compilatore.
-
Derivano da
RuntimeExceptionoError. -
RuntimeException: Indicano errori di programmazione come
NullPointerException,ArrayIndexOutOfBoundsException.- Esempi: Divisione per zero, accesso a un oggetto nullo.
-
Error: Indicano problemi più seri che l’applicazione non dovrebbe gestire, come
OutOfMemoryError.- Esempi: Risorse insufficienti, errori di sistema.
-
Gerarchia delle Eccezioni
Comprendere la gerarchia delle eccezioni in Java aiuta a gestirle in modo più efficace:
-
Throwable: Classe base per tutti gli errori ed eccezioni.
-
Exception: Rappresenta condizioni anomale che un’applicazione può aspettarsi e gestire.
-
Checked Exceptions: Devono essere dichiarate o catturate.
-
RuntimeException: Eccezioni che possono verificarsi durante l’esecuzione e che un programma può evitare con un codice corretto.
-
-
Error: Rappresenta problemi gravi che di solito non possono essere gestiti dall’applicazione.
-
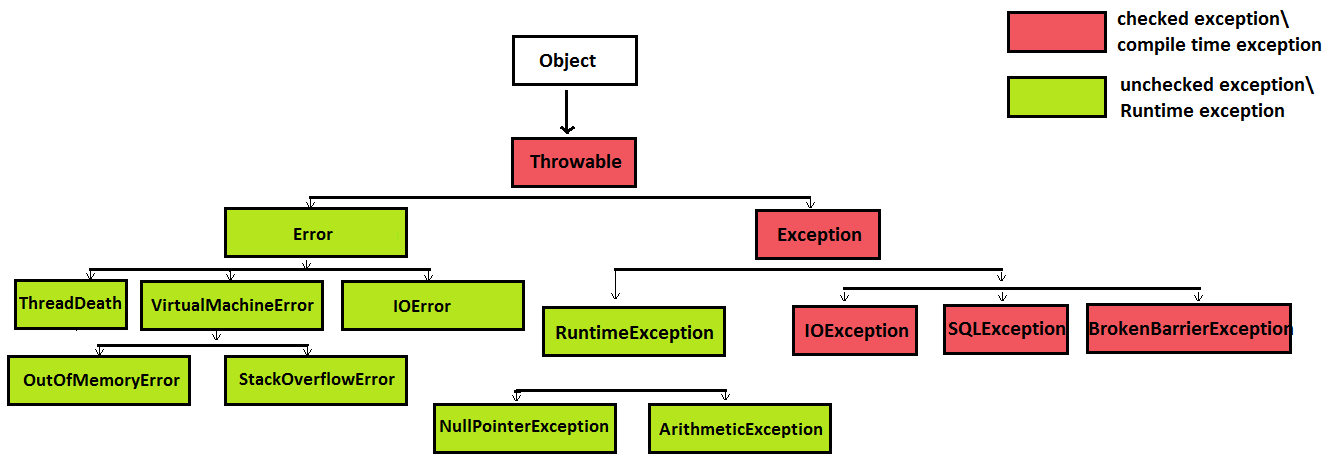
Quando Utilizzare le Eccezioni
-
Validazione degli Input: Controllare che gli argomenti di un metodo siano validi.
-
Operazioni I/O: Gestire errori durante la lettura o scrittura su file o rete.
-
Operazioni di Conversione: Gestire errori durante il parsing di stringhe in numeri o date.
-
Accesso a Risorse Esterne: Gestire l’indisponibilità di risorse come database o servizi web.
Esempio Pratico
Supponiamo di voler leggere un file di testo:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class LettoreFile {
public void leggiFile(String percorsoFile) {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(percorsoFile));
String linea;
while ((linea = reader.readLine()) != null) {
System.out.println(linea);
}
} catch (IOException e) {
System.err.println("Errore durante la lettura del file: " + e.getMessage());
} finally {
try {
if (reader != null) {
reader.close();
}
} catch (IOException ex) {
System.err.println("Errore durante la chiusura del file: " + ex.getMessage());
}
}
}
}In questo esempio:
-
IOException: È una checked exception che deve essere gestita. -
Blocco
try-catch-finally: Permette di gestire l’eccezione e di eseguire operazioni di pulizia nel bloccofinally.
Importanza per Sviluppatori Esperti
Anche per sviluppatori senior, una solida comprensione delle eccezioni è fondamentale:
-
Best Practices: Evitare la cattura di eccezioni generiche, preferire eccezioni specifiche.
-
Creazione di Eccezioni Personalizzate: Per rappresentare condizioni specifiche dell’applicazione.
-
Gestione delle Risorse: Assicurarsi che risorse come file o connessioni di rete siano sempre correttamente chiuse, anche in caso di errore.
Conclusione
Le eccezioni sono uno strumento potente per gestire gli errori e le condizioni anomale nelle applicazioni Java. Una gestione efficace delle eccezioni migliora la qualità del codice, l’esperienza dell’utente e facilita la manutenzione e l’espansione del software. Sia per i nuovi programmatori che per i veterani, padroneggiare le eccezioni è un passo indispensabile per sviluppare applicazioni robuste e professionali.
4.2 Try-Catch-Finally
La gestione delle eccezioni è un aspetto cruciale nello sviluppo di applicazioni Java affidabili e robuste. Il costrutto try-catch-finally fornisce un meccanismo per intercettare e gestire le eccezioni che possono verificarsi durante l’esecuzione di un programma, permettendo di mantenere il controllo del flusso di esecuzione anche in presenza di errori.
Il Blocco try
Il blocco try contiene il codice che potrebbe generare un’eccezione. Qualsiasi operazione che ha il potenziale di fallire dovrebbe essere racchiusa all’interno di un blocco try per consentire una gestione appropriata degli errori.
Sintassi:
try {
// Codice potenzialmente a rischio di eccezioni
}Esempio:
try {
int risultato = 10 / 0;
}In questo esempio, l’operazione di divisione per zero genera un’ArithmeticException.
Il Blocco catch
Il blocco catch segue immediatamente il blocco try e intercetta le eccezioni lanciate nel blocco try. È possibile avere più blocchi catch per gestire diversi tipi di eccezioni in modo specifico.
Sintassi:
catch (TipoEccezione e) {
// Gestione dell'eccezione
}Esempio:
try {
int[] numeri = {1, 2, 3};
System.out.println(numeri[5]);
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Indice fuori dai limiti dell'array.");
}Qui, l’accesso a un indice non valido dell’array genera un’ArrayIndexOutOfBoundsException, che viene catturata e gestita nel blocco catch.
Il Blocco finally
Il blocco finally viene eseguito indipendentemente dal fatto che un’eccezione sia stata lanciata o meno. È tipicamente utilizzato per eseguire operazioni di pulizia, come chiudere risorse aperte (file, connessioni di rete, database, etc.).
Sintassi:
finally {
// Codice che viene eseguito sempre
}Esempio:
FileReader fr = null;
try {
fr = new FileReader("file.txt");
// Operazioni di lettura sul file
} catch (FileNotFoundException e) {
System.out.println("File non trovato.");
} finally {
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
System.out.println("Errore nella chiusura del file.");
}
}
}In questo esempio, il blocco finally assicura che il FileReader venga chiuso, evitando potenziali leak di risorse.
Try-with-Resources
Introdotto in Java 7, il costrutto try-with-resources semplifica la gestione delle risorse che devono essere chiuse dopo l’uso. Qualsiasi oggetto che implementa l’interfaccia AutoCloseable può essere gestito in questo modo, garantendo la chiusura automatica delle risorse al termine del blocco try.
Sintassi:
try (RisorsaTipo risorsa = new RisorsaTipo()) {
// Utilizzo della risorsa
} catch (TipoEccezione e) {
// Gestione dell'eccezione
}Esempio:
try (BufferedReader br = new BufferedReader(new FileReader("file.txt"))) {
String linea;
while ((linea = br.readLine()) != null) {
System.out.println(linea);
}
} catch (IOException e) {
System.out.println("Errore durante la lettura del file: " + e.getMessage());
}In questo caso, non è necessario chiudere manualmente il BufferedReader; il costrutto try-with-resources si occupa di chiamare automaticamente il metodo close() al termine del blocco try.
Vantaggi di try-with-resources:
-
Codice più pulito e leggibile: Elimina la necessità di un blocco
finallyper la chiusura delle risorse. -
Riduzione degli errori: Evita il rischio di dimenticare di chiudere una risorsa, prevenendo leak di memoria.
-
Gestione efficiente delle eccezioni: Se sia il blocco
tryche il metodoclose()lanciano un’eccezione, quest’ultima viene soppressa, semplificando la gestione degli errori.
Ordine di Esecuzione
È importante comprendere come Java gestisce l’ordine di esecuzione tra i blocchi try, catch e finally:
-
Esecuzione del blocco
try: Il codice viene eseguito fino a quando non si verifica un’eccezione o il blocco termina. -
Intercettazione con
catch: Se un’eccezione viene lanciata, il controllo passa al primo bloccocatchche corrisponde al tipo di eccezione. -
Esecuzione del blocco
finally: Indipendentemente dal risultato, il bloccofinallyviene eseguito sempre.
Esempio:
try {
System.out.println("Inizio del blocco try.");
int risultato = 10 / 0;
System.out.println("Questo non verrà stampato.");
} catch (ArithmeticException e) {
System.out.println("Eccezione catturata: " + e.getMessage());
} finally {
System.out.println("Blocco finally eseguito.");
}Output:
Inizio del blocco try.
Eccezione catturata: / by zero
Blocco finally eseguito.
Best Practices nella Gestione delle Eccezioni
-
Catturare eccezioni specifiche: Evitare di utilizzare eccezioni generiche come
ExceptionoThrowablea meno che non sia strettamente necessario.catch (IOException e) { // Gestione specifica per errori di I/O } -
Evitare blocchi
catchvuoti: Un bloccocatchsenza contenuto rende difficile il debug e la manutenzione del codice.catch (SQLException e) { // Log dell'errore o rilancio dell'eccezione e.printStackTrace(); } -
Utilizzare messaggi di errore informativi: Fornire dettagli utili nel log o nei messaggi di errore facilita la risoluzione dei problemi.
catch (FileNotFoundException e) { System.out.println("Il file specificato non è stato trovato: " + e.getFile()); } -
Rilanciare eccezioni se necessario: In alcuni casi, potrebbe essere opportuno rilanciare un’eccezione dopo aver eseguito alcune operazioni di pulizia o log.
catch (IOException e) { // Operazioni di log throw e; }
Esercizio Pratico
Obiettivo: Scrivere un programma che legga numeri interi da un file chiamato numeri.txt e calcoli la loro somma. Gestire le possibili eccezioni che possono verificarsi, come il file non trovato o il formato errato dei numeri, utilizzando try-catch-finally o try-with-resources.
Soluzione:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class SommaNumeriDaFile {
public static void main(String[] args) {
int somma = 0;
try (BufferedReader br = new BufferedReader(new FileReader("numeri.txt"))) {
String linea;
while ((linea = br.readLine()) != null) {
try {
int numero = Integer.parseInt(linea);
somma += numero;
} catch (NumberFormatException e) {
System.out.println("Formato non valido: '" + linea + "' non è un numero intero.");
}
}
System.out.println("La somma dei numeri è: " + somma);
} catch (IOException e) {
System.out.println("Errore durante l'accesso al file: " + e.getMessage());
}
}
}Spiegazione:
-
Utilizziamo
try-with-resourcesper gestire automaticamente la chiusura delBufferedReader. -
All’interno del ciclo
while, tentiamo di convertire ogni linea letta in un numero intero. -
Se la conversione fallisce, catturiamo l’
NumberFormatExceptione informiamo l’utente. -
Eventuali
IOExceptiondurante l’accesso al file vengono gestite nel bloccocatchesterno.
Conclusione
La corretta gestione delle eccezioni con try-catch-finally è essenziale per lo sviluppo di applicazioni Java affidabili. Comprendere come e quando utilizzare questi costrutti permette di prevenire comportamenti inaspettati e di fornire un’esperienza utente migliore, garantendo al contempo la manutenzione e la scalabilità del codice.
4.3 Creazione di Eccezioni Personalizzate
La gestione delle eccezioni in Java è fondamentale per creare applicazioni robuste e affidabili. Sebbene Java fornisca una vasta gamma di eccezioni predefinite, spesso è necessario definire eccezioni personalizzate per rappresentare situazioni di errore specifiche del dominio dell’applicazione. Creare eccezioni personalizzate permette di comunicare in modo più chiaro e preciso gli errori che possono verificarsi, facilitando la manutenzione e la comprensione del codice.
4.3.1 Perché Creare Eccezioni Personalizzate?
Le eccezioni predefinite di Java, come NullPointerException o IOException, sono generiche e potrebbero non descrivere accuratamente l’errore specifico che si è verificato nella vostra applicazione. Definire eccezioni personalizzate offre diversi vantaggi:
-
Chiarezza: Fornisce informazioni più dettagliate sull’errore, rendendo il codice più leggibile.
-
Manutenibilità: Facilita il debug e la risoluzione dei problemi, poiché le eccezioni sono specifiche al contesto.
-
Organizzazione: Aiuta a categorizzare e gestire gli errori in modo più strutturato.
4.3.2 Tipi di Eccezioni Personalizzate
Prima di creare un’eccezione personalizzata, è importante decidere se deve essere una checked exception o una unchecked exception.
-
Checked Exception: Sono verificate al momento della compilazione. Dovrebbero essere dichiarate nel metodo usando la clausola
throws. Si estendono dalla classeException. -
Unchecked Exception: Non sono verificate al momento della compilazione. Possono essere ignorate dal compilatore. Si estendono dalla classe
RuntimeException.
Quando usare l’una o l’altra?
-
Utilizzare checked exceptions quando il client del metodo è ragionevolmente in grado di recuperare dall’errore.
-
Utilizzare unchecked exceptions per errori di programmazione, come passare argomenti invalidi.
4.3.3 Come Creare un’Eccezione Personalizzata
Creare un’eccezione personalizzata in Java è semplice: basta estendere la classe appropriata (Exception o RuntimeException) e definire i costruttori necessari.
Esempio di Checked Exception Personalizzata
public class InvalidUserInputException extends Exception {
public InvalidUserInputException() {
super();
}
public InvalidUserInputException(String message) {
super(message);
}
public InvalidUserInputException(String message, Throwable cause) {
super(message, cause);
}
public InvalidUserInputException(Throwable cause) {
super(cause);
}
}Esempio di Unchecked Exception Personalizzata
public class DatabaseConnectionException extends RuntimeException {
public DatabaseConnectionException() {
super();
}
public DatabaseConnectionException(String message) {
super(message);
}
public DatabaseConnectionException(String message, Throwable cause) {
super(message, cause);
}
public DatabaseConnectionException(Throwable cause) {
super(cause);
}
}4.3.4 Utilizzo di Eccezioni Personalizzate
Una volta definita l’eccezione personalizzata, è possibile utilizzarla all’interno del codice come qualsiasi altra eccezione.
Esempio di Lancio di una Checked Exception Personalizzata
public void processUserInput(String input) throws InvalidUserInputException {
if (input == null || input.isEmpty()) {
throw new InvalidUserInputException("L'input dell'utente non può essere nullo o vuoto.");
}
// Logica per elaborare l'input
}Esempio di Lancio di una Unchecked Exception Personalizzata
public void connectToDatabase() {
try {
// Tentativo di connessione al database
} catch (SQLException e) {
throw new DatabaseConnectionException("Errore durante la connessione al database.", e);
}
}4.3.5 Best Practices nella Creazione di Eccezioni Personalizzate
-
Nomi Significativi: Il nome dell’eccezione dovrebbe riflettere chiaramente il problema che rappresenta.
-
Messaggi Dettagliati: Fornire messaggi d’errore chiari e dettagliati per facilitare il debug.
-
Ereditarietà Appropriata: Estendere la classe corretta (
ExceptionoRuntimeException) in base al tipo di eccezione. -
Costruttori Standard: Fornire diversi costruttori per flessibilità, inclusi quelli che accettano messaggi e cause.
-
Documentazione: Documentare l’eccezione e le condizioni in cui viene lanciata.
4.3.6 Esempio Completo
Supponiamo di avere un sistema di gestione degli ordini e vogliamo lanciare un’eccezione quando un ordine non viene trovato.
Definizione dell’Eccezione Personalizzata
public class OrderNotFoundException extends Exception {
public OrderNotFoundException() {
super();
}
public OrderNotFoundException(String message) {
super(message);
}
public OrderNotFoundException(String message, Throwable cause) {
super(message, cause);
}
public OrderNotFoundException(Throwable cause) {
super(cause);
}
}Utilizzo dell’Eccezione Personalizzata
public Order findOrderById(String orderId) throws OrderNotFoundException {
Order order = orderRepository.getOrderById(orderId);
if (order == null) {
throw new OrderNotFoundException("Ordine con ID " + orderId + " non trovato.");
}
return order;
}Gestione dell’Eccezione
public void displayOrder(String orderId) {
try {
Order order = findOrderById(orderId);
// Logica per visualizzare l'ordine
} catch (OrderNotFoundException e) {
System.err.println(e.getMessage());
// Logica alternativa, come notificare l'utente o registrare l'errore
}
}4.3.7 Considerazioni Avanzate
-
Gerarchie di Eccezioni: In applicazioni complesse, potrebbe essere utile creare una gerarchia di eccezioni personalizzate per rappresentare diversi tipi di errori correlati.
public class ApplicationException extends Exception { // Eccezione base per l'applicazione } public class DataAccessException extends ApplicationException { // Eccezioni relative all'accesso ai dati } public class ServiceException extends ApplicationException { // Eccezioni relative ai servizi di business } -
Serializzazione: Se le eccezioni devono essere trasmesse attraverso la rete o salvate su disco, assicurarsi che siano serializzabili.
-
Aggiunta di Metodi Personalizzati: In alcuni casi, potrebbe essere utile aggiungere metodi o proprietà aggiuntive alle eccezioni per fornire più contesto.
public class ValidationException extends Exception { private List<String> validationErrors; public ValidationException(List<String> validationErrors) { super("Errore di validazione"); this.validationErrors = validationErrors; } public List<String> getValidationErrors() { return validationErrors; } }
4.3.8 Conclusione
Le eccezioni personalizzate sono uno strumento potente per migliorare la robustezza e la manutenibilità delle applicazioni Java. Permettono di rappresentare in modo preciso gli errori specifici del dominio, facilitando la gestione degli stessi sia per gli sviluppatori che per gli utenti finali. Seguendo le best practices e comprendendo quando e come utilizzarle, è possibile scrivere codice più chiaro, efficace e professionale.
4.3.9 Domande di Ripasso
-
Quando è opportuno creare un’eccezione personalizzata?
-
Qual è la differenza tra una checked exception e una unchecked exception?
-
Quali sono le best practices nella creazione di eccezioni personalizzate?
-
Come si gestiscono le eccezioni personalizzate nel codice client?
4.3.10 Esercizio Pratico
Crea un’eccezione personalizzata chiamata InsufficientFundsException che viene lanciata quando un utente tenta di prelevare un importo superiore al saldo disponibile nel proprio conto bancario. Implementa un metodo withdraw(double amount) nella classe BankAccount che lancia questa eccezione quando necessario. Scrivi anche il codice per gestire questa eccezione e informare l’utente dell’errore.
Questo approccio approfondito alla creazione di eccezioni personalizzate non solo rafforza la gestione degli errori nella vostra applicazione, ma dimostra anche una comprensione avanzata delle strutture di controllo in Java, competenza spesso valutata nei colloqui tecnici.
4.4 Best Practices nella Gestione degli Errori
La gestione delle eccezioni è un aspetto cruciale nello sviluppo di applicazioni Java robuste e affidabili. Un approccio efficace alla gestione degli errori non solo previene il crash delle applicazioni ma migliora anche l’esperienza dell’utente e facilita il processo di debugging. Di seguito sono riportate alcune best practices che aiutano a gestire le eccezioni in modo pulito ed efficiente.
4.4.1 Utilizzare Eccezioni Specifiche
Evitare di catturare l’eccezione generica Exception o Throwable, poiché questo può mascherare errori imprevisti e rendere il debug più difficile. Invece, catturare eccezioni specifiche che riflettono il problema reale.
Esempio:
try {
// Codice che potrebbe lanciare un'IOException
} catch (IOException e) {
// Gestione specifica per IOException
}4.4.2 Non Sopprimere le Eccezioni
Sopprimere un’eccezione senza alcuna azione può portare a comportamenti imprevedibili. Se un’eccezione viene catturata, dovrebbe essere gestita in modo appropriato o almeno registrata per scopi di logging.
Esempio da evitare:
try {
// Codice che potrebbe lanciare un'eccezione
} catch (Exception e) {
// Non fare nulla
}4.4.3 Fornire Messaggi di Errore Significativi
Quando si lanciano o si catturano eccezioni, fornire messaggi di errore chiari e informativi che aiutino a comprendere il contesto dell’errore.
Esempio:
throw new IllegalArgumentException("L'ID utente non può essere nullo o vuoto.");4.4.4 Evitare l’Uso delle Eccezioni per il Controllo del Flusso
Le eccezioni dovrebbero essere utilizzate per gestire situazioni anomale, non per controllare il flusso normale dell’applicazione. Utilizzare strutture di controllo come if-else o switch per la logica ordinaria.
Esempio da evitare:
try {
int value = Integer.parseInt(input);
} catch (NumberFormatException e) {
// Usare l'eccezione per controllo del flusso
}Approccio corretto:
if (isNumeric(input)) {
int value = Integer.parseInt(input);
} else {
// Gestione dell'input non numerico
}4.4.5 Pulire le Risorse con Try-with-Resources
Assicurarsi che le risorse come file o connessioni al database vengano chiuse correttamente utilizzando il blocco try-with-resources, introdotto in Java 7. Questo garantisce la chiusura automatica delle risorse, riducendo il rischio di perdite.
Esempio:
try (BufferedReader br = new BufferedReader(new FileReader("file.txt"))) {
// Lettura del file
} catch (IOException e) {
// Gestione dell'eccezione
}4.4.6 Rilanciare Eccezioni con Informazioni Aggiuntive
Se catturi un’eccezione ma non puoi gestirla completamente, rilanciala aggiungendo informazioni contestuali per facilitare il debugging a livelli superiori.
Esempio:
try {
// Codice che può lanciare SQLException
} catch (SQLException e) {
throw new DataAccessException("Errore durante l'accesso al database per l'utente ID " + userId, e);
}4.4.7 Documentare le Eccezioni con Javadoc
Utilizzare i commenti Javadoc per documentare le eccezioni che un metodo può lanciare. Questo migliora la leggibilità del codice e aiuta altri sviluppatori a comprendere meglio le possibili situazioni di errore.
Esempio:
/**
* Calcola la radice quadrata di un numero.
*
* @param number il numero di cui calcolare la radice quadrata
* @return la radice quadrata del numero
* @throws IllegalArgumentException se il numero è negativo
*/
public double sqrt(double number) {
if (number < 0) {
throw new IllegalArgumentException("Il numero deve essere non negativo.");
}
return Math.sqrt(number);
}4.4.8 Limitare il Codice nel Blocco try
Includere nel blocco try solo il codice che può realmente lanciare un’eccezione che si intende catturare. Questo rende il codice più leggibile e riduce il rischio di catturare eccezioni inattese.
Esempio:
// Codice non suscettibile di lanciare IOException
prepareData();
try {
writeDataToFile(data);
} catch (IOException e) {
// Gestione dell'eccezione
}4.4.9 Evitare di Catturare e Rilanciare Senza Motivo
Catturare un’eccezione solo per rilanciarla immediatamente senza aggiungere alcuna informazione non apporta alcun beneficio ed è ridondante.
Esempio da evitare:
try {
// Codice che può lanciare un'eccezione
} catch (IOException e) {
throw e;
}4.4.10 Utilizzare Logging Appropriato
Registrare le eccezioni utilizzando un framework di logging affidabile. Questo aiuta a monitorare il comportamento dell’applicazione e a identificare rapidamente i problemi.
Esempio con SLF4J:
private static final Logger logger = LoggerFactory.getLogger(NomeClasse.class);
try {
// Codice che può lanciare un'eccezione
} catch (IOException e) {
logger.error("Errore durante la lettura del file", e);
}4.4.11 Creare Eccezioni Personalizzate Solo Quando Necessario
Le eccezioni personalizzate dovrebbero essere create solo se aggiungono valore significativo rispetto alle eccezioni esistenti. Assicurarsi che il nome dell’eccezione sia chiaro e descrittivo.
Esempio:
public class SaldoInsufficienteException extends Exception {
public SaldoInsufficienteException(String message) {
super(message);
}
}4.4.12 Non Esponere Informazioni Sensibili
Quando si gestiscono eccezioni, evitare di esporre informazioni sensibili come dettagli interni del sistema o dati personali. Questo è particolarmente importante in applicazioni web accessibili pubblicamente.
Esempio da evitare:
throw new SQLException("Impossibile connettersi al database con l'utente 'admin' e la password 'password123'.");4.4.13 Conclusione
Una gestione efficace delle eccezioni è essenziale per sviluppare applicazioni Java di alta qualità. Seguendo queste best practices, si può migliorare la robustezza del codice, facilitare il processo di debugging e offrire un’esperienza migliore agli utenti finali. Ricorda che una buona gestione degli errori non riguarda solo la prevenzione dei crash, ma anche la comunicazione chiara e utile su ciò che è andato storto.
Capitolo 5: Collezioni e Generics
5.1 Il Framework delle Collezioni Java
Il Framework delle Collezioni Java è una componente fondamentale del linguaggio che offre un insieme di interfacce e classi per gestire in modo efficiente gruppi di oggetti. Introdotto a partire da Java 1.2, questo framework fornisce implementazioni standard per strutture dati comuni come liste, set, mappe e code, semplificando lo sviluppo e migliorando la qualità del codice.
Perché usare il Framework delle Collezioni?
Prima dell’esistenza del framework, gli sviluppatori dovevano implementare manualmente le proprie strutture dati o utilizzare array, che sono limitati e poco flessibili. Il Framework delle Collezioni risolve questi problemi offrendo:
-
Consistenza: Un insieme standard di interfacce e classi per strutture dati comuni.
-
Riutilizzabilità: Implementazioni pronte all’uso che possono essere facilmente integrate nelle applicazioni.
-
Efficienza: Algoritmi ottimizzati per operazioni come ricerca, inserimento e rimozione.
-
Manutenibilità: Codice più leggibile e facile da mantenere grazie all’uso di interfacce e generics.
5.1.1 Liste (List)
Una List è una collezione ordinata che può contenere elementi duplicati. Gli elementi sono accessibili tramite indice, permettendo un controllo preciso sulla loro posizione.
Interfaccia principale:
public interface List<E> extends Collection<E>Implementazioni comuni:
-
ArrayList<E>: Basata su un array dinamico. -
LinkedList<E>: Basata su una lista doppiamente collegata. -
Vector<E>: Simile adArrayList, ma sincronizzata (obsoleta). -
Stack<E>: EstendeVector, implementa una pila LIFO (obsoleta).
Quando usare una List?
-
Quando l’ordine degli elementi è importante.
-
Quando si ha bisogno di accesso casuale tramite indice.
-
Quando sono permessi elementi duplicati.
Esempio: Uso di ArrayList
List<String> studenti = new ArrayList<>();
studenti.add("Alice");
studenti.add("Bob");
studenti.add("Charlie");
// Accesso tramite indice
String primoStudente = studenti.get(0);
System.out.println("Il primo studente è: " + primoStudente);
// Iterazione
for (String studente : studenti) {
System.out.println(studente);
}Differenze tra ArrayList e LinkedList:
-
ArrayList è ottimale per operazioni di lettura (accesso casuale) ma meno efficiente per inserimenti/rimozioni nel mezzo della lista.
-
LinkedList è più efficiente per inserimenti/rimozioni in qualsiasi posizione ma meno efficiente nell’accesso casuale agli elementi.
5.1.2 Set
Un Set è una collezione che non permette elementi duplicati. È utile quando si desidera mantenere una collezione di elementi unici senza preoccuparsi dell’ordine.
Interfaccia principale:
public interface Set<E> extends Collection<E>Implementazioni comuni:
-
HashSet<E>: Basato su una tabella hash, non garantisce l’ordine. -
LinkedHashSet<E>: Mantiene l’ordine di inserimento. -
TreeSet<E>: Mantiene gli elementi ordinati secondo l’ordine naturale o un comparatore.
Quando usare un Set?
-
Quando si ha bisogno di una collezione di elementi unici.
-
Quando l’ordine degli elementi non è una priorità (a meno che non si usi
LinkedHashSetoTreeSet).
Esempio: Uso di HashSet
Set<String> colori = new HashSet<>();
colori.add("Rosso");
colori.add("Verde");
colori.add("Blu");
colori.add("Rosso"); // Duplicato, non verrà aggiunto
for (String colore : colori) {
System.out.println(colore);
}Nota: L’output potrebbe non rispettare l’ordine di inserimento.
5.1.3 Mappe (Map)
Una Map è una struttura dati che associa chiavi a valori. Ogni chiave è unica e mappa a un singolo valore.
Interfaccia principale:
public interface Map<K, V>Implementazioni comuni:
-
HashMap<K, V>: Non garantisce l’ordine delle chiavi. -
LinkedHashMap<K, V>: Mantiene l’ordine di inserimento delle chiavi. -
TreeMap<K, V>: Ordina le chiavi secondo l’ordine naturale o un comparatore.
Quando usare una Map?
-
Quando si ha bisogno di una relazione chiave-valore.
-
Quando si desidera accedere rapidamente ai valori tramite chiavi uniche.
Esempio: Uso di HashMap
Map<String, Integer> popolazioneCittà = new HashMap<>();
popolazioneCittà.put("Roma", 2873000);
popolazioneCittà.put("Milano", 1366000);
popolazioneCittà.put("Napoli", 962000);
// Accesso al valore tramite chiave
int popolazioneRoma = popolazioneCittà.get("Roma");
System.out.println("Popolazione di Roma: " + popolazioneRoma);
// Iterazione delle chiavi e valori
for (Map.Entry<String, Integer> entry : popolazioneCittà.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}5.1.4 Code (Queue)
Una Queue è una collezione utilizzata per mantenere elementi in ordine per l’elaborazione, tipicamente seguendo il principio FIFO (First-In, First-Out).
Interfaccia principale:
public interface Queue<E> extends Collection<E>Implementazioni comuni:
-
LinkedList<E>: Implementa siaListcheQueue. -
PriorityQueue<E>: Gli elementi vengono ordinati secondo l’ordine naturale o un comparatore. -
ArrayDeque<E>: Implementa una coda doppia (Deque), permette inserimenti e rimozioni efficienti sia dalla testa che dalla coda.
Quando usare una Queue?
-
Quando si ha bisogno di elaborare elementi nell’ordine in cui sono stati inseriti.
-
Per implementare algoritmi che richiedono una struttura FIFO.
Esempio: Uso di LinkedList come Queue
Queue<String> codaClienti = new LinkedList<>();
codaClienti.add("Cliente1");
codaClienti.add("Cliente2");
codaClienti.add("Cliente3");
// Elaborazione della coda
while (!codaClienti.isEmpty()) {
String cliente = codaClienti.poll();
System.out.println("Servendo: " + cliente);
}5.1.5 Interfacce e Implementazioni
Il Framework delle Collezioni separa le interfacce dalle implementazioni, permettendo di cambiare l’implementazione sottostante senza modificare il codice che la utilizza.
Programmare per le interfacce:
List<String> lista = new ArrayList<>();
// Cambiando l'implementazione
lista = new LinkedList<>();Questo approccio aumenta la flessibilità e facilita la manutenzione del codice.
5.1.6 Vantaggi delle Collezioni rispetto agli Array
-
Dimensione Dinamica: Le collezioni possono crescere o ridursi dinamicamente, mentre gli array hanno dimensione fissa.
-
Metodi Utility: Le collezioni offrono metodi per inserire, rimuovere, cercare e ordinare gli elementi.
-
Tipi Parametrizzati (Generics): Migliorano la sicurezza del tipo e riducono la necessità di cast espliciti.
-
Interoperabilità: Le collezioni possono essere facilmente combinate e manipolate grazie alle interfacce comuni.
5.1.7 Best Practices
-
Scegliere l’implementazione giusta: Ad esempio, usare
ArrayListper accesso casuale rapido oLinkedListper inserimenti/rimozioni frequenti. -
Evitare le sincronizzazioni non necessarie: Le collezioni del pacchetto
java.util.concurrentdovrebbero essere usate in ambienti multi-thread. -
Usare i Generics: Per evitare errori di tipo e aumentare la leggibilità del codice.
-
Programmare contro le interfacce: Aumenta la flessibilità e permette di cambiare facilmente l’implementazione sottostante.
5.1.8 Esempio Pratico: Gestione di un Registro Studenti
Supponiamo di voler gestire un registro studenti che tiene traccia dei corsi a cui ogni studente è iscritto.
Implementazione con Map e Set:
Map<String, Set<String>> registroStudenti = new HashMap<>();
// Aggiungere corsi per uno studente
void aggiungiCorso(String studente, String corso) {
registroStudenti.computeIfAbsent(studente, k -> new HashSet<>()).add(corso);
}
// Ottenere i corsi di uno studente
Set<String> getCorsi(String studente) {
return registroStudenti.getOrDefault(studente, Collections.emptySet());
}
// Uso delle funzioni
aggiungiCorso("Alice", "Matematica");
aggiungiCorso("Alice", "Fisica");
aggiungiCorso("Bob", "Chimica");
System.out.println("Corsi di Alice: " + getCorsi("Alice"));Conclusione
Il Framework delle Collezioni Java è essenziale per qualsiasi sviluppatore Java. Comprendere le differenze tra le varie interfacce e implementazioni ti permette di scegliere la struttura dati più appropriata per il tuo caso d’uso, migliorando l’efficienza e la manutenibilità del tuo codice. Nel prossimo capitolo, esploreremo come i Generics si integrano con le collezioni per offrire maggiore flessibilità e sicurezza dei tipi.
5.2 Utilizzo dei Generics
I Generics rappresentano una delle evoluzioni più significative introdotte in Java 5. Essi consentono di definire classi, interfacce e metodi parametrizzati da tipi, migliorando notevolmente la sicurezza del codice e la sua riusabilità.
Perché sono stati introdotti i Generics?
Prima dell’introduzione dei Generics, le collezioni in Java gestivano gli oggetti come tipi Object. Questo significava che era possibile inserire qualsiasi tipo di oggetto in una collezione, ma al momento del recupero era necessario effettuare un cast esplicito, con il rischio di incorrere in errori di runtime come ClassCastException.
Esempio senza Generics:
List list = new ArrayList();
list.add("Testo");
list.add(123); // Possibile inserire un Integer
String elemento = (String) list.get(1); // Lancia ClassCastExceptionI Generics sono stati introdotti per:
-
Migliorare la sicurezza del tipo a tempo di compilazione: Il compilatore può verificare che solo oggetti di un determinato tipo vengano inseriti in una collezione.
-
Eliminare la necessità di cast espliciti: Riducendo la verbosità e il rischio di errori.
-
Favorire la riusabilità del codice: Consentendo la scrittura di classi e metodi che funzionano con qualsiasi tipo di dato.
Vantaggi dei Tipi Parametrizzati
-
Sicurezza del Tipo a Tempo di Compilazione
Con i Generics, il compilatore controlla i tipi, prevenendo l’inserimento di oggetti incompatibili.
Esempio con Generics:
List<String> list = new ArrayList<>(); list.add("Testo"); // list.add(123); // Errore di compilazione -
Eliminazione dei Cast Espliciti
Non è più necessario effettuare cast quando si recuperano elementi da una collezione generica.
String elemento = list.get(0); // Nessun cast necessario -
Codice Riutilizzabile e Flessibile
I Generics permettono di scrivere codice generico che può funzionare con diversi tipi di dati, senza duplicazione del codice.
Come Definire e Utilizzare i Generics
Classi Generiche
Una classe generica è definita utilizzando un parametro di tipo:
public class Box<T> {
private T contenuto;
public void set(T contenuto) {
this.contenuto = contenuto;
}
public T get() {
return contenuto;
}
}Utilizzo della classe generica:
Box<String> boxStringa = new Box<>();
boxStringa.set("Ciao");
String messaggio = boxStringa.get();
Box<Integer> boxIntero = new Box<>();
boxIntero.set(10);
Integer numero = boxIntero.get();Metodi Generici
Anche i metodi possono essere generici, indipendentemente dal fatto che la classe sia generica o meno.
public class Utility {
public static <T> void stampaArray(T[] array) {
for (T elemento : array) {
System.out.println(elemento);
}
}
}Utilizzo del metodo generico:
String[] parole = {"Ciao", "Mondo"};
Utility.stampaArray(parole);
Integer[] numeri = {1, 2, 3};
Utility.stampaArray(numeri);Interfacce Generiche
Le interfacce possono essere parametrizzate allo stesso modo delle classi.
public interface Comparable<T> {
int compareTo(T o);
}Bounded Types (Tipi Limitati)
I Generics possono essere limitati a sottotipi o supertipi specifici utilizzando le parole chiave extends e super.
Limite Superiore con extends
Consente di specificare che un tipo parametrizzato deve essere una sottoclasse di un determinato tipo.
public class NumeroBox<T extends Number> {
private T numero;
public void set(T numero) {
this.numero = numero;
}
public T get() {
return numero;
}
}Utilizzo:
NumeroBox<Integer> boxInt = new NumeroBox<>();
boxInt.set(5);
NumeroBox<Double> boxDouble = new NumeroBox<>();
boxDouble.set(5.5);
// NumeroBox<String> boxString = new NumeroBox<>(); // Errore di compilazioneLimite Inferiore con super
Utilizzato principalmente con le wildcard per consentire maggiore flessibilità nei tipi accettati.
Wildcard (?)
Le wildcard rappresentano un tipo sconosciuto e sono utili per aumentare la flessibilità dei Generics.
-
?: Tipo sconosciuto. -
? extends T: Qualsiasi tipo che estendeT. -
? super T: Qualsiasi tipo che è supertipo diT.
Esempio con ? extends:
public void stampaNumeri(List<? extends Number> lista) {
for (Number numero : lista) {
System.out.println(numero);
}
}Esempio con ? super:
public void aggiungiNumero(List<? super Integer> lista) {
lista.add(10);
}Erasure dei Tipi
A differenza di altri linguaggi, Java implementa i Generics utilizzando l’erasure dei tipi. Questo significa che le informazioni sui tipi generici sono disponibili solo a tempo di compilazione e vengono rimosse a tempo di esecuzione.
Conseguenze dell’erasure dei tipi:
-
Non è possibile usare tipi primitivi come parametri generici: Ad esempio,
List<int>non è valido; bisogna usareList<Integer>. -
Non è possibile creare istanze di tipi generici: Non si può fare
T obj = new T();. -
Non è possibile usare gli operatori
instanceofcon tipi parametrizzati:if (obj instanceof List<String>)non è valido.
Best Practices nell’Uso dei Generics
-
Specificare Sempre il Tipo Parametrizzato
Evitare l’uso di raw types (tipi grezzi) come
Listsenza specificare il tipo.List<String> list = new ArrayList<>(); -
Preferire le Wildcard quando Appropriato
Le wildcard rendono le API più flessibili.
public void processaLista(List<?> lista) { // Operazioni sulla lista } -
Evitare di Usare Eccessivamente le Wildcard
Possono rendere il codice più complesso e difficile da leggere.
-
Comprendere le Limitazioni dei Generics con l’Erasure dei Tipi
Essere consapevoli delle limitazioni per evitare errori di progettazione.
-
Utilizzare Bounded Types per Limitare i Tipi Accettati
Migliora la sicurezza e la coerenza del codice.
Esempio Pratico Completo
Supponiamo di voler creare una classe che rappresenta una coppia di elementi.
public class Coppia<T, U> {
private T primo;
private U secondo;
public Coppia(T primo, U secondo) {
this.primo = primo;
this.secondo = secondo;
}
public T getPrimo() {
return primo;
}
public U getSecondo() {
return secondo;
}
}Utilizzo della classe Coppia:
Coppia<String, Integer> coppia = new Coppia<>("Età", 30);
System.out.println(coppia.getPrimo() + ": " + coppia.getSecondo());Output:
Età: 30
Conclusione
I Generics sono uno strumento fondamentale nel moderno sviluppo Java. Essi migliorano la sicurezza del tipo, riducono la necessità di cast espliciti e rendono il codice più flessibile e riutilizzabile. Comprendere come definire e utilizzare i Generics è essenziale per scrivere codice robusto e mantenibile, sia per progetti semplici che complessi.
Approfondimenti:
-
Generics e Collezioni
Le collezioni del framework Java (come
List,Set,Map) sono tutte parametrizzate con Generics, il che consente di specificare il tipo di elementi che possono contenere. -
Generics e Interfacce Funzionali
Con l’introduzione delle espressioni lambda in Java 8, i Generics sono diventati ancora più importanti per definire interfacce funzionali tipizzate.
-
Generics e Programmazione Avanzata
Nei contesti avanzati, i Generics possono essere combinati con altre funzionalità come le annotazioni, la riflessione e le espressioni lambda per creare API potenti e flessibili.
Domande per Verificare la Comprensione:
-
Perché i Generics non supportano i tipi primitivi come
intodouble?Risposta: Perché i Generics in Java funzionano con le classi e gli oggetti, non con i tipi primitivi. Si devono usare le classi wrapper come
IntegeroDouble. -
Cosa rappresenta la wildcard
?nei Generics?Risposta: Rappresenta un tipo sconosciuto, utilizzato per aumentare la flessibilità dei metodi e delle classi generiche.
-
Qual è la differenza tra
List<? extends Number>eList<? super Number>?Risposta:
List<? extends Number>accetta liste di oggetti che sono sottotipi diNumber, mentreList<? super Number>accetta liste di oggetti che sono supertipi diNumber.
Esercizi Pratici:
-
Implementare una classe generica
Pair<T>che contiene due elementi dello stesso tipo e fornisce metodi per recuperarli. -
Scrivere un metodo generico che prende una lista di qualsiasi tipo e stampa gli elementi se il tipo è
Numbero sua sottoclasse. -
Creare una classe generica con un limite superiore che accetta solo tipi che implementano un’interfaccia personalizzata, ad esempio
Comparable.
Praticare l’uso dei Generics attraverso esempi concreti e risoluzione di problemi aiuterà a consolidare la comprensione e a prepararsi per situazioni reali nello sviluppo di applicazioni Java.
5.3 Iteratori e Stream
La gestione efficace delle collezioni è fondamentale per qualsiasi programmatore Java. Due strumenti potenti che Java offre per navigare e manipolare le collezioni sono gli Iteratori e gli Stream. In questa sezione, esploreremo in dettaglio entrambi, comprendendo le loro differenze, vantaggi e scenari d’uso ideali.
5.3.1 Iteratori
Cos’è un Iteratore
Un Iteratore è un oggetto che permette di attraversare una collezione elemento per elemento senza esporre la sua rappresentazione sottostante. Fornisce metodi per controllare la presenza di elementi successivi e per accedere agli elementi stessi.
Utilizzo degli Iteratori
Per utilizzare un iteratore, si richiama il metodo iterator() sulla collezione desiderata. Ecco un esempio pratico:
List<String> nomi = new ArrayList<>();
nomi.add("Alice");
nomi.add("Bob");
nomi.add("Charlie");
Iterator<String> iteratore = nomi.iterator();
while (iteratore.hasNext()) {
String nome = iteratore.next();
System.out.println(nome);
}Spiegazione:
-
hasNext(): verifica se c’è un elemento successivo nell’iterazione. -
next(): restituisce l’elemento successivo.
Modifica della Collezione Durante l’Iterazione
Gli iteratori forniscono anche il metodo remove() per rimuovere elementi durante l’iterazione in modo sicuro:
Iterator<String> iteratore = nomi.iterator();
while (iteratore.hasNext()) {
String nome = iteratore.next();
if (nome.equals("Bob")) {
iteratore.remove();
}
}Attenzione: Modificare una collezione durante l’iterazione senza utilizzare l’iteratore stesso per la modifica può causare una ConcurrentModificationException.
Perché Usare gli Iteratori
-
Incapsulamento: Nascondono i dettagli dell’implementazione della collezione.
-
Sicurezza: Consentono di modificare la collezione in modo sicuro durante l’iterazione.
-
Flessibilità: Possono essere utilizzati su qualsiasi collezione che implementi l’interfaccia
Iterable.
5.3.2 Introduzione agli Stream
Introdotti in Java 8, gli Stream offrono un modo funzionale e dichiarativo per elaborare collezioni di dati. Consentono di eseguire operazioni aggregate come filtraggio, mappatura e riduzione.
Creazione di uno Stream
Uno stream può essere creato a partire da una collezione chiamando il metodo stream():
List<String> nomi = Arrays.asList("Alice", "Bob", "Charlie");
Stream<String> streamNomi = nomi.stream();Operazioni su Stream
Gli stream supportano due tipi di operazioni:
-
Intermedie: Restituiscono un nuovo stream e sono lazy, ovvero vengono eseguite solo quando necessario. Esempi:
filter(),map(),sorted(). -
Terminali: Producono un risultato o un effetto collaterale e terminano la catena di elaborazione. Esempi:
forEach(),collect(),reduce().
Esempio di Utilizzo:
List<String> nomi = Arrays.asList("Alice", "Bob", "Charlie", "David");
nomi.stream()
.filter(nome -> nome.startsWith("C"))
.map(String::toUpperCase)
.forEach(System.out::println);Spiegazione:
-
filter(): Seleziona elementi che soddisfano una condizione. -
map(): Trasforma ogni elemento in un altro oggetto. -
forEach(): Esegue un’azione per ogni elemento.
Output:
CHARLIE
Vantaggi degli Stream
-
Concisione: Codice più breve e leggibile.
-
Parallelismo: Facile implementazione di operazioni in parallelo con
parallelStream(). -
Immutabilità: Non modificano la collezione originale.
Operazioni Avanzate
-
collect(): Raccoglie gli elementi in una collezione o altro contenitore.List<String> nomiConA = nomi.stream() .filter(nome -> nome.contains("a")) .collect(Collectors.toList()); -
reduce(): Riduce gli elementi a un singolo valore.int sommaLunghezze = nomi.stream() .map(String::length) .reduce(0, Integer::sum);
5.3.3 Confronto tra Iteratori e Stream
parallelStream()5.3.4 Quando Utilizzare Iteratori o Stream
-
Usa gli Iteratori quando:
-
Hai bisogno di modificare la collezione durante l’iterazione.
-
L’operazione è semplice e non richiede elaborazioni complesse.
-
Stai lavorando con API o ambienti che non supportano Java 8 o versioni successive.
-
-
Usa gli Stream quando:
-
Devi eseguire operazioni complesse o catene di operazioni.
-
Vuoi scrivere codice più conciso e leggibile.
-
Vuoi sfruttare il parallelismo per migliorare le prestazioni.
-
Stai aderendo a uno stile di programmazione funzionale.
-
5.3.5 Esempio Completo
Supponiamo di avere una lista di oggetti Persona e vogliamo ottenere una lista dei nomi in maiuscolo delle persone maggiorenni, ordinati alfabeticamente.
Definizione della classe Persona:
public class Persona {
private String nome;
private int eta;
// Costruttore, getter e setter
}Soluzione con Iteratori:
List<Persona> persone = // inizializzazione;
List<String> nomiMaggiorenni = new ArrayList<>();
Iterator<Persona> iteratore = persone.iterator();
while (iteratore.hasNext()) {
Persona persona = iteratore.next();
if (persona.getEta() >= 18) {
nomiMaggiorenni.add(persona.getNome().toUpperCase());
}
}
Collections.sort(nomiMaggiorenni);Soluzione con Stream:
List<String> nomiMaggiorenni = persone.stream()
.filter(p -> p.getEta() >= 18)
.map(p -> p.getNome().toUpperCase())
.sorted()
.collect(Collectors.toList());Analisi:
-
La soluzione con gli Iteratori richiede più codice boilerplate e operazioni manuali come l’aggiunta alla lista e l’ordinamento.
-
La soluzione con gli Stream è più concisa e dichiarativa, esprimendo chiaramente l’intento dell’operazione.
5.3.6 Considerazioni sulle Prestazioni
-
Iteratori: Hanno prestazioni prevedibili e costanti, ma meno ottimizzazioni.
-
Stream: Possono essere più lenti in operazioni semplici a causa dell’overhead, ma offrono ottimizzazioni come il lazy evaluation e il parallelismo.
Nota: È importante profilare il proprio codice se le prestazioni sono critiche, poiché il comportamento può variare in base al caso d’uso specifico.
5.3.7 Conclusione
Comprendere quando e come utilizzare gli Iteratori e gli Stream è essenziale per scrivere codice Java efficiente e manutenibile. Mentre gli iteratori offrono un controllo più fine durante l’iterazione, gli stream forniscono un approccio più moderno e funzionale alla manipolazione dei dati.
5.4 Confronto tra Collezioni
La scelta della collezione appropriata è fondamentale per la scrittura di un codice efficiente e manutenibile. Ogni implementazione delle interfacce delle collezioni in Java offre caratteristiche uniche in termini di prestazioni, ordine degli elementi e comportamento. In questa sezione, confronteremo le principali implementazioni di List, Set, Map e Queue, analizzando le loro prestazioni e i contesti d’uso ideali.
5.4.1 Liste
Le liste sono collezioni ordinate che permettono elementi duplicati. Le implementazioni più comuni sono ArrayList e LinkedList.
ArrayList
-
Struttura interna: Basata su un array dinamico.
-
Prestazioni:
-
Accesso casuale (
get(index)) O(1). -
Inserimento/Rimozione in coda O(1) (amortizzato).
-
Inserimento/Rimozione in posizione intermedia O(n).
-
-
Uso ideale: Quando si ha bisogno di un accesso rapido agli elementi e le operazioni di inserimento/rimozione sono principalmente alla fine della lista.
LinkedList
-
Struttura interna: Lista doppiamente collegata.
-
Prestazioni:
-
Accesso casuale (
get(index)) O(n). -
Inserimento/Rimozione all’inizio O(1).
-
Inserimento/Rimozione in posizione intermedia O(n) (necessità di navigare fino al punto).
-
-
Uso ideale: Quando le operazioni frequenti sono inserimenti e rimozioni all’inizio o alla fine della lista e l’accesso casuale non è frequente.
Esempio di Scelta
Se stai implementando una pila (stack) dove le operazioni principali sono push e pop in cima alla lista, LinkedList potrebbe essere più efficiente. Tuttavia, per una lista che richiede accesso frequente agli elementi tramite indice, ArrayList è la scelta migliore.
5.4.2 Set
I set sono collezioni che non permettono elementi duplicati. Le implementazioni principali sono HashSet, LinkedHashSet e TreeSet.
HashSet
-
Struttura interna: Basata su una tabella hash.
-
Prestazioni:
- Operazioni di base (add, remove, contains) O(1).
-
Uso ideale: Quando l’ordine degli elementi non è importante e si necessita di operazioni rapide.
LinkedHashSet
-
Struttura interna: Combina una tabella hash con una lista doppiamente collegata.
-
Prestazioni:
- Operazioni di base O(1).
-
Uso ideale: Quando si vuole mantenere l’ordine di inserimento degli elementi.
TreeSet
-
Struttura interna: Basata su un albero rosso-nero (Red-Black Tree).
-
Prestazioni:
- Operazioni di base O(log n).
-
Uso ideale: Quando è necessario mantenere gli elementi ordinati in modo naturale o secondo un comparatore personalizzato.
Esempio di Scelta
Se devi gestire un insieme di ID univoci dove l’ordine non conta, HashSet è efficiente. Se invece devi mantenere gli elementi ordinati per una ricerca successiva, TreeSet è appropriato, nonostante le prestazioni leggermente inferiori.
5.4.3 Mappe
Le mappe sono collezioni che mappano chiavi a valori. Le implementazioni comuni includono HashMap, LinkedHashMap, TreeMap e ConcurrentHashMap.
HashMap
-
Struttura interna: Tabella hash.
-
Prestazioni:
- Operazioni di base (put, get) O(1).
-
Uso ideale: Quando si necessita di una mappatura rapida e l’ordine delle chiavi non è rilevante.
LinkedHashMap
-
Struttura interna: Tabella hash con lista doppiamente collegata.
-
Prestazioni:
- Operazioni di base O(1).
-
Uso ideale: Quando si vuole mantenere l’ordine di inserimento o l’ordine di accesso (implementando una cache LRU).
TreeMap
-
Struttura interna: Albero rosso-nero.
-
Prestazioni:
- Operazioni di base O(log n).
-
Uso ideale: Quando è necessario che le chiavi siano ordinate.
ConcurrentHashMap
-
Struttura interna: Tabella hash segmentata per supportare la concorrenza.
-
Prestazioni:
- Operazioni di base O(1) in contesti concorrenti.
-
Uso ideale: In applicazioni multithreaded dove più thread accedono e modificano la mappa simultaneamente.
Esempio di Scelta
Per una semplice mappatura di configurazioni dove l’accesso concorrente non è un problema, HashMap è sufficiente. In un server web che gestisce sessioni utente in modo concorrente, ConcurrentHashMap è essenziale per evitare problemi di sincronizzazione.
5.4.4 Code e Deque
Le code (Queue) gestiscono elementi in base a una politica FIFO (First-In-First-Out), mentre le Deque (Double-Ended Queue) permettono l’inserimento e la rimozione di elementi da entrambe le estremità.
PriorityQueue
-
Struttura interna: Basata su un heap binario.
-
Prestazioni:
-
Inserimento O(log n).
-
Rimozione dell’elemento minimo O(log n).
-
-
Uso ideale: Quando si necessita di una coda con priorità, dove gli elementi vengono ordinati in base a un ordine naturale o a un comparatore.
ArrayDeque
-
Struttura interna: Array ridimensionabile.
-
Prestazioni:
- Operazioni di inserimento/rimozione alle estremità O(1).
-
Uso ideale: Come stack o coda, quando si necessita di operazioni veloci alle estremità e non si richiede la sincronizzazione.
LinkedList (come implementazione di Queue e Deque)
-
Struttura interna: Lista doppiamente collegata.
-
Prestazioni:
- Operazioni di inserimento/rimozione alle estremità O(1).
-
Uso ideale: Simile ad ArrayDeque, ma con un overhead leggermente maggiore a causa dell’allocazione di nodi individuali.
Esempio di Scelta
Per gestire una coda di task ordinati per priorità, come in un scheduler, PriorityQueue è appropriata. Per una semplice coda FIFO senza necessità di sincronizzazione, ArrayDeque offre prestazioni migliori rispetto a LinkedList.
5.4.5 Tabelle di Prestazioni
Per facilitare il confronto, ecco una tabella riassuntiva delle complessità delle operazioni comuni per le principali collezioni:
5.4.6 Considerazioni sulla Sincronizzazione
Le collezioni descritte finora non sono thread-safe. In ambienti multithreaded, è importante utilizzare collezioni sincronizzate come quelle fornite nel pacchetto java.util.concurrent (ad esempio, ConcurrentHashMap, CopyOnWriteArrayList).
ConcurrentHashMap
- Uso ideale: Sostituisce HashMap in contesti concorrenti senza il costo della sincronizzazione completa.
CopyOnWriteArrayList
- Uso ideale: Quando le letture sono frequenti e le scritture rare; crea una nuova copia dell’array interno ad ogni modifica.
Esempio di Scelta
In un’applicazione dove più thread leggono frequentemente una lista di configurazioni che cambiano raramente, CopyOnWriteArrayList offre letture non bloccanti e aggiornamenti sicuri.
5.4.7 Best Practices nella Scelta delle Collezioni
-
Conosci il tuo caso d’uso: La scelta dipende dalle operazioni più frequenti (inserimento, rimozione, accesso casuale) e dalla necessità di ordine o unicità.
-
Considera le prestazioni: Utilizza le complessità temporali come guida, ma ricorda che fattori come la costante nascosta e l’overhead possono influenzare le prestazioni reali.
-
Evita il sovrautilizzo di memoria: Alcune collezioni, come LinkedList, hanno un overhead maggiore in termini di memoria.
-
Pensa alla concorrenza: In ambienti multithreaded, utilizza collezioni thread-safe o sincronizza adeguatamente l’accesso.
5.4.8 Conclusione
Comprendere le differenze tra le varie implementazioni delle collezioni in Java è essenziale per scrivere codice efficiente e scalabile. La scelta della collezione giusta influisce non solo sulle prestazioni ma anche sulla correttezza e manutenibilità dell’applicazione. Prenditi il tempo per analizzare le esigenze specifiche del tuo progetto e scegli la collezione che meglio si adatta ai tuoi requisiti.
Capitolo 6: Input/Output e Gestione dei File
6.1 Stream di I/O
L’input/output (I/O) è una componente fondamentale in Java, poiché permette alle applicazioni di interagire con il mondo esterno, leggendo dati da sorgenti diverse e scrivendo dati verso destinazioni come file, console o reti. Il concetto chiave per gestire queste operazioni in Java è lo stream (flusso).
Concetti di Base
Uno stream in Java rappresenta una sequenza ordinata di dati. Si può pensare a uno stream come a un canale attraverso il quale fluiscono dati da una sorgente a una destinazione. Questa astrazione permette di leggere e scrivere dati senza preoccuparsi dei dettagli specifici del dispositivo fisico o del meccanismo di trasporto.
Gli stream in Java sono classificati principalmente in due categorie:
-
Stream di Byte: Gestiscono dati in formato binario (byte).
-
Stream di Caratteri: Gestiscono dati testuali (caratteri Unicode).
La distinzione è cruciale perché il modo in cui i dati binari e testuali vengono trattati può differire significativamente, specialmente in presenza di diverse codifiche di caratteri.
Stream di Byte
Gli stream di byte sono progettati per leggere e scrivere dati binari. Sono utilizzati quando si ha a che fare con dati che non rappresentano necessariamente testo, come immagini, file audio, video o altri formati binari.
Le classi base per gli stream di byte sono:
-
InputStream: Classe astratta per leggere dati in ingresso come byte. -
OutputStream: Classe astratta per scrivere dati in uscita come byte.
Principali Sottoclassi degli Stream di Byte
-
FileInputStream: Legge byte da un file. -
FileOutputStream: Scrive byte su un file. -
BufferedInputStreameBufferedOutputStream: Forniscono buffering per migliorare l’efficienza delle operazioni di I/O. -
DataInputStreameDataOutputStream: Permettono di leggere e scrivere tipi di dati Java primitivi in formato binario.
Esempio: Lettura di un File Binario
import java.io.FileInputStream;
import java.io.IOException;
public class LetturaBinaria {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("immagine.jpg")) {
int byteLetto;
while ((byteLetto = fis.read()) != -1) {
// Elaborazione del byte letto
System.out.print(byteLetto + " ");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo esempio, leggiamo un file immagine byte per byte. Il metodo read() restituisce un intero che rappresenta il byte letto, oppure -1 se si raggiunge la fine del file.
Stream di Caratteri
Gli stream di caratteri sono pensati per gestire dati testuali. Essi utilizzano la codifica Unicode, il che consente di rappresentare una vasta gamma di caratteri da diverse lingue e simboli.
Le classi base per gli stream di caratteri sono:
-
Reader: Classe astratta per leggere dati in ingresso come caratteri. -
Writer: Classe astratta per scrivere dati in uscita come caratteri.
Principali Sottoclassi degli Stream di Caratteri
-
FileReader: Legge caratteri da un file di testo. -
FileWriter: Scrive caratteri su un file di testo. -
BufferedReadereBufferedWriter: Forniscono buffering e metodi aggiuntivi comereadLine()per facilitare la lettura e scrittura. -
InputStreamReadereOutputStreamWriter: Collegano stream di byte a stream di caratteri, permettendo la conversione tra byte e caratteri.
Esempio: Lettura di un File di Testo
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class LetturaTesto {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new FileReader("documento.txt"))) {
String linea;
while ((linea = br.readLine()) != null) {
System.out.println(linea);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Qui utilizziamo BufferedReader per leggere il file linea per linea, il che è efficiente e comodo per la maggior parte delle operazioni su file di testo.
Perché Scegliere tra Byte e Caratteri?
La scelta tra stream di byte e di caratteri dipende dal tipo di dati che si sta manipolando:
-
Stream di Byte: Quando si lavora con dati binari o formati non testuali.
-
Stream di Caratteri: Quando si lavora con testo, beneficiando della gestione automatica delle codifiche dei caratteri.
Utilizzare lo stream appropriato garantisce che i dati vengano letti e scritti correttamente, evitando problemi come la corruzione dei dati o errori di codifica.
Conversione tra Byte e Caratteri
A volte è necessario convertire un stream di byte in un stream di caratteri, specialmente quando si legge da una sorgente binaria ma si desidera interpretare i dati come testo.
Esempio: Uso di InputStreamReader
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class LetturaDaConsole {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new InputStreamReader(System.in))) {
System.out.print("Inserisci il tuo nome: ");
String nome = br.readLine();
System.out.println("Ciao, " + nome + "!");
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo esempio, System.in è uno InputStream che legge byte dalla console. Utilizziamo InputStreamReader per convertirlo in un Reader di caratteri, e poi BufferedReader per leggere il testo in modo efficiente.
Buffering
Il buffering è una tecnica che migliora le prestazioni delle operazioni di I/O, riducendo il numero di accessi fisici al dispositivo di input/output. In Java, le classi di buffering come BufferedInputStream, BufferedOutputStream, BufferedReader e BufferedWriter avvolgono gli stream base per fornire questa funzionalità.
Esempio: Scrittura con Buffering
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class ScritturaConBuffer {
public static void main(String[] args) {
try (BufferedWriter bw = new BufferedWriter(new FileWriter("output.txt"))) {
bw.write("Prima linea di testo");
bw.newLine();
bw.write("Seconda linea di testo");
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo caso, BufferedWriter accumula i dati in un buffer interno e li scrive su disco in blocchi più grandi, migliorando l’efficienza.
Gestione delle Codifiche dei Caratteri
Quando si lavora con dati testuali, è fondamentale considerare la codifica dei caratteri per garantire che i dati vengano interpretati correttamente, specialmente quando si leggono o scrivono file che potrebbero essere stati creati su sistemi con impostazioni locali diverse.
Esempio: Specificare la Codifica
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
public class LetturaConCodifica {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(
new InputStreamReader(
new FileInputStream("testo_utf8.txt"), StandardCharsets.UTF_8))) {
String linea;
while ((linea = br.readLine()) != null) {
System.out.println(linea);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Qui specifichiamo esplicitamente la codifica UTF-8 per garantire che i caratteri vengano interpretati correttamente.
Pattern Decorator negli Stream di I/O
Le classi di I/O in Java spesso utilizzano il Pattern Decorator, permettendo di combinare funzionalità aggiuntive in modo flessibile. Questo approccio consente di estendere le capacità degli stream senza modificare le classi esistenti.
Esempio: Combinazione di Stream
import java.io.BufferedInputStream;
import java.io.DataInputStream;
import java.io.FileInputStream;
import java.io.IOException;
public class LetturaCombinata {
public static void main(String[] args) {
try (DataInputStream dis = new DataInputStream(
new BufferedInputStream(
new FileInputStream("dati.bin")))) {
int numero = dis.readInt();
double valore = dis.readDouble();
System.out.println("Numero intero: " + numero);
System.out.println("Valore double: " + valore);
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo esempio, combiniamo FileInputStream, BufferedInputStream e DataInputStream per leggere dati binari con buffering e metodi di lettura per tipi primitivi.
Eccezioni e Gestione delle Risorse
Le operazioni di I/O sono soggette a errori, come la mancanza del file o problemi di accesso. È importante gestire correttamente le eccezioni e assicurarsi che le risorse vengano chiuse.
Uso del Blocco try-with-resources
Il blocco try-with-resources introdotto in Java 7 semplifica la gestione delle risorse, assicurando che gli stream vengano chiusi automaticamente.
try (FileInputStream fis = new FileInputStream("file.txt")) {
// Operazioni di I/O
} catch (IOException e) {
e.printStackTrace();
}Riepilogo
-
Stream di Byte: Utilizzati per dati binari. Classi principali:
InputStream,OutputStream. -
Stream di Caratteri: Utilizzati per dati testuali. Classi principali:
Reader,Writer. -
Buffering: Migliora le prestazioni riducendo gli accessi fisici al disco.
-
Codifiche dei Caratteri: Specificate per garantire la corretta interpretazione dei dati testuali.
-
Pattern Decorator: Permette di estendere le funzionalità degli stream in modo flessibile.
-
Gestione delle Risorse: Il blocco
try-with-resourcesassicura la chiusura automatica degli stream.
Approfondimenti
Per diventare proficienti nella gestione degli stream di I/O in Java, è consigliabile:
-
Esplorare le diverse classi e capire le loro funzionalità specifiche.
-
Praticare con esempi che coinvolgono la lettura e scrittura di diversi tipi di dati.
-
Comprendere l’importanza delle codifiche dei caratteri, specialmente in applicazioni internazionali.
-
Studiare il funzionamento interno delle classi di buffering per ottimizzare le prestazioni.
La padronanza degli stream di I/O è essenziale per sviluppare applicazioni robuste e affidabili, in grado di interagire efficacemente con l’ambiente esterno.
6.2 Lettura e Scrittura di File
La capacità di leggere da e scrivere su file è una componente fondamentale di molte applicazioni Java. Che si tratti di salvare configurazioni, registrare log o elaborare grandi quantità di dati, una solida comprensione delle classi di I/O di Java è essenziale. In questa sezione, esploreremo come utilizzare FileReader, FileWriter, BufferedReader e BufferedWriter per effettuare operazioni di input/output su file di testo in modo efficiente e sicuro.
6.2.1 FileReader e FileWriter
6.2.1.1 Introduzione a FileReader e FileWriter
FileReader e FileWriter sono classi fornite dal pacchetto java.io e sono progettate per leggere e scrivere caratteri Unicode da e verso file di testo. Queste classi lavorano a un livello base, gestendo i caratteri uno alla volta, il che può essere sufficiente per operazioni semplici o file di dimensioni ridotte.
Esempio di utilizzo di FileWriter:
import java.io.FileWriter;
import java.io.IOException;
public class ScritturaFile {
public static void main(String[] args) {
try {
FileWriter writer = new FileWriter("output.txt");
writer.write("Ciao, mondo!");
writer.close();
System.out.println("Scrittura completata.");
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo esempio, FileWriter crea (o sovrascrive se esiste già) un file chiamato output.txt e vi scrive la stringa “Ciao, mondo!”.
Esempio di utilizzo di FileReader:
import java.io.FileReader;
import java.io.IOException;
public class LetturaFile {
public static void main(String[] args) {
try {
FileReader reader = new FileReader("output.txt");
int carattere;
while ((carattere = reader.read()) != -1) {
System.out.print((char) carattere);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}Questo codice legge il file output.txt carattere per carattere e lo stampa sulla console.
6.2.1.2 Considerazioni sull’uso di FileReader e FileWriter
Sebbene FileReader e FileWriter siano semplici da utilizzare, hanno alcune limitazioni:
-
Efficienza: Leggere e scrivere un carattere alla volta può essere inefficiente, soprattutto con file di grandi dimensioni.
-
Buffering: Non utilizzano buffering interno, il che significa che ogni chiamata a
read()owrite()può comportare un’operazione I/O fisica, rallentando le prestazioni.
Per ovviare a queste limitazioni, Java fornisce le classi BufferedReader e BufferedWriter.
6.2.2 BufferedReader e BufferedWriter
6.2.2.1 Introduzione a BufferedReader e BufferedWriter
BufferedReader e BufferedWriter sono classi wrapper che aggiungono funzionalità di buffering rispettivamente a un Reader e a un Writer. Il buffering riduce il numero di accessi fisici al disco, migliorando significativamente le prestazioni durante la lettura e la scrittura di file.
Vantaggi dell’utilizzo del buffering:
-
Prestazioni Migliorate: Riduce il numero di operazioni I/O, poiché i dati vengono letti e scritti in blocchi.
-
Metodi Aggiuntivi:
BufferedReaderfornisce metodi comereadLine(), che facilita la lettura di linee intere di testo.
6.2.2.2 Utilizzo di BufferedWriter
Ecco come scrivere su un file utilizzando BufferedWriter:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class ScritturaBuffered {
public static void main(String[] args) {
try {
FileWriter fw = new FileWriter("output.txt");
BufferedWriter bw = new BufferedWriter(fw);
bw.write("Prima linea di testo.");
bw.newLine(); // Aggiunge un carattere di nuova linea
bw.write("Seconda linea di testo.");
bw.close(); // Chiude sia BufferedWriter che FileWriter
System.out.println("Scrittura completata con buffering.");
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo esempio, BufferedWriter avvolge FileWriter, fornendo un buffer interno e metodi aggiuntivi come newLine().
6.2.2.3 Utilizzo di BufferedReader
Per leggere un file utilizzando BufferedReader:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class LetturaBuffered {
public static void main(String[] args) {
try {
FileReader fr = new FileReader("output.txt");
BufferedReader br = new BufferedReader(fr);
String linea;
while ((linea = br.readLine()) != null) {
System.out.println(linea);
}
br.close(); // Chiude sia BufferedReader che FileReader
} catch (IOException e) {
e.printStackTrace();
}
}
}Con BufferedReader, possiamo utilizzare readLine() per leggere una linea intera di testo alla volta, rendendo il codice più leggibile e spesso più efficiente.
6.2.2.4 Chiusura dei Stream
È fondamentale chiudere gli stream dopo l’uso per liberare le risorse e garantire che tutti i dati vengano effettivamente scritti sul disco. Questo può essere fatto utilizzando il metodo close(). Tuttavia, gestire la chiusura manuale può essere soggetto a errori, specialmente in presenza di eccezioni.
Per semplificare questa operazione, Java offre il costrutto try-with-resources (introdotto in Java 7):
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class LetturaConTryWithResources {
public static void main(String[] args) {
try (FileReader fr = new FileReader("output.txt");
BufferedReader br = new BufferedReader(fr)) {
String linea;
while ((linea = br.readLine()) != null) {
System.out.println(linea);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}In questo modo, gli stream vengono automaticamente chiusi al termine del blocco try, anche se si verifica un’eccezione.
6.2.3 Confronto tra FileReader/FileWriter e BufferedReader/BufferedWriter
Quando utilizzare FileReader e FileWriter:
-
Per operazioni semplici su file di piccole dimensioni.
-
Quando non è necessaria un’efficienza elevata.
Quando utilizzare BufferedReader e BufferedWriter:
-
Per file di grandi dimensioni o quando le prestazioni sono critiche.
-
Quando si ha bisogno di metodi avanzati come
readLine()onewLine(). -
Per ridurre il numero di operazioni I/O fisiche.
Esempio di differenza nelle prestazioni:
Supponiamo di dover leggere un file di 10 MB. Utilizzando FileReader, il programma potrebbe impiegare significativamente più tempo rispetto all’uso di BufferedReader, a causa delle numerose operazioni I/O richieste per leggere carattere per carattere.
6.2.4 Gestione delle Eccezioni
Durante le operazioni di I/O, possono verificarsi diverse eccezioni, come FileNotFoundException o IOException. È importante gestire queste eccezioni per evitare crash dell’applicazione e fornire feedback utili all’utente o al sistema.
Esempio di gestione delle eccezioni:
try {
BufferedReader br = new BufferedReader(new FileReader("non_esiste.txt"));
// Operazioni di lettura
br.close();
} catch (FileNotFoundException e) {
System.err.println("Il file specificato non esiste.");
} catch (IOException e) {
System.err.println("Si è verificato un errore durante la lettura del file.");
}In questo esempio, distinguiamo tra un file non trovato e altri tipi di errori I/O, fornendo messaggi specifici per ciascun caso.
6.2.5 Caratteristiche Aggiuntive e Best Practices
-
Specificare il Charset: Per garantire la corretta interpretazione dei caratteri, soprattutto in applicazioni internazionali, è buona norma specificare il set di caratteri:
FileReader fr = new FileReader("file.txt", StandardCharsets.UTF_8); -
Sincronizzazione: Se più thread devono accedere allo stesso file, è necessario gestire la sincronizzazione per evitare condizioni di corsa.
-
Validazione del Percorso del File: Prima di aprire un file, è utile verificare che il percorso sia valido e che si abbiano i permessi necessari.
6.2.6 Esempio Completo: Copia di un File di Testo
Mettiamo insieme quanto appreso per creare un programma che copia il contenuto di un file di testo in un altro.
import java.io.*;
public class CopiaFileTesto {
public static void main(String[] args) {
String sorgente = "input.txt";
String destinazione = "output.txt";
try (BufferedReader br = new BufferedReader(new FileReader(sorgente));
BufferedWriter bw = new BufferedWriter(new FileWriter(destinazione))) {
String linea;
while ((linea = br.readLine()) != null) {
bw.write(linea);
bw.newLine();
}
System.out.println("Copia completata con successo.");
} catch (FileNotFoundException e) {
System.err.println("File sorgente non trovato: " + sorgente);
} catch (IOException e) {
System.err.println("Errore durante la copia del file.");
e.printStackTrace();
}
}
}Questo programma legge input.txt linea per linea e scrive il contenuto in output.txt. Utilizzando BufferedReader e BufferedWriter, il processo è efficiente anche per file di grandi dimensioni.
6.2.7 Conclusione
La gestione corretta della lettura e scrittura di file è cruciale nello sviluppo di applicazioni Java. Comprendere quando e come utilizzare FileReader, FileWriter, BufferedReader e BufferedWriter consente di scrivere codice più efficiente, leggibile e robusto. Ricordate sempre di gestire le eccezioni, chiudere gli stream e considerare le esigenze specifiche della vostra applicazione per scegliere l’approccio migliore.
6.3 Serializzazione degli Oggetti
La serializzazione è un meccanismo fondamentale in Java che consente di convertire un oggetto in una sequenza di byte, permettendo così la sua memorizzazione su disco, l’invio attraverso una rete o il passaggio a un’altra JVM. Il processo inverso, chiamato deserializzazione, ricostruisce l’oggetto originale a partire dalla sequenza di byte.
La serializzazione è utile in diversi scenari:
-
Persistenza: Salvare lo stato di un oggetto per un utilizzo futuro.
-
Comunicazione: Trasmettere oggetti tra diverse parti di un’applicazione o tra applicazioni differenti.
-
Caching: Memorizzare oggetti per migliorare le prestazioni.
-
Sessioni Web: Salvare lo stato della sessione di un utente.
In questa sezione, esploreremo come funziona la serializzazione in Java, come implementarla e quali sono le best practices da seguire.
6.3.1 Implementazione della Serializzazione
Per serializzare un oggetto in Java, la classe dell’oggetto deve implementare l’interfaccia marker Serializable presente nel pacchetto java.io. Questa interfaccia non contiene metodi, ma indica al sistema che la classe può essere serializzata.
Esempio:
import java.io.Serializable;
public class Persona implements Serializable {
private String nome;
private int eta;
public Persona(String nome, int eta) {
this.nome = nome;
this.eta = eta;
}
// Getter e Setter
@Override
public String toString() {
return "Persona [nome=" + nome + ", eta=" + eta + "]";
}
}6.3.2 Scrittura e Lettura di Oggetti Serializzati
Per serializzare un oggetto e scriverlo su un file, utilizziamo le classi ObjectOutputStream e FileOutputStream. Per deserializzarlo, usiamo ObjectInputStream e FileInputStream.
Serializzazione:
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.IOException;
public class SerializzaPersona {
public static void main(String[] args) {
Persona persona = new Persona("Alice", 25);
try (FileOutputStream fileOut = new FileOutputStream("persona.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(persona);
System.out.println("Oggetto serializzato salvato in persona.ser");
} catch (IOException i) {
i.printStackTrace();
}
}
}Deserializzazione:
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.io.IOException;
import java.io.FileNotFoundException;
public class DeserializzaPersona {
public static void main(String[] args) {
Persona persona = null;
try (FileInputStream fileIn = new FileInputStream("persona.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
persona = (Persona) in.readObject();
System.out.println("Oggetto deserializzato: " + persona);
} catch (FileNotFoundException f) {
System.out.println("File non trovato.");
f.printStackTrace();
} catch (IOException i) {
i.printStackTrace();
} catch (ClassNotFoundException c) {
System.out.println("Classe Persona non trovata.");
c.printStackTrace();
}
}
}6.3.3 Il Campo serialVersionUID
Il campo serialVersionUID è un identificatore univoco utilizzato durante il processo di serializzazione e deserializzazione per assicurare che una classe serializzata e una deserializzata siano compatibili. Se non viene specificato, il compilatore ne genera uno basato sulla struttura della classe.
Esempio:
public class Persona implements Serializable {
private static final long serialVersionUID = 1L;
private String nome;
private int eta;
// Costruttori, Getter, Setter e altri metodi
}Perché è importante?
-
Compatibilità di Versione: Se apporti modifiche alla classe (come aggiungere o rimuovere campi), il
serialVersionUIDgarantisce che le versioni della classe siano compatibili durante la deserializzazione. -
Evitare
InvalidClassException: Senza unserialVersionUIDesplicito, potresti incorrere in un’eccezione se la struttura della classe cambia.
6.3.4 La Parola Chiave transient
Il modificatore transient viene utilizzato per indicare che un campo non deve essere serializzato. Questo è utile per campi che contengono informazioni sensibili o che non sono serializzabili.
Esempio:
public class Utente implements Serializable {
private String username;
private transient String password; // Non verrà serializzata
// Costruttori, Getter e Setter
}Nota: Durante la deserializzazione, i campi transient vengono inizializzati con i valori predefiniti (ad esempio, null per gli oggetti, 0 per gli interi).
6.3.5 Personalizzazione della Serializzazione
Puoi personalizzare il processo di serializzazione implementando i metodi privati writeObject() e readObject() all’interno della tua classe.
Esempio:
private void writeObject(ObjectOutputStream oos) throws IOException {
oos.defaultWriteObject(); // Serializza i campi non transient
oos.writeObject(/* campi o logica aggiuntiva */);
}
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
ois.defaultReadObject(); // Deserializza i campi non transient
// Leggi i campi aggiuntivi o esegui logica personalizzata
}Quando usarli?
-
Validazione: Per convalidare i dati durante la deserializzazione.
-
Criptazione: Per criptare o decriptare campi sensibili.
-
Compatibilità: Per gestire versioni diverse della classe.
6.3.6 Gestione di Oggetti Non Serializzabili
Se la tua classe contiene riferimenti a oggetti che non implementano Serializable, devi gestirli per evitare NotSerializableException.
Soluzioni:
-
Rendere il campo
transient: Se il campo non è necessario dopo la deserializzazione. -
Serializzare manualmente: Utilizzare metodi personalizzati
writeObject()ereadObject().
Esempio con transient:
public class Documento implements Serializable {
private String titolo;
private transient File file; // File non è serializzabile
// Costruttori, Getter e Setter
}6.3.7 Problemi Comuni e Best Practices
-
Consistenza dei Dati: Assicurati che gli oggetti deserializzati siano in uno stato consistente. Utilizza la validazione nei metodi
readObject()se necessario. -
Sicurezza: La deserializzazione può essere vulnerabile ad attacchi se non si presta attenzione. Evita di deserializzare dati da fonti non affidabili.
-
Performance: La serializzazione può essere costosa in termini di tempo. Considera alternative come formati più leggeri (ad esempio, JSON o Protocol Buffers) per applicazioni ad alte prestazioni.
-
Versionamento: Mantieni il controllo delle versioni delle tue classi usando
serialVersionUIDe gestendo attentamente le modifiche alla struttura delle classi.
6.3.8 Esempio Pratico Completo
Definizione della Classe:
import java.io.Serializable;
public class Contatto implements Serializable {
private static final long serialVersionUID = 100L;
private String nome;
private String email;
private transient String telefono; // Non serializzato
public Contatto(String nome, String email, String telefono) {
this.nome = nome;
this.email = email;
this.telefono = telefono;
}
// Getter e Setter
@Override
public String toString() {
return "Contatto [nome=" + nome + ", email=" + email + ", telefono=" + telefono + "]";
}
}Serializzazione dell’Oggetto:
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.IOException;
public class SerializzaContatto {
public static void main(String[] args) {
Contatto contatto = new Contatto("Luca Bianchi", "luca.bianchi@example.com", "1234567890");
try (FileOutputStream fileOut = new FileOutputStream("contatto.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(contatto);
System.out.println("Contatto serializzato salvato in contatto.ser");
} catch (IOException i) {
i.printStackTrace();
}
}
}Deserializzazione dell’Oggetto:
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.io.IOException;
import java.io.FileNotFoundException;
public class DeserializzaContatto {
public static void main(String[] args) {
Contatto contatto = null;
try (FileInputStream fileIn = new FileInputStream("contatto.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
contatto = (Contatto) in.readObject();
System.out.println("Contatto deserializzato: " + contatto);
} catch (FileNotFoundException f) {
System.out.println("File non trovato.");
f.printStackTrace();
} catch (IOException i) {
i.printStackTrace();
} catch (ClassNotFoundException c) {
System.out.println("Classe Contatto non trovata.");
c.printStackTrace();
}
}
}Risultato:
Contatto deserializzato: Contatto [nome=Luca Bianchi, email=luca.bianchi@example.com, telefono=null]
Osservazioni:
-
Il campo
telefonoènulldopo la deserializzazione perché era dichiaratotransient. -
L’oggetto
Contattoè stato ricostruito con successo con i campi serializzati.
6.3.9 Conclusioni
La serializzazione degli oggetti in Java è una tecnica potente che facilita la persistenza e la trasmissione di dati complessi. Tuttavia, richiede una comprensione approfondita per essere utilizzata in modo sicuro ed efficiente.
Punti Chiave da Ricordare:
-
Implementare
Serializable: Necessario per le classi che devono essere serializzate. -
Gestire il
serialVersionUID: Aiuta a mantenere la compatibilità tra diverse versioni di una classe. -
Usare
transientcon attenzione: Escludere campi sensibili o non serializzabili. -
Personalizzare con
writeObject()ereadObject(): Per controllare il processo di serializzazione/deserializzazione. -
Considerare la Sicurezza: Evitare di deserializzare dati da fonti non fidate e validare sempre gli oggetti deserializzati.
-
Alternative alla Serializzazione Standard: Valutare l’uso di formati come JSON, XML o altri meccanismi di serializzazione per esigenze specifiche.
Comprendere e applicare correttamente la serializzazione ti permetterà di sviluppare applicazioni Java più flessibili e robuste, pronte a gestire la complessità dei dati nel mondo reale.
6.4 NIO e NIO.2
Con l’evoluzione delle applicazioni Java, la necessità di gestire operazioni di input/output in modo più efficiente è diventata sempre più evidente. Le tradizionali API di I/O basate su stream presentavano limitazioni in termini di prestazioni e flessibilità, soprattutto quando si trattava di gestire grandi quantità di dati o operazioni I/O non bloccanti. Per rispondere a queste esigenze, Java ha introdotto le API NIO (New Input/Output) e successivamente NIO.2, offrendo strumenti più potenti e performanti per la gestione dell’I/O.
6.4.1 Introduzione a NIO
Motivazioni per l’introduzione di NIO
Le API I/O originali di Java erano basate su stream e orientate ai byte o ai caratteri. Sebbene fossero sufficienti per molte applicazioni, presentavano problemi di efficienza, soprattutto in scenari ad alta intensità di I/O. Le limitazioni principali erano:
-
I/O Bloccante: Le operazioni di I/O bloccavano il thread fino al completamento, limitando la scalabilità.
-
Mancanza di Buffering Efficiente: La gestione dei buffer era limitata, rendendo difficile ottimizzare le prestazioni.
-
Accesso Limitato alle Funzionalità del Sistema Operativo: Le API non esponevano molte delle funzionalità avanzate offerte dai sistemi operativi moderni.
Per superare queste limitazioni, Java 1.4 ha introdotto le API NIO, fornendo un modello di I/O non bloccante e orientato ai buffer.
Differenze tra I/O Tradizionale e NIO
-
Orientamento: L’I/O tradizionale è stream-oriented, mentre NIO è buffer-oriented.
-
Bloccaggio: Le API NIO supportano operazioni sia bloccanti che non bloccanti, permettendo una maggiore efficienza nelle applicazioni con elevati requisiti di I/O.
-
Scalabilità: Con NIO, è possibile gestire migliaia di canali con pochi thread grazie ai selector, migliorando la scalabilità.
6.4.2 Concetti Chiave di NIO
Buffer
Un Buffer è un’area di memoria destinata a contenere dati da leggere o scrivere. In NIO, i buffer sono oggetti che contengono dati da processare e offrono metodi per manipolarli.
Esempio di creazione di un ByteBuffer:
ByteBuffer buffer = ByteBuffer.allocate(1024);Channel
Un Channel rappresenta una connessione a un’entità in grado di eseguire operazioni I/O, come file o socket. A differenza degli stream, i channel sono bidirezionali e possono essere sia letti che scritti.
Esempio di apertura di un FileChannel:
RandomAccessFile file = new RandomAccessFile("data.txt", "rw");
FileChannel channel = file.getChannel();Selector
Un Selector è un componente che monitora uno o più channel per vedere se sono pronti per operazioni di I/O, permettendo la gestione efficiente di canali multipli con un singolo thread.
Esempio di utilizzo di un Selector:
Selector selector = Selector.open();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);6.4.3 Esempi di Utilizzo di NIO
Lettura e Scrittura di File con NIO
Esempio di copia di un file utilizzando NIO:
public static void copyFile(String sourcePath, String destPath) throws IOException {
try (FileChannel sourceChannel = new FileInputStream(sourcePath).getChannel();
FileChannel destChannel = new FileOutputStream(destPath).getChannel()) {
destChannel.transferFrom(sourceChannel, 0, sourceChannel.size());
}
}In questo esempio, utilizziamo FileChannel per copiare i dati da un file all’altro in modo efficiente.
Utilizzo dei Buffer e dei Channel
Esempio di lettura di dati da un file:
try (RandomAccessFile file = new RandomAccessFile("data.txt", "r");
FileChannel channel = file.getChannel()) {
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = channel.read(buffer);
while (bytesRead != -1) {
buffer.flip();
while (buffer.hasRemaining()) {
System.out.print((char) buffer.get());
}
buffer.clear();
bytesRead = channel.read(buffer);
}
}Questo codice legge il contenuto di un file utilizzando un buffer per gestire i dati in modo efficiente.
6.4.4 Introduzione a NIO.2
Con Java 7, le API NIO sono state estese e migliorate, dando vita a NIO.2. Questo aggiornamento ha introdotto il nuovo package java.nio.file, offrendo un’astrazione più moderna e completa per la gestione del file system.
Miglioramenti e Nuove Funzionalità
-
API File System Migliorate: Introduzione di classi come
Path,FileseFileSystemper una gestione più semplice e potente dei percorsi e delle operazioni sui file. -
Accesso Atomico ai File: Operazioni sui file più sicure e atomiche.
-
Watch Service API: Possibilità di monitorare i cambiamenti nel file system in tempo reale.
6.4.5 Operazioni sui File con NIO.2
Il Tipo Path
La classe Path rappresenta un percorso nel file system e sostituisce in gran parte la vecchia classe File.
Esempio di creazione di un Path:
Path path = Paths.get("data", "info.txt");Operazioni con la Classe Files
La classe Files fornisce metodi statici per eseguire operazioni comuni sui file.
Esempio di creazione di un file:
Path path = Paths.get("data", "newfile.txt");
Files.createFile(path);Lettura e Scrittura di File
Esempio di scrittura di stringhe in un file:
List<String> lines = Arrays.asList("Prima linea", "Seconda linea");
Path file = Paths.get("data", "output.txt");
Files.write(file, lines, StandardCharsets.UTF_8);Esempio di lettura di tutte le linee da un file:
Path file = Paths.get("data", "output.txt");
List<String> lines = Files.readAllLines(file, StandardCharsets.UTF_8);
lines.forEach(System.out::println);Gestione degli Attributi dei File
È possibile accedere e modificare gli attributi dei file, come permessi, dimensioni e timestamp.
Esempio di lettura degli attributi:
Path file = Paths.get("data", "output.txt");
BasicFileAttributes attrs = Files.readAttributes(file, BasicFileAttributes.class);
System.out.println("Dimensione: " + attrs.size());
System.out.println("Ultima modifica: " + attrs.lastModifiedTime());Utilizzo del WatchService
Il WatchService permette di monitorare directory per eventi come la creazione, la modifica o la cancellazione di file.
Esempio di monitoraggio di una directory:
Path dir = Paths.get("data");
WatchService watchService = FileSystems.getDefault().newWatchService();
dir.register(watchService, StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_DELETE,
StandardWatchEventKinds.ENTRY_MODIFY);
WatchKey key;
while ((key = watchService.take()) != null) {
for (WatchEvent<?> event : key.pollEvents()) {
System.out.println("Evento " + event.kind() + " sul file " + event.context());
}
key.reset();
}6.4.6 Vantaggi e Utilizzi di NIO e NIO.2
Prestazioni Migliorate con I/O Non Bloccante
Le API NIO consentono di eseguire operazioni I/O in modo non bloccante, permettendo alle applicazioni di gestire più connessioni simultanee con un numero ridotto di thread. Questo è particolarmente utile nei server ad alte prestazioni.
Maggiore Controllo e Funzionalità Avanzate
Con NIO.2, la gestione dei file è diventata più potente e flessibile. È possibile:
-
Accedere in modo dettagliato agli attributi dei file.
-
Eseguire operazioni di I/O asincrone.
-
Monitorare in tempo reale le modifiche nel file system.
-
Gestire in modo efficiente percorsi e sistemi di file multipli.
Esempi di Applicazioni Pratiche
-
Server Web ad Alte Prestazioni: Utilizzo di NIO per gestire migliaia di connessioni client in modo efficiente.
-
Applicazioni di Monitoraggio: Uso del WatchService per rilevare cambiamenti nei file per applicazioni di sincronizzazione o di log.
-
Gestione Avanzata dei File: Strumenti di backup e gestione dei file che richiedono operazioni complesse sul file system.
6.4.7 Conclusione
Le API NIO e NIO.2 rappresentano un significativo passo avanti nella gestione dell’I/O in Java. Offrono maggiore efficienza, flessibilità e controllo rispetto alle API I/O tradizionali. Comprendere e utilizzare queste API è fondamentale per sviluppare applicazioni Java moderne e performanti, soprattutto in contesti dove le prestazioni I/O sono critiche. Con l’aggiunta di NIO.2, Java ha ulteriormente ampliato le capacità di interazione con il file system, rendendo più semplice e potente la gestione di file e directory.
Capitolo 7: Concorrenza e Multithreading
7.1 Thread in Java
Introduzione
La programmazione concorrente è un elemento cruciale nello sviluppo di applicazioni moderne, specialmente in un’epoca in cui le risorse multicore sono la norma. Java, sin dalle sue prime versioni, offre un robusto supporto per la creazione e la gestione dei thread, permettendo agli sviluppatori di eseguire più operazioni simultaneamente all’interno di un singolo programma.
In questa sezione, esploreremo come creare e gestire i thread in Java, analizzando le differenze tra l’implementazione dell’interfaccia Runnable e l’estensione della classe Thread. Comprendere queste fondamenta è essenziale sia per i principianti che si avvicinano alla programmazione concorrente, sia per gli sviluppatori esperti che desiderano consolidare le proprie conoscenze in vista di colloqui tecnici approfonditi.
7.1.1 Cos’è un Thread?
Un thread è il più piccolo flusso di esecuzione schedulabile dal sistema operativo. In Java, un thread rappresenta un singolo percorso di esecuzione all’interno di un programma. L’utilizzo dei thread permette a un’applicazione di eseguire più operazioni contemporaneamente, migliorando l’efficienza e la reattività, specialmente in applicazioni che richiedono operazioni I/O o elaborazioni computazionali intensive.
Perché utilizzare i thread?
-
Reattività: Un’applicazione può rimanere responsiva mentre esegue operazioni lunghe in background.
-
Utilizzo efficiente delle risorse: Sfruttare al meglio le CPU multicore eseguendo più thread in parallelo.
-
Modularità: Separare le diverse attività in thread distinti può migliorare la struttura del programma.
7.1.2 Creazione di Thread in Java
Esistono principalmente due modi per creare un thread in Java:
-
Implementare l’interfaccia
Runnable -
Estendere la classe
Thread
7.1.2.1 Implementare l’interfaccia Runnable
L’interfaccia Runnable definisce un singolo metodo run(), che contiene il codice che il thread eseguirà. Implementando Runnable, si separa il lavoro da eseguire dalla meccanica del thread stesso.
Esempio:
public class MyRunnable implements Runnable {
@Override
public void run() {
// Codice da eseguire in un thread separato
System.out.println("Il thread sta eseguendo.");
}
}
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start(); // Avvia l'esecuzione del thread
}
}Spiegazione:
-
Creazione di un oggetto
Runnable: Si implementa l’interfacciaRunnablee si definisce il metodorun(). -
Creazione di un oggetto
Thread: Si passa l’istanza diRunnableal costruttore diThread. -
Avvio del thread: Chiamando
thread.start(), il metodorun()viene eseguito in un nuovo thread.
Vantaggi di implementare Runnable:
-
Ereditarietà: La classe può estendere un’altra classe, poiché in Java non esiste l’ereditarietà multipla.
-
Separazione delle responsabilità: Il compito da eseguire è separato dalla meccanica del thread.
7.1.2.2 Estendere la classe Thread
Un altro modo per creare un thread è estendere la classe Thread e sovrascrivere il metodo run().
Esempio:
public class MyThread extends Thread {
@Override
public void run() {
// Codice da eseguire in un thread separato
System.out.println("Il thread sta eseguendo.");
}
}
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start(); // Avvia l'esecuzione del thread
}
}Spiegazione:
-
Sottoclasse di
Thread: Si estende la classeThreade si sovrascrive il metodorun(). -
Avvio del thread: Come prima, si chiama
thread.start()per avviare il thread.
Svantaggi di estendere Thread:
- Limitazione dell’ereditarietà: Non è possibile estendere un’altra classe, il che può essere limitante in alcuni casi.
7.1.3 Runnable vs Thread: Quale scegliere?
Quando implementare Runnable:
-
Ereditarietà: Se la classe deve estendere un’altra classe.
-
Modularità: Per separare il compito da eseguire dalla meccanica del thread.
-
Riutilizzabilità: Il compito può essere eseguito in contesti diversi, non solo come thread.
Quando estendere Thread:
-
Semplicità: Per semplici applicazioni dove l’ereditarietà multipla non è un problema.
-
Personalizzazione: Se si ha bisogno di personalizzare ulteriormente il comportamento del thread.
Considerazioni:
-
Buone pratiche: Generalmente, è consigliabile implementare
Runnableper una maggiore flessibilità e aderenza ai principi di progettazione orientata agli oggetti. -
Thread Pool: Quando si utilizzano thread pool, è necessario passare oggetti
RunnableoCallable.
7.1.4 Il Metodo run() vs start()
Un errore comune è chiamare il metodo run() invece di start(). Chiamando run(), il codice viene eseguito nel thread corrente, non in un nuovo thread.
Esempio Errato:
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.run(); // ERRATO: Non avvia un nuovo thread
}
}Esempio Corretto:
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start(); // Corretto: Avvia un nuovo thread
}
}Spiegazione:
-
start(): Inizia un nuovo thread di esecuzione e chiamarun()in quel thread. -
run(): Se chiamato direttamente, esegue il metodo nel thread corrente.
7.1.5 Esecuzione di Thread Multipli
È possibile avviare più thread per eseguire compiti in parallelo.
Esempio:
public class Task implements Runnable {
private String nome;
public Task(String nome) {
this.nome = nome;
}
@Override
public void run() {
System.out.println("Esecuzione del task: " + nome);
}
}
public class Main {
public static void main(String[] args) {
Thread thread1 = new Thread(new Task("Task 1"));
Thread thread2 = new Thread(new Task("Task 2"));
Thread thread3 = new Thread(new Task("Task 3"));
thread1.start();
thread2.start();
thread3.start();
}
}Possibile Output:
Esecuzione del task: Task 2
Esecuzione del task: Task 1
Esecuzione del task: Task 3
Nota:
- L’ordine di esecuzione dei thread non è garantito e può variare ad ogni esecuzione.
7.1.6 Gestione dei Thread
Metodi Utili:
-
sleep(long millis): Fa sì che il thread si sospenda per un certo periodo. -
join(): Il thread corrente attende la terminazione del thread su cui è chiamato. -
interrupt(): Interrompe un thread in esecuzione.
Esempio con sleep() e join():
public class Counter implements Runnable {
@Override
public void run() {
for(int i = 1; i <= 5; i++) {
System.out.println("Contatore: " + i);
try {
Thread.sleep(1000); // Pausa di 1 secondo
} catch (InterruptedException e) {
System.out.println("Thread interrotto");
}
}
}
}
public class Main {
public static void main(String[] args) {
Thread counterThread = new Thread(new Counter());
counterThread.start();
try {
counterThread.join(); // Attende che counterThread termini
} catch (InterruptedException e) {
System.out.println("Thread principale interrotto");
}
System.out.println("Contatore completato");
}
}Output:
Contatore: 1
Contatore: 2
Contatore: 3
Contatore: 4
Contatore: 5
Contatore completato
Spiegazione:
-
Il thread principale avvia
counterThreade poi chiamajoin(), sospendendosi finchécounterThreadnon termina. -
Dopo la terminazione, il thread principale riprende e stampa “Contatore completato”.
7.1.7 Interruzione dei Thread
I thread possono essere interrotti utilizzando il metodo interrupt(). Questo non forza l’interruzione immediata, ma segnala al thread che è stata richiesta un’interruzione.
Esempio:
public class Task implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
// Eseguire il lavoro
System.out.println("Il thread sta lavorando...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("Thread interrotto durante sleep.");
Thread.currentThread().interrupt(); // Reimposta lo stato di interruzione
}
}
System.out.println("Il thread si è fermato.");
}
}
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new Task());
thread.start();
try {
Thread.sleep(3000); // Lascia che il thread lavori per 3 secondi
} catch (InterruptedException e) {
e.printStackTrace();
}
thread.interrupt(); // Richiede l'interruzione del thread
}
}Output:
Il thread sta lavorando...
Il thread sta lavorando...
Il thread sta lavorando...
Thread interrotto durante sleep.
Il thread si è fermato.
Spiegazione:
-
Il thread verifica periodicamente se è stato interrotto controllando
Thread.currentThread().isInterrupted(). -
Quando
interrupt()viene chiamato, se il thread è in stato disleep(), viene lanciata un’InterruptedException. -
È buona pratica ripristinare lo stato di interruzione dopo aver catturato
InterruptedException.
7.1.8 Differenza tra isInterrupted() e interrupted()
-
isInterrupted(): Metodo di istanza che verifica se il thread corrente è stato interrotto senza ripristinare lo stato di interruzione. -
interrupted(): Metodo statico che verifica se il thread corrente è stato interrotto e ripristina lo stato di interruzione (lo imposta afalse).
Esempio:
public class Main {
public static void main(String[] args) {
Thread.currentThread().interrupt();
System.out.println("Stato di interruzione: " + Thread.interrupted()); // true
System.out.println("Stato di interruzione dopo interrupted(): " + Thread.interrupted()); // false
}
}7.1.9 Best Practices nella Gestione dei Thread
-
Evitare di chiamare
run()direttamente: Sempre utilizzarestart()per avviare un thread. -
Gestire le eccezioni: Sempre gestire
InterruptedExceptione altre possibili eccezioni. -
Condividere le risorse con attenzione: Utilizzare meccanismi di sincronizzazione per evitare problemi di consistenza dei dati (vedi sezione 7.2).
-
Limitare il numero di thread: Creare troppi thread può degradare le prestazioni; considerare l’utilizzo di un thread pool.
-
Utilizzare le API più recenti: Considerare l’uso dell’
Executor Frameworkper una gestione più efficiente dei thread (vedi sezione 7.3).
7.1.10 Conclusione
La comprensione della creazione e gestione dei thread in Java è fondamentale per lo sviluppo di applicazioni concorrenti ed efficienti. Sia l’implementazione di Runnable che l’estensione di Thread hanno i loro casi d’uso, ma l’implementazione di Runnable è generalmente preferita per la sua flessibilità e aderenza ai principi di progettazione orientata agli oggetti.
Nei capitoli successivi, esploreremo come sincronizzare i thread per evitare condizioni di gara e come utilizzare strumenti più avanzati per la gestione della concorrenza, come l’Executor Framework e le classi concorrenti avanzate.
Proseguendo con queste conoscenze, sarete in grado di affrontare sfide più complesse legate alla concorrenza e al multithreading in Java, competenze essenziali sia nello sviluppo professionale che nella preparazione di colloqui tecnici approfonditi.
7.2 Sincronizzazione
La programmazione concorrente consente a un’applicazione di eseguire più operazioni in parallelo, sfruttando al meglio le risorse del sistema e migliorando le prestazioni. Tuttavia, quando più thread accedono simultaneamente a risorse condivise, possono insorgere problemi come condizioni di gara (race conditions), inconsistenza dei dati e deadlock. Per gestire questi problemi, Java offre meccanismi di sincronizzazione, principalmente attraverso le parole chiave synchronized e volatile.
Problemi di Accesso Concorrente
Quando più thread manipolano la stessa risorsa senza un’adeguata sincronizzazione, possono verificarsi risultati inaspettati. Consideriamo l’esempio di un contatore condiviso:
public class Contatore {
private int valore = 0;
public void incrementa() {
valore++;
}
public int getValore() {
return valore;
}
}Se due thread eseguono contemporaneamente il metodo incrementa(), entrambi potrebbero leggere lo stesso valore di valore, incrementarlo e scrivere il risultato, causando la perdita di un incremento. Questo accade perché l’operazione valore++ non è atomica; è composta da tre passaggi:
-
Lettura del valore corrente di
valore. -
Incremento del valore.
-
Scrittura del nuovo valore in
valore.
Senza sincronizzazione, l’accesso concorrente a questa variabile può portare a risultati errati.
La Parola Chiave synchronized
La parola chiave synchronized viene utilizzata per controllare l’accesso ai blocchi di codice o ai metodi, assicurando che solo un thread alla volta possa eseguire il codice sincronizzato su un determinato oggetto monitorato (monitor). Questo previene le condizioni di gara e garantisce la coerenza dei dati.
Metodi Sincronizzati
È possibile dichiarare un intero metodo come sincronizzato:
public synchronized void incrementa() {
valore++;
}Quando un metodo è sincronizzato, il thread che lo esegue deve acquisire il lock sull’oggetto corrente (this) prima di entrare nel metodo. Altri thread che tentano di accedere a qualsiasi metodo sincronizzato sullo stesso oggetto verranno bloccati finché il lock non viene rilasciato.
Blocchi Sincronizzati
Per una maggiore granularità, è possibile sincronizzare solo una porzione di codice all’interno di un metodo:
public void incrementa() {
synchronized(this) {
valore++;
}
}Oppure sincronizzare su un oggetto specifico:
private final Object lock = new Object();
public void incrementa() {
synchronized(lock) {
valore++;
}
}Questo approccio è utile quando si desidera limitare la sincronizzazione solo alle sezioni critiche, migliorando così le prestazioni.
Esempio di Sincronizzazione con synchronized
Consideriamo un esempio pratico in cui due thread incrementano un contatore condiviso:
public class EsempioSincronizzazione {
public static void main(String[] args) throws InterruptedException {
Contatore contatore = new Contatore();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Valore finale: " + contatore.getValore());
}
}Senza sincronizzazione, il valore finale potrebbe essere inferiore a 2000 a causa delle condizioni di gara. Aggiungendo synchronized al metodo incrementa(), garantiamo che il valore finale sia sempre 2000.
La Parola Chiave volatile
La parola chiave volatile viene utilizzata per indicare al compilatore e alla JVM che una variabile può essere modificata da più thread. Questo assicura che le letture e le scritture sulla variabile siano fatte direttamente dalla memoria principale, evitando cache locali dei thread.
Utilizzo di volatile
public class Segnale {
private volatile boolean attivo = true;
public void disattiva() {
attivo = false;
}
public void esegui() {
while (attivo) {
// Esecuzione di operazioni
}
}
}In questo esempio, il thread che esegue il metodo esegui() leggerà sempre il valore aggiornato di attivo. Senza volatile, potrebbe continuare a vedere il valore true dalla sua cache locale, ignorando l’aggiornamento effettuato da un altro thread.
Differenze tra volatile e synchronized
-
Visibilità delle Variabili:
volatilegarantisce che le modifiche a una variabile siano visibili a tutti i thread. -
Atomicità delle Operazioni:
volatilenon garantisce che le operazioni sulle variabili siano atomiche. Non è adatto per operazioni comecount++, che sono composte da più passaggi. -
synchronized: Garantisce sia la visibilità che l’atomicità delle operazioni all’interno del blocco sincronizzato.
Quando Utilizzare volatile
volatile è appropriato quando:
-
La variabile viene letta e scritta da più thread.
-
Le operazioni sulla variabile sono atomiche (ad esempio, assegnazioni di valori primitivi eccetto
longedouble). -
Non è necessario sincronizzare blocchi di codice più complessi.
Per operazioni non atomiche o per blocchi di codice critici, è preferibile utilizzare synchronized o altre classi di sincronizzazione.
Problemi Comuni e Best Practices
Condizioni di Gara
Una condizione di gara si verifica quando il comportamento del software dipende dall’ordine o dal timing delle esecuzioni dei thread. Per evitarla:
-
Utilizzare
synchronizedper sincronizzare l’accesso alle risorse condivise. -
Limitare la portata della sincronizzazione al minimo necessario.
Deadlock
Un deadlock si verifica quando due o più thread si bloccano a vicenda in attesa di risorse detenute dall’altro. Per prevenire deadlock:
-
Evitare di tenere lock multipli contemporaneamente.
-
Acquisire i lock sempre nello stesso ordine.
-
Utilizzare meccanismi di timeout quando possibile.
Esempio di Deadlock
public class DeadlockEsempio {
private final Object lock1 = new Object();
private final Object lock2 = new Object();
public void metodo1() {
synchronized(lock1) {
synchronized(lock2) {
// Operazioni
}
}
}
public void metodo2() {
synchronized(lock2) {
synchronized(lock1) {
// Operazioni
}
}
}
}In questo esempio, se metodo1() e metodo2() vengono eseguiti da thread diversi, si può verificare un deadlock perché ogni thread attende il lock detenuto dall’altro.
Best Practices
-
Sincronizzare solo quando necessario: Ridurre l’ambito dei blocchi sincronizzati per migliorare le prestazioni.
-
Utilizzare oggetti di lock privati: Evitare di sincronizzare su
thiso su oggetti pubblici per prevenire interferenze esterne. -
Preferire le classi di concorrenza avanzate: Le classi nel pacchetto
java.util.concurrentoffrono meccanismi più efficienti e sicuri.
Sincronizzazione su Metodi Statici
Quando si sincronizza un metodo statico, il lock viene acquisito sulla classe (Class object) anziché sull’istanza. Questo significa che tutti i thread che chiamano metodi statici sincronizzati sulla stessa classe vengono serializzati.
public static synchronized void metodoStatico() {
// Operazioni
}La Sincronizzazione e la Performance
L’uso eccessivo di sincronizzazione può portare a un degrado delle prestazioni a causa della serializzazione dei thread e del sovraccarico del contesto di switching. È importante bilanciare la necessità di sincronizzazione con l’efficienza dell’applicazione.
Conclusione
La sincronizzazione è un elemento cruciale nella programmazione concorrente in Java. Comprendere i meccanismi offerti dalle parole chiave synchronized e volatile è fondamentale per sviluppare applicazioni thread-safe e affidabili. Mentre synchronized offre un controllo granulare sull’accesso ai blocchi di codice, volatile garantisce la visibilità delle variabili tra i thread. L’uso appropriato di questi strumenti, insieme a una buona progettazione, aiuta a prevenire problemi comuni come condizioni di gara e deadlock, assicurando al contempo prestazioni ottimali.
Approfondimenti Successivi
Nel prossimo paragrafo, esploreremo l’Executor Framework di Java, che fornisce un approccio più avanzato e flessibile per la gestione dei thread, consentendo di eseguire compiti asincroni in modo efficiente attraverso l’uso di pool di thread.
7.3 Executor Framework
La programmazione concorrente è essenziale per sfruttare appieno le capacità dei moderni processori multicore. Tuttavia, la gestione manuale dei thread può essere complessa e soggetta a errori. Per semplificare questo processo, Java introduce l’Executor Framework, un insieme di interfacce e classi nel pacchetto java.util.concurrent che facilita l’esecuzione di compiti asincroni utilizzando pool di thread.
Perché l’Executor Framework?
Prima dell’introduzione dell’Executor Framework, gli sviluppatori gestivano i thread creando nuove istanze di Thread e sovrascrivendo il metodo run(). Questo approccio presentava diversi problemi:
-
Scalabilità limitata: Creare un nuovo thread per ogni compito può esaurire rapidamente le risorse di sistema.
-
Gestione complessa: Coordinare e sincronizzare manualmente i thread può portare a codice difficile da mantenere e a bug come deadlock o race condition.
-
Ottimizzazione inefficiente: Non c’è controllo sul riutilizzo dei thread o sulla limitazione del numero massimo di thread attivi.
L’Executor Framework risolve questi problemi fornendo un modo standardizzato e flessibile per gestire l’esecuzione asincrona dei compiti.
Concetti Chiave dell’Executor Framework
-
Executor: Interfaccia di base con il metodo
execute(Runnable command), che esegue il compito passato. -
ExecutorService: Estende
Executoraggiungendo metodi per gestire il ciclo di vita del servizio, comeshutdown(), e per sottomettere compiti che restituiscono un risultato tramiteCallable. -
Thread Pools: Gruppi di thread gestiti dall’Executor che possono eseguire compiti in modo efficiente riutilizzando i thread esistenti.
Creazione di un Thread Pool
La classe Executors fornisce metodi statici per creare diversi tipi di thread pool:
-
Fixed Thread Pool: Un pool con un numero fisso di thread.
ExecutorService executor = Executors.newFixedThreadPool(4); -
Cached Thread Pool: Crea nuovi thread secondo necessità ma riutilizza i thread disponibili.
ExecutorService executor = Executors.newCachedThreadPool(); -
Single Thread Executor: Un pool con un singolo thread, utile per garantire l’esecuzione sequenziale dei compiti.
ExecutorService executor = Executors.newSingleThreadExecutor();
Esecuzione di Compiti Asincroni
Supponiamo di avere un compito che stampa un messaggio:
public class PrintTask implements Runnable {
private final String message;
public PrintTask(String message) {
this.message = message;
}
@Override
public void run() {
System.out.println("Esecuzione: " + message);
}
}Per eseguire questo compito utilizzando un Executor:
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.execute(new PrintTask("Compito 1"));
executor.execute(new PrintTask("Compito 2"));
executor.execute(new PrintTask("Compito 3"));
executor.shutdown();Spiegazione:
-
Creazione del Thread Pool: Un pool con 2 thread viene creato.
-
Sottomissione dei Compiti: Tre compiti vengono sottomessi all’Executor.
-
Esecuzione: I primi due compiti vengono eseguiti immediatamente dai due thread disponibili; il terzo compito attende che uno dei thread sia libero.
-
Chiusura del ExecutorService:
shutdown()impedisce ulteriori sottomissioni e termina il servizio dopo che tutti i compiti sono stati eseguiti.
Utilizzo di Callable e Future
Se i compiti devono restituire un risultato, si utilizza l’interfaccia Callable insieme a Future.
Esempio:
public class SumTask implements Callable<Integer> {
private final int a, b;
public SumTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public Integer call() {
return a + b;
}
}Esecuzione e Ottenimento del Risultato:
ExecutorService executor = Executors.newFixedThreadPool(1);
Future<Integer> future = executor.submit(new SumTask(5, 10));
try {
Integer result = future.get(); // Attende il completamento e ottiene il risultato
System.out.println("Risultato: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
executor.shutdown();
}ScheduledExecutorService per Compiti Pianificati
Per eseguire compiti dopo un certo ritardo o periodicamente, si utilizza ScheduledExecutorService.
Esempio: Compito Periodico
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
Runnable periodicTask = () -> System.out.println("Esecuzione periodica a " + LocalTime.now());
scheduler.scheduleAtFixedRate(periodicTask, 0, 2, TimeUnit.SECONDS);
// Dopo un certo tempo, ad esempio 10 secondi, è possibile fermare lo scheduler
scheduler.schedule(() -> {
scheduler.shutdown();
System.out.println("Scheduler terminato");
}, 10, TimeUnit.SECONDS);Vantaggi dell’Executor Framework
-
Efficienza delle Risorse: Riutilizzo dei thread esistenti riduce l’overhead di creazione e distruzione.
-
Scalabilità: Gestione ottimizzata del numero di thread in base alle risorse disponibili.
-
Semplicità del Codice: Separazione tra logica dei compiti e gestione dei thread.
-
Gestione Avanzata: Controllo sul ciclo di vita dei thread e gestione delle eccezioni.
-
Flessibilità: Supporto per compiti che restituiscono risultati o che devono essere pianificati.
Best Practices
-
Gestire il Ciclo di Vita: Sempre chiamare
shutdown()oshutdownNow()per terminare l’ExecutorService. -
Gestire le Eccezioni: Le eccezioni nei compiti possono non essere visibili; utilizzare
Futureper rilevarle. -
Evitare il Sovraccarico: Non creare troppi thread; dimensionare il pool in base alle risorse e al carico.
-
Utilizzare Callable quando Necessario: Preferire
CallableaRunnablese è necessario un risultato o lanciare eccezioni verificate. -
Evitare la Sincronizzazione Innecessaria: L’Executor Framework gestisce molti aspetti della concorrenza; evitare sincronizzazioni superflue.
Considerazioni per il Colloquio Tecnico
-
Comprendere le Differenze: Essere in grado di spiegare le differenze tra
Executor,ExecutorServiceeScheduledExecutorService. -
Quando Utilizzare un Thread Pool: Sapere quando un thread pool è più appropriato rispetto alla creazione diretta di thread.
-
Gestione delle Risorse: Discutere su come l’Executor Framework aiuti nella gestione efficiente delle risorse.
-
Esempi Pratici: Essere pronti a scrivere codice che utilizza l’Executor Framework per risolvere un problema specifico.
-
Gestione delle Eccezioni: Spiegare come le eccezioni vengono gestite nei compiti e l’importanza di
Future.
Conclusione
L’Executor Framework è uno strumento potente che semplifica la programmazione concorrente in Java. Comprendere come e quando utilizzarlo non solo migliora l’efficienza e la scalabilità delle applicazioni, ma è anche fondamentale per affrontare con successo domande tecniche avanzate in un colloquio di lavoro.
7.4 Classi Avanzate di Concorrenza
La programmazione concorrente in Java non si limita all’uso di thread e alla sincronizzazione di base. Per gestire in modo efficiente applicazioni multithreaded più complesse, Java offre una serie di classi avanzate nel pacchetto java.util.concurrent. Queste classi sono progettate per risolvere problemi comuni nella concorrenza, come la gestione di variabili condivise senza lock espliciti e l’uso di collezioni thread-safe ad alte prestazioni.
7.4.1 Limitazioni delle Tecniche di Sincronizzazione di Base
L’uso dei blocchi synchronized e delle variabili volatile può diventare inefficiente e complesso in applicazioni con elevato grado di concorrenza. Queste tecniche possono portare a problemi di performance a causa della contesa dei lock e possono rendere il codice difficile da mantenere. Per affrontare queste sfide, Java fornisce strumenti più sofisticati che semplificano la gestione della concorrenza e migliorano le prestazioni.
7.4.2 Classi Atomiche
Le classi atomiche, come AtomicInteger, AtomicLong e AtomicReference, offrono operazioni atomiche sulle variabili senza la necessità di sincronizzazione esplicita.
Cos’è un’Operazione Atomica?
Un’operazione atomica è un’operazione indivisibile che viene eseguita completamente o non viene eseguita affatto. Nel contesto della concorrenza, ciò significa che nessun altro thread può vedere lo stato intermedio dell’operazione.
Utilizzo di AtomicInteger
AtomicInteger permette di eseguire operazioni aritmetiche atomiche su interi.
import java.util.concurrent.atomic.AtomicInteger;
public class ContatoreAtomico {
private AtomicInteger contatore = new AtomicInteger(0);
public void incrementa() {
contatore.incrementAndGet();
}
public int getValore() {
return contatore.get();
}
}Esempio Pratico con AtomicInteger
Immaginiamo di avere più thread che incrementano un contatore condiviso. Utilizzando AtomicInteger, garantiamo che gli incrementi siano thread-safe senza dover usare synchronized.
public class TestContatoreAtomico {
public static void main(String[] args) throws InterruptedException {
ContatoreAtomico contatore = new ContatoreAtomico();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Valore finale: " + contatore.getValore());
}
}Risultato:
Valore finale: 2000
7.4.3 Collezioni Concorrenti
Le collezioni standard di Java come ArrayList e HashMap non sono thread-safe. Per questo motivo, Java offre collezioni concorrenti che possono essere utilizzate in ambienti multithread senza ulteriori sincronizzazioni.
Problemi con le Collezioni Non Thread-Safe
L’accesso concorrente a collezioni non thread-safe può causare inconsistenza dei dati e ConcurrentModificationException.
ConcurrentHashMap
ConcurrentHashMap è una variante thread-safe di HashMap progettata per operazioni ad alte prestazioni in ambienti concorrenti.
Utilizzo di ConcurrentHashMap
import java.util.concurrent.ConcurrentHashMap;
public class MappaCondivisa {
private ConcurrentHashMap<String, Integer> mappa = new ConcurrentHashMap<>();
public void aggiornaValore(String chiave, int valore) {
mappa.put(chiave, valore);
}
public int leggiValore(String chiave) {
return mappa.getOrDefault(chiave, 0);
}
}Esempio Pratico con ConcurrentHashMap
public class TestMappaCondivisa {
public static void main(String[] args) throws InterruptedException {
MappaCondivisa mappa = new MappaCondivisa();
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
mappa.aggiornaValore("chiave", mappa.leggiValore("chiave") + 1);
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Valore finale: " + mappa.leggiValore("chiave"));
}
}Risultato:
Valore finale: 2000
Altre Collezioni Concorrenti
-
CopyOnWriteArrayList: ideale quando le letture sono frequenti e le scritture rare. -
ConcurrentLinkedQueue: una coda non bloccante ad alte prestazioni.
7.4.4 Lock e ReentrantLock
Limitazioni di synchronized
Il blocco synchronized è semplice da usare ma ha alcune limitazioni, come la mancanza di timeout e l’incapacità di verificare lo stato del lock.
Introduzione a ReentrantLock
La classe ReentrantLock offre un controllo più granulare sui lock, permettendo funzionalità avanzate come:
-
Tentare di acquisire un lock senza rimanere bloccati indefinitamente.
-
Impostare un timeout durante l’acquisizione di un lock.
-
Verificare se il lock è attualmente acquisito.
Utilizzo di ReentrantLock
import java.util.concurrent.locks.ReentrantLock;
public class ContatoreConLock {
private int contatore = 0;
private ReentrantLock lock = new ReentrantLock();
public void incrementa() {
lock.lock();
try {
contatore++;
} finally {
lock.unlock();
}
}
public int getValore() {
return contatore;
}
}Esempio Pratico
public class TestContatoreConLock {
public static void main(String[] args) throws InterruptedException {
ContatoreConLock contatore = new ContatoreConLock();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
contatore.incrementa();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Valore finale: " + contatore.getValore());
}
}7.4.5 Altre Utilità per la Concorrenza
CountDownLatch
Permette a uno o più thread di attendere che un insieme di operazioni in altri thread sia completato.
import java.util.concurrent.CountDownLatch;
public class Gara {
public static void main(String[] args) throws InterruptedException {
CountDownLatch pronto = new CountDownLatch(3);
CountDownLatch via = new CountDownLatch(1);
for (int i = 1; i <= 3; i++) {
new Thread(new Corridore(pronto, via), "Corridore " + i).start();
pronto.countDown();
}
via.countDown(); // Segnale di partenza
}
}
class Corridore implements Runnable {
private CountDownLatch pronto;
private CountDownLatch via;
public Corridore(CountDownLatch pronto, CountDownLatch via) {
this.pronto = pronto;
this.via = via;
}
@Override
public void run() {
try {
pronto.await(); // Attende che tutti siano pronti
via.await(); // Attende il segnale di partenza
System.out.println(Thread.currentThread().getName() + " è partito!");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}CyclicBarrier
Permette a un insieme di thread di aspettarsi l’un l’altro in un punto comune, ed è riutilizzabile dopo che i thread sono stati rilasciati.
Semaphore
Controlla l’accesso a una risorsa condivisa tramite un contatore.
Exchanger
Permette a due thread di scambiare oggetti in modo sincrono.
7.4.6 Best Practices nell’Uso delle Classi Avanzate di Concorrenza
-
Comprendere il Comportamento: Prima di utilizzare queste classi, è fondamentale comprendere come funzionano e quali problemi risolvono.
-
Evitare la Sovraingegnerizzazione: Non complicare il codice con meccanismi avanzati se le tecniche di sincronizzazione di base sono sufficienti.
-
Testare Accuratamente: La concorrenza introduce complessità; test approfonditi sono essenziali per garantire il corretto funzionamento.
-
Preferire le Collezioni Concorrenti: Quando si lavora con collezioni in ambienti multithreaded, utilizzare le implementazioni thread-safe offerte dal pacchetto
java.util.concurrent.
7.4.7 Conclusioni
Le classi avanzate di concorrenza in Java sono strumenti potenti che semplificano la gestione di applicazioni multithreaded complesse. Offrono soluzioni efficienti ai problemi comuni di sincronizzazione e concorrenza, migliorando sia le prestazioni che la leggibilità del codice. Con una comprensione approfondita di queste classi, è possibile sviluppare applicazioni robuste e scalabili in grado di sfruttare appieno le potenzialità dei sistemi multicore moderni.
Capitolo 8: Programmazione Funzionale in Java
8.1 Lambda Expressions
Le Lambda Expressions, introdotte in Java 8, rappresentano una delle innovazioni più significative nel linguaggio Java. Consentono di trattare comportamenti come dati, facilitando uno stile di programmazione funzionale che rende il codice più conciso e leggibile.
Sintassi delle Lambda Expressions
Una lambda expression è una funzione anonima, ovvero una funzione senza nome, che può essere definita e utilizzata in linea. La sintassi generale è la seguente:
(parametri) -> { corpo }-
Parametri: la lista di parametri, che può essere vuota o contenere uno o più parametri separati da virgole. I tipi dei parametri possono essere omessi se il compilatore può inferirli.
-
Operatore Lambda (
->): separa i parametri dal corpo dell’espressione. -
Corpo: può essere un’espressione singola o un blocco di codice racchiuso tra parentesi graffe
{}.
Esempi di Lambda Expressions:
-
Lambda con un solo parametro senza specificare il tipo:
param -> System.out.println(param); -
Lambda con più parametri con tipi specificati:
(int x, int y) -> { return x + y; } -
Lambda senza parametri:
() -> System.out.println("Hello, World!"); -
Lambda con corpo composto da una singola espressione (il
returnè implicito):(a, b) -> a * b
Utilizzi delle Lambda Expressions
Le lambda expressions sono strettamente legate alle interfacce funzionali, ovvero interfacce che dichiarano un solo metodo astratto. Esempi di interfacce funzionali predefinite in Java sono Runnable, Callable, Comparator, e molte altre all’interno del pacchetto java.util.function.
Esempio con Runnable:
// Prima di Java 8, con classe anonima
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Esecuzione in un thread separato");
}
});
thread.start();
// Con lambda expression
Thread threadLambda = new Thread(() -> System.out.println("Esecuzione in un thread separato"));
threadLambda.start();Esempio con Comparator:
List<String> nomi = Arrays.asList("Luca", "Marco", "Anna");
// Con classe anonima
Collections.sort(nomi, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
// Con lambda expression
Collections.sort(nomi, (s1, s2) -> s1.compareTo(s2));Vantaggi rispetto alle Classi Anonime
Le classi anonime erano il metodo tradizionale per implementare interfacce con una singola istanza senza dover definire una classe separata. Tuttavia, presentano alcuni svantaggi:
-
Verbosità: richiedono molto codice boilerplate, rendendo il codice meno leggibile.
-
Scarsa leggibilità: il codice importante può essere nascosto tra parentesi e override di metodi.
Le lambda expressions risolvono questi problemi:
-
Sintassi Concisa: eliminano il codice superfluo, focalizzando l’attenzione sulla logica principale.
Esempio:
// Classe anonima ActionListener listener = new ActionListener() { @Override public void actionPerformed(ActionEvent e) { System.out.println("Azione eseguita"); } }; // Lambda expression ActionListener listenerLambda = e -> System.out.println("Azione eseguita"); -
Chiarezza: il codice è più facile da leggere e capire, poiché la sintassi è più pulita.
-
Efficienza: le lambda expressions possono essere ottimizzate internamente dalla JVM, migliorando le prestazioni.
Uso nelle Stream API
Le lambda expressions sono fondamentali nell’uso delle Stream API, permettendo operazioni funzionali su collezioni di dati.
Esempio di filtraggio e mappatura:
List<String> nomi = Arrays.asList("Luca", "Marco", "Anna", "Giulia");
// Filtrare i nomi che iniziano con 'A' e convertirli in maiuscolo
List<String> nomiFiltrati = nomi.stream()
.filter(nome -> nome.startsWith("A"))
.map(String::toUpperCase)
.collect(Collectors.toList());
System.out.println(nomiFiltrati); // Output: [ANNA]Considerazioni Importanti
-
Interfacce Funzionali Personalizzate: è possibile definire proprie interfacce funzionali utilizzando l’annotazione
@FunctionalInterface.Esempio:
@FunctionalInterface public interface OperazioneMatematica { int operazione(int a, int b); } // Uso della lambda expression OperazioneMatematica addizione = (a, b) -> a + b; System.out.println(addizione.operazione(5, 3)); // Output: 8 -
Ambito delle Variabili: all’interno di una lambda expression, è possibile utilizzare variabili locali finali o effettivamente finali (non modificate dopo l’assegnazione).
Esempio:
String prefisso = "Risultato: "; OperazioneMatematica moltiplicazione = (a, b) -> { // prefisso = "Nuovo Prefisso"; // Errore: non è possibile modificare return a * b; }; System.out.println(prefisso + moltiplicazione.operazione(4, 2)); // Output: Risultato: 8
Conclusione
Le lambda expressions hanno rivoluzionato il modo in cui si scrive codice in Java, introducendo un paradigma funzionale che semplifica molte operazioni comuni. Capire come e quando utilizzarle è essenziale per scrivere codice moderno ed efficiente, rendendo le applicazioni più manutenibili e scalabili.
Vantaggi Chiave:
-
Riduzione del Codice Boilerplate: meno codice ripetitivo, più focus sulla logica.
-
Aumento della Produttività: codice più rapido da scrivere e comprendere.
-
Facilitazione della Programmazione Funzionale: abilita l’uso di tecniche funzionali come il passaggio di funzioni come argomenti.
Prossimi Passi:
Per approfondire l’uso delle lambda expressions, si consiglia di:
-
Sperimentare con le interfacce funzionali predefinite in
java.util.function. -
Esplorare le Stream API per operazioni su collezioni.
-
Analizzare il codice esistente e valutare dove le lambda expressions possono migliorare la leggibilità e l’efficienza.
Con la comprensione delle lambda expressions, si è pronti ad abbracciare pienamente la programmazione funzionale in Java, aprendo la strada a nuove possibilità e paradigmi di sviluppo.
8.2 Interfacce Funzionali
Le interfacce funzionali sono un concetto fondamentale introdotto in Java 8 che permette di abbracciare lo stile di programmazione funzionale all’interno di un linguaggio orientato agli oggetti. Comprendere le interfacce funzionali è essenziale non solo per utilizzare efficacemente le espressioni lambda, ma anche per scrivere codice più conciso, leggibile e manutenibile.
Definizione di Interfaccia Funzionale
Un’interfaccia funzionale è un’interfaccia che contiene un unico metodo astratto. Questo metodo definisce l’operazione che l’interfaccia rappresenta. Le interfacce funzionali possono avere metodi di default o statici, ma ciò che le caratterizza è la presenza di un solo metodo astratto.
In Java, esiste un’annotazione speciale @FunctionalInterface che può essere utilizzata per indicare esplicitamente che un’interfaccia è funzionale. Questa annotazione non è obbligatoria, ma è una buona pratica utilizzarla perché permette al compilatore di segnalare errori nel caso in cui l’interfaccia non rispetti i requisiti di un’interfaccia funzionale.
Esempio di Interfaccia Funzionale Personalizzata:
@FunctionalInterface
public interface Calcolatore {
int calcola(int a, int b);
}In questo esempio, Calcolatore è un’interfaccia funzionale con un solo metodo astratto calcola.
Utilizzo delle Interfacce Funzionali con Espressioni Lambda
Le interfacce funzionali sono strettamente legate alle espressioni lambda. In Java, le espressioni lambda sono considerate come istanze di interfacce funzionali. Questo significa che possiamo assegnare una lambda a una variabile di tipo interfaccia funzionale o passare una lambda come argomento a un metodo che accetta un’interfaccia funzionale.
Esempio di Implementazione con Lambda:
Calcolatore somma = (a, b) -> a + b;
Calcolatore prodotto = (a, b) -> a * b;
int risultatoSomma = somma.calcola(5, 3); // Restituisce 8
int risultatoProdotto = prodotto.calcola(5, 3); // Restituisce 15In questo esempio, abbiamo creato due implementazioni dell’interfaccia Calcolatore utilizzando espressioni lambda.
Interfacce Funzionali Predefinite
Java fornisce un set di interfacce funzionali predefinite nel pacchetto java.util.function. Queste interfacce sono generiche e coprono i casi d’uso più comuni nella programmazione funzionale.
Ecco alcune delle interfacce funzionali predefinite più utilizzate:
-
Predicate<T>: rappresenta una funzione che accetta un argomento di tipoTe restituisce unboolean. È comunemente usato per testare una condizione.Esempio:
Predicate<Integer> isPari = numero -> numero % 2 == 0; boolean risultato = isPari.test(4); // Restituisce true -
Function<T, R>: rappresenta una funzione che accetta un argomento di tipoTe restituisce un risultato di tipoR.Esempio:
Function<String, Integer> lunghezzaStringa = str -> str.length(); int lunghezza = lunghezzaStringa.apply("Hello"); // Restituisce 5 -
Consumer<T>: rappresenta un’operazione che accetta un argomento di tipoTe non restituisce nulla. È tipicamente utilizzato per eseguire operazioni su un oggetto senza restituire un risultato.Esempio:
Consumer<String> stampa = str -> System.out.println(str); stampa.accept("Ciao, mondo!"); // Stampa "Ciao, mondo!" sulla console -
Supplier<T>: rappresenta una funzione che non accetta argomenti ma restituisce un risultato di tipoT. È utilizzato per fornire istanze o valori.Esempio:
Supplier<Double> generaNumeroCasuale = () -> Math.random(); double numero = generaNumeroCasuale.get(); // Restituisce un numero casuale
Vantaggi dell’Uso delle Interfacce Funzionali
-
Codice più Conciso: Le espressioni lambda permettono di scrivere implementazioni di interfacce funzionali in modo più breve rispetto alle classi anonime.
-
Maggiore Leggibilità: Eliminando il boilerplate delle classi anonime, il codice diventa più leggibile e focalizzato sulla logica dell’operazione.
-
Facilitano la Programmazione Funzionale: Consentono di passare comportamenti (funzioni) come argomenti ai metodi, aprendo la strada a uno stile di programmazione più funzionale.
Composizione di Funzioni
Molte interfacce funzionali predefinite forniscono metodi default per comporre funzioni.
Esempio con Function:
Function<Integer, Integer> raddoppia = x -> x * 2;
Function<Integer, Integer> quadrato = x -> x * x;
Function<Integer, Integer> raddoppiaPoiQuadrato = raddoppia.andThen(quadrato);
int risultato = raddoppiaPoiQuadrato.apply(3); // (3 * 2) ^ 2 = 36In questo esempio, abbiamo composto due funzioni in modo che l’output della prima (raddoppia) diventi l’input della seconda (quadrato).
Creazione di Interfacce Funzionali Personalizzate
Oltre alle interfacce predefinite, è possibile definire interfacce funzionali personalizzate per adattarsi a casi d’uso specifici.
Esempio:
@FunctionalInterface
public interface Convertitore<F, T> {
T converti(F da);
}
Convertitore<String, Integer> stringaAIntero = str -> Integer.parseInt(str);
int numero = stringaAIntero.converti("100"); // Restituisce 100In questo esempio, Convertitore è un’interfaccia funzionale generica che converte un oggetto di tipo F in uno di tipo T.
Interfacce Funzionali Primitive
Java fornisce anche versioni specializzate delle interfacce funzionali per tipi primitivi, al fine di evitare l’auto-boxing e migliorare le prestazioni.
Esempio con IntPredicate:
IntPredicate isPositivo = num -> num > 0;
boolean risultato = isPositivo.test(10); // Restituisce trueBest Practices
-
Usare le Interfacce Predefinite Quando Possibile: Prima di creare un’interfaccia funzionale personalizzata, verificare se esiste già un’interfaccia predefinita che soddisfa le esigenze.
-
Mantenere le Funzioni Pure: Quando si utilizzano interfacce funzionali, è consigliabile che le funzioni siano pure, ovvero senza effetti collaterali, per facilitare il debugging e la manutenzione.
-
Documentare le Interfacce Personalizzate: Se si creano interfacce funzionali personalizzate, è importante documentarle adeguatamente per chiarire il loro scopo e il contratto del metodo astratto.
Applicazioni Pratiche
Le interfacce funzionali sono ampiamente utilizzate nelle API moderne di Java, come le Stream API, per permettere operazioni di filtraggio, trasformazione e riduzione dei dati in modo dichiarativo.
Esempio con Stream e Predicate:
List<String> nomi = Arrays.asList("Alice", "Bob", "Charlie", "David");
List<String> nomiConA = nomi.stream()
.filter(nome -> nome.startsWith("A"))
.collect(Collectors.toList()); // Restituisce ["Alice"]In questo esempio, l’interfaccia funzionale Predicate è utilizzata per filtrare la lista dei nomi.
Conclusione
Le interfacce funzionali rappresentano un ponte tra la programmazione orientata agli oggetti e la programmazione funzionale in Java. Comprenderle a fondo consente di scrivere codice più espressivo e di sfruttare appieno le potenzialità introdotte dalle espressioni lambda e dalle Stream API.
Per prepararsi a colloqui tecnici avanzati, è fondamentale non solo conoscere le interfacce funzionali predefinite, ma anche saper creare e utilizzare interfacce personalizzate, comprendendo le implicazioni in termini di design del codice e prestazioni.
8.3 Stream API
La Stream API, introdotta in Java 8, è uno strumento potente che permette di elaborare collezioni di dati in modo funzionale e dichiarativo. Questa API consente di eseguire operazioni complesse su dati in maniera efficiente, migliorando la leggibilità e la manutenibilità del codice.
8.3.1 Concetti Fondamentali degli Stream
Uno Stream è una sequenza di elementi che supporta diverse operazioni per eseguire calcoli su tali elementi. Gli Stream non memorizzano dati; invece, trasmettono i dati dalle sorgenti (come collezioni, array, generatori) attraverso una pipeline di operazioni.
Caratteristiche principali degli Stream:
-
Non modifcano la sorgente: Le operazioni su uno Stream non alterano la collezione originale.
-
Lazy evaluation: Le operazioni sono eseguite solo quando necessario, ottimizzando le prestazioni.
-
Possibilità di parallelismo: Facilita l’elaborazione parallela dei dati.
8.3.2 Operazioni Intermedie e Terminali
Le operazioni su uno Stream sono di due tipi:
-
Operazioni Intermedie: Restituiscono un nuovo Stream e sono lazy, ovvero l’esecuzione è rimandata finché non viene invocata un’operazione terminale.
-
Operazioni Terminali: Avviano l’elaborazione della pipeline e restituiscono un risultato finale o eseguono un’azione collaterale.
Operazioni Intermedie
Esempi comuni:
-
filter(Predicate<? super T> predicate): Filtra elementi in base a una condizione.Stream<Integer> numeriPari = numeri.stream() .filter(n -> n % 2 == 0); -
map(Function<? super T, ? extends R> mapper): Trasforma ogni elemento applicando una funzione.Stream<String> nomiMaiuscoli = nomi.stream() .map(String::toUpperCase); -
sorted(Comparator<? super T> comparator): Ordina gli elementi.Stream<String> nomiOrdinati = nomi.stream() .sorted(); -
limit(long maxSize): Trunca lo Stream a un numero massimo di elementi.Stream<String> primiDueNomi = nomi.stream() .limit(2);
Operazioni Terminali
Esempi comuni:
-
collect(Collector<? super T, A, R> collector): Raccoglie gli elementi in una collezione o aggrega i risultati.List<String> listaNomi = nomi.stream() .collect(Collectors.toList()); -
forEach(Consumer<? super T> action): Esegue un’azione per ogni elemento.nomi.stream() .forEach(System.out::println); -
count(): Restituisce il numero di elementi.long numeroElementi = nomi.stream() .count(); -
anyMatch(Predicate<? super T> predicate): Verifica se almeno un elemento soddisfa una condizione.boolean esisteNome = nomi.stream() .anyMatch(n -> n.equals("Mario"));
8.3.3 Elaborazione di Dati in Modo Funzionale
La Stream API permette di elaborare dati in maniera funzionale, cioè specificando cosa fare invece di come farlo. Questo approccio migliora la leggibilità del codice e riduce la possibilità di errori.
Esempio pratico:
Supponiamo di avere una lista di numeri interi e vogliamo calcolare la somma dei quadrati dei numeri pari maggiori di 10.
List<Integer> numeri = Arrays.asList(5, 12, 19, 6, 15, 8);
int sommaQuadrati = numeri.stream()
.filter(n -> n % 2 == 0) // Filtra numeri pari
.filter(n -> n > 10) // Filtra numeri maggiori di 10
.map(n -> n * n) // Calcola il quadrato
.reduce(0, Integer::sum); // Somma i risultati
System.out.println("La somma è: " + sommaQuadrati);Spiegazione passo per passo:
-
filter(n -> n % 2 == 0): Seleziona solo i numeri pari. -
filter(n -> n > 10): Seleziona numeri maggiori di 10 tra quelli già filtrati. -
map(n -> n * n): Calcola il quadrato di ogni numero filtrato. -
reduce(0, Integer::sum): Somma tutti i quadrati calcolati.
Risultato:
La somma è: 144
Dettaglio del calcolo: Solo il numero 12 soddisfa entrambe le condizioni (pari e maggiore di 10). Il quadrato di 12 è 144.
8.3.4 Altri Esempi di Utilizzo degli Stream
Esempio 1: Lista di Nomi in Maiuscolo Ordinati
List<String> nomi = Arrays.asList("Luca", "Marco", "Anna", "Paolo");
List<String> nomiMaiuscoliOrdinati = nomi.stream()
.map(String::toUpperCase)
.sorted()
.collect(Collectors.toList());
System.out.println(nomiMaiuscoliOrdinati);Output:
[ANNA, LUCA, MARCO, PAOLO]
Esempio 2: Contare le Occorrenze di Parole in un Testo
String testo = "Java è un linguaggio di programmazione. Java è utilizzato per lo sviluppo web.";
Map<String, Long> frequenzaParole = Arrays.stream(testo.split("\\W+"))
.map(String::toLowerCase)
.collect(Collectors.groupingBy(s -> s, Collectors.counting()));
frequenzaParole.forEach((parola, frequenza) ->
System.out.println(parola + ": " + frequenza));Output:
java: 2
è: 2
un: 1
linguaggio: 1
di: 1
programmazione: 1
utilizzato: 1
per: 1
lo: 1
sviluppo: 1
web: 1
8.3.5 FlatMap per Stream Complessi
L’operazione flatMap è utile quando si ha a che fare con Stream di Stream, cioè quando ogni elemento è a sua volta una collezione.
Esempio:
Supponiamo di avere una lista di liste di numeri e vogliamo creare uno Stream unico di tutti i numeri.
List<List<Integer>> listeDiNumeri = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5),
Arrays.asList(6, 7, 8, 9)
);
List<Integer> tuttiINumeri = listeDiNumeri.stream()
.flatMap(List::stream)
.collect(Collectors.toList());
System.out.println(tuttiINumeri);Output:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
8.3.6 Parallel Stream
Per sfruttare i processori multi-core, Java offre la possibilità di elaborare gli Stream in parallelo.
Esempio di utilizzo:
int sommaParallela = numeri.parallelStream()
.filter(n -> n % 2 == 0)
.mapToInt(Integer::intValue)
.sum();
System.out.println("Somma parallela: " + sommaParallela);Considerazioni:
-
Il parallelismo può migliorare le prestazioni per grandi dataset.
-
Non sempre è vantaggioso; su dataset piccoli, l’overhead potrebbe superare i benefici.
-
Attenzione ai side effects; assicurarsi che le operazioni siano thread-safe.
8.3.7 Best Practices nell’Uso degli Stream
-
Evitare Side Effects: Le funzioni usate nelle operazioni dello Stream dovrebbero essere pure, cioè senza modificare lo stato esterno.
-
Comprendere la Lazy Evaluation: Le operazioni intermedie sono eseguite solo quando si invoca un’operazione terminale.
-
Riutilizzo degli Stream: Uno Stream non può essere riutilizzato dopo un’operazione terminale; se necessario, creare un nuovo Stream.
-
Prestazioni: Usare operazioni che limitano l’elaborazione (come
limit()) il prima possibile nella pipeline per ottimizzare le prestazioni. -
Debugging: Utilizzare l’operazione
peek()per inserire punti di debug nella pipeline.
Esempio con peek():
List<String> risultato = nomi.stream()
.filter(n -> n.length() > 3)
.peek(n -> System.out.println("Dopo filtro: " + n))
.map(String::toUpperCase)
.peek(n -> System.out.println("Dopo map: " + n))
.collect(Collectors.toList());8.3.8 Conclusione
La Stream API ha rivoluzionato il modo in cui si elaborano i dati in Java, introducendo un approccio più funzionale e dichiarativo. Comprendere e saper utilizzare le operazioni intermedie e terminali consente di scrivere codice più conciso, leggibile ed efficiente.
Riepilogo dei vantaggi:
-
Leggibilità: Codice più chiaro e vicino al linguaggio naturale.
-
Efficienza: Migliore utilizzo delle risorse attraverso la lazy evaluation e il parallelismo.
-
Manutenibilità: Struttura modulare del codice facilita aggiornamenti e modifiche.
Per prepararsi a colloqui tecnici approfonditi, è fondamentale padroneggiare la Stream API, essere in grado di risolvere problemi pratici e comprendere le implicazioni delle scelte di progettazione nel codice.
8.4 Optional
La gestione dei valori nulli è da sempre una sfida in Java. L’uso improprio o non controllato di null può portare a eccezioni runtime difficili da diagnosticare, come la famigerata NullPointerException. Con l’introduzione di Java 8, la classe Optional offre una soluzione elegante a questo problema, promuovendo un approccio più sicuro e leggibile nella gestione dell’assenza di valori.
8.4.1 Il Problema dei Valori Nulli
In Java, null viene spesso utilizzato per indicare l’assenza di un valore. Tuttavia, questa pratica comporta diversi problemi:
-
NullPointerException: Dimenticare di controllare se un oggetto è
nullprima di utilizzarlo può causare eccezioni inaspettate. -
Codice Verboso: L’aggiunta di controlli nulli ovunque rende il codice meno leggibile e più difficile da mantenere.
-
Ambiguità Semantica:
nullnon fornisce informazioni sul perché un valore è assente, rendendo il codice meno intuitivo.
8.4.2 Introduzione a Optional
Optional è una classe contenitore che può o non può contenere un valore non nullo. Invece di restituire null, un metodo può restituire un Optional, indicando chiaramente che il risultato potrebbe essere assente.
Esempio senza Optional:
public String getNomeUtente(User user) {
if (user != null && user.getNome() != null) {
return user.getNome();
} else {
return "Ospite";
}
}Esempio con Optional:
public String getNomeUtente(User user) {
return Optional.ofNullable(user)
.map(User::getNome)
.orElse("Ospite");
}8.4.3 Creazione di un Optional
Esistono diversi metodi per creare un’istanza di Optional:
-
Optional.of(T value): Crea unOptionalcontenente il valore specificato. Sevalueènull, lancia unaNullPointerException.Optional<String> nome = Optional.of("Mario"); -
Optional.ofNullable(T value): Crea unOptionalche può essere vuoto sevalueènull.Optional<String> nome = Optional.ofNullable(possibileNome); -
Optional.empty(): Crea unOptionalvuoto.Optional<String> nome = Optional.empty();
8.4.4 Verifica della Presenza di un Valore
Per controllare se un Optional contiene un valore:
-
isPresent(): Restituiscetruese il valore è presente.if (nome.isPresent()) { System.out.println("Nome: " + nome.get()); } -
ifPresent(Consumer<? super T> action): Esegue l’azione specificata se il valore è presente.nome.ifPresent(n -> System.out.println("Nome: " + n));
8.4.5 Recupero del Valore
Per ottenere il valore da un Optional:
-
get(): Restituisce il valore se presente; altrimenti, lancia unaNoSuchElementException. Uso sconsigliato senza previa verifica.String valore = nome.get(); // Attenzione: può lanciare un'eccezione -
orElse(T other): Restituisce il valore se presente; altrimenti, restituisceother.String valore = nome.orElse("Valore di default"); -
orElseGet(Supplier<? extends T> supplier): Simile aorElse, maotherè ottenuto tramite unSuppliere viene eseguito solo se necessario.String valore = nome.orElseGet(() -> recuperaNomeDaDatabase()); -
orElseThrow(Supplier<? extends X> exceptionSupplier): Restituisce il valore se presente; altrimenti, lancia l’eccezione fornita.String valore = nome.orElseThrow(() -> new IllegalArgumentException("Nome non presente"));
8.4.6 Operazioni Funzionali su Optional
Optional supporta operazioni funzionali che permettono di manipolare il valore se presente:
-
map(Function<? super T, ? extends U> mapper): Applica la funzione al valore se presente e restituisce un nuovoOptional.Optional<Integer> lunghezzaNome = nome.map(String::length); -
flatMap(Function<? super T, Optional<U>> mapper): Simile amap, ma la funzione restituisce unOptionalche viene “appiattito”.Optional<String> nomeMaiuscolo = nome.flatMap(n -> Optional.of(n.toUpperCase())); -
filter(Predicate<? super T> predicate): Restituisce l’Optionaloriginale se il valore soddisfa il predicato; altrimenti, restituisce unOptionalvuoto.Optional<String> nomeConM = nome.filter(n -> n.startsWith("M"));
8.4.7 Esempio Pratico
Supponiamo di avere una lista di utenti e vogliamo ottenere l’email del primo utente verificato.
Senza Optional:
public String getEmailPrimoUtenteVerificato(List<User> utenti) {
for (User user : utenti) {
if (user != null && user.isVerificato() && user.getEmail() != null) {
return user.getEmail();
}
}
return "Email non disponibile";
}Con Optional e Stream API:
public String getEmailPrimoUtenteVerificato(List<User> utenti) {
return utenti.stream()
.filter(Objects::nonNull)
.filter(User::isVerificato)
.map(User::getEmail)
.filter(Objects::nonNull)
.findFirst()
.orElse("Email non disponibile");
}L’uso combinato di Optional e Stream API rende il codice più conciso e focalizzato sul “cosa” si vuole ottenere piuttosto che sul “come” ottenerlo.
8.4.8 Best Practices nell’Uso di Optional
-
Non Usare Optional per Variabili di Istanza o Parametri:
Optionalè pensato per i metodi che possono restituire un valore assente, non per campi o parametri di metodi.// Evitare questo public class User { private Optional<String> email; // Sconsigliato } -
Evitare
Optional.get()senza Controllo: L’uso diget()senza verificare la presenza del valore può causare eccezioni. Preferire metodi comeorElseoifPresent. -
Usare Operazioni Funzionali: Sfruttare metodi come
map,flatMapefilterper manipolare il valore in modo sicuro ed elegante. -
Non Abusare di Optional: Usare
Optionalquando ha senso semantico; non dovrebbe sostituire tutti i valori che potrebbero esserenull.
8.4.9 Limitazioni e Considerazioni
-
Performance: L’uso eccessivo di
Optionalpuò introdurre un leggero overhead. Tuttavia, il beneficio in termini di sicurezza e leggibilità spesso supera questo svantaggio. -
Compatibilità con API Esistenti: Molte API Java precedenti a Java 8 non utilizzano
Optional, quindi potrebbe essere necessario gestirenullin alcuni casi. -
Chiarezza del Codice: Sebbene
Optionalmigliori la gestione dei valori assenti, un uso improprio può rendere il codice più complesso. È importante seguire le best practices.
8.4.10 Conclusione
Optional rappresenta un avanzamento significativo nella gestione dei valori nulli in Java. Promuove uno stile di programmazione che rende esplicita la possibilità di assenza di un valore, riducendo il rischio di NullPointerException e migliorando la leggibilità del codice. Integrando Optional nelle proprie pratiche di sviluppo, gli sviluppatori possono scrivere codice più robusto, sicuro e manutenibile.
Capitolo 9: Moduli Java e Jigsaw
9.1 Sistema Modulare Introdotto in Java 9
Introduzione
Con il rilascio di Java 9, il linguaggio ha subito una delle trasformazioni più significative dalla sua creazione: l’introduzione del sistema modulare, noto anche come Project Jigsaw. Questo cambiamento ha rivoluzionato il modo in cui gli sviluppatori progettano, organizzano e distribuiscono le applicazioni Java, offrendo un controllo più fine sulla struttura e sulle dipendenze del codice.
Motivazioni dietro l’introduzione dei moduli
Prima di Java 9, l’ecosistema Java soffriva di diversi problemi legati alla gestione delle dipendenze e alla struttura monolitica del JDK:
-
Dimensioni eccessive del JDK e della JRE: Con l’aggiunta continua di nuove funzionalità nel corso degli anni, il JDK e la Java Runtime Environment (JRE) erano diventati ingombranti. Questo rendeva difficile l’uso di Java in ambienti con risorse limitate, come dispositivi mobili o applicazioni embedded.
-
Incapsulamento debole: Le classi e i pacchetti interni del JDK erano accessibili al pubblico, rendendo possibile l’uso non intenzionale di API interne. Questo poteva causare problemi di compatibilità nelle versioni successive, poiché le API interne non erano soggette alle stesse garanzie di stabilità delle API pubbliche.
-
Gestione complicata delle dipendenze: L’assenza di un sistema modulare nativo portava a conflitti di classpath, noti come “JAR Hell”, dove diverse versioni della stessa libreria potevano interferire tra loro, causando errori di runtime difficili da diagnosticare.
-
Difficoltà nella manutenzione del codice: In un ambiente non modulare, era più complesso mantenere e aggiornare il codice, specialmente in progetti di grandi dimensioni con team distribuiti.
Per affrontare queste sfide, il sistema modulare è stato introdotto con i seguenti obiettivi:
-
Modularizzare il JDK: Scomporre il JDK in moduli più piccoli e indipendenti per migliorare la flessibilità e ridurre le dimensioni della JRE.
-
Migliorare l’incapsulamento: Consentire ai moduli di nascondere le proprie implementazioni interne, esponendo solo le API pubbliche necessarie.
-
Fornire un sistema di gestione delle dipendenze: Introdurre un meccanismo nativo per dichiarare e risolvere le dipendenze tra moduli, migliorando la robustezza delle applicazioni.
-
Supportare la decomposizione delle applicazioni: Facilitare la suddivisione delle applicazioni in moduli chiaramente definiti, migliorando la manutenibilità e la riusabilità del codice.
Vantaggi dell’uso dei moduli
L’adozione del sistema modulare offre numerosi benefici che influenzano positivamente lo sviluppo e l’esecuzione delle applicazioni Java.
1. Incapsulamento Forte
I moduli permettono di definire esplicitamente quali pacchetti sono esportati e quali rimangono interni. Questo controllo migliora l’incapsulamento, poiché le classi interne non sono più accessibili al di fuori del modulo a meno che non vengano esportate intenzionalmente. Ciò riduce il rischio di dipendenze accidentali da API non pubbliche e migliora la sicurezza del codice.
2. Gestione Esplicita delle Dipendenze
Ogni modulo dichiara le proprie dipendenze tramite il file module-info.java. Questo rende le dipendenze chiare e verificabili sia in fase di compilazione che di esecuzione. Il sistema modulare previene l’avvio dell’applicazione se le dipendenze richieste non sono soddisfatte, riducendo i possibili errori di runtime.
3. Riduzione delle Dimensioni dell’Applicazione
Grazie alla modularizzazione, è possibile creare runtime Java personalizzati che includono solo i moduli necessari per l’applicazione. Questo è particolarmente utile per:
-
Applicazioni desktop e server: Ridurre il footprint dell’applicazione può migliorare le prestazioni e ridurre i costi di distribuzione.
-
Dispositivi con risorse limitate: In ambienti come l’Internet delle Cose (IoT), l’efficienza e le dimensioni ridotte sono cruciali.
4. Miglioramento delle Prestazioni
L’uso dei moduli può portare a:
-
Avvio più rapido: Caricando solo i moduli necessari, il tempo di avvio dell’applicazione può essere ridotto.
-
Ottimizzazioni del compilatore e del runtime: Il sistema modulare fornisce al compilatore e alla JVM maggiori informazioni sul codice, consentendo ottimizzazioni più aggressive.
5. Maggiore Sicurezza
Limitando l’accesso alle API interne e riducendo la superficie di attacco, il sistema modulare contribuisce a migliorare la sicurezza delle applicazioni. I moduli possono essere firmati e verificati separatamente, aggiungendo un ulteriore livello di protezione.
6. Facilità di Manutenzione e Evoluzione del Codice
La modularizzazione incoraggia una progettazione del codice più pulita e organizzata. I vantaggi includono:
-
Riutilizzo del codice: Moduli ben definiti possono essere facilmente riutilizzati in diversi progetti.
-
Aggiornamenti isolati: È possibile aggiornare un modulo senza dover modificare l’intera applicazione, a condizione che l’interfaccia pubblica rimanga compatibile.
-
Collaborazione efficiente: I team possono lavorare su moduli separati in parallelo, riducendo i conflitti e migliorando la produttività.
7. Risoluzione dei Conflitti di Classpath
Il sistema modulare elimina molti problemi associati al classpath tradizionale:
-
Nessun più “JAR Hell”: I moduli hanno nomi univoci e il sistema di moduli gestisce le versioni e le dipendenze, prevenendo conflitti.
-
Isolamento delle classi: Le classi non esportate non sono visibili ad altri moduli, riducendo il rischio di collisioni.
Esempio Pratico
Consideriamo un’applicazione che utilizza una libreria per l’elaborazione XML e un’altra per l’accesso al database. Senza modularizzazione, tutte le classi sono caricate nel classpath globale, aumentando il rischio di conflitti. Con il sistema modulare:
-
Ogni libreria è un modulo con un proprio
module-info.javache dichiara quali pacchetti esporta e di quali moduli dipende. -
L’applicazione principale dichiara le dipendenze dai moduli necessari, rendendo il sistema più robusto e prevedibile.
Conclusione
L’introduzione del sistema modulare in Java 9 rappresenta un passo significativo nell’evoluzione del linguaggio, affrontando sfide storiche legate alla gestione delle dipendenze, all’incapsulamento e alle dimensioni delle applicazioni. L’adozione dei moduli consente agli sviluppatori di creare applicazioni più sicure, efficienti e manutenibili.
Nel prossimo paragrafo, approfondiremo come creare e utilizzare i moduli, esplorando il file module-info.java e le pratiche migliori per l’esportazione e l’importazione dei pacchetti.
9.2 Creazione e Utilizzo dei Moduli
Con l’introduzione del sistema modulare in Java 9, è diventato possibile organizzare il codice in moduli ben definiti, migliorando l’incapsulamento e la gestione delle dipendenze. In questa sezione, esploreremo come creare e utilizzare i moduli in Java, concentrandoci sul file module-info.java, sull’esportazione e l’importazione di pacchetti, e sulle implicazioni pratiche di questa nuova struttura.
9.2.1 Il File module-info.java
Il cuore di ogni modulo Java è il file module-info.java. Questo file, posizionato alla radice del modulo, definisce il nome del modulo e specifica quali pacchetti vengono esportati e quali dipendenze verso altri moduli sono necessarie.
Sintassi di Base:
module nome.modulo {
// dichiarazioni
}Ad esempio:
module com.example.mioModulo {
exports com.example.pacchettoPubblico;
requires java.sql;
}Spiegazione:
-
module com.example.mioModulo: Definisce il nome univoco del modulo. Si consiglia di seguire le convenzioni dei nomi dei pacchetti per evitare conflitti.
-
exports com.example.pacchettoPubblico: Specifica che il pacchetto
com.example.pacchettoPubblicoè accessibile ad altri moduli. Solo i pacchetti esportati possono essere utilizzati da codice esterno. -
requires java.sql: Indica che il modulo dipende dal modulo
java.sql. Questo permette al modulo di utilizzare le API fornite dajava.sql.
9.2.2 Esportazione di Pacchetti
Per rendere i pacchetti accessibili ad altri moduli, è necessario esportarli esplicitamente utilizzando la direttiva exports.
Esempio:
Supponiamo di avere la seguente struttura di pacchetti:
-
com.example.modulo-
publico(pacchetto che vogliamo esportare)- Classi pubbliche
-
interno(pacchetto interno che non vogliamo esportare)- Classi di utilità interne
-
Il file module-info.java sarà:
module com.example.modulo {
exports com.example.modulo.publico;
}Nota Importante:
- Se un pacchetto non è esportato, le sue classi pubbliche non saranno accessibili da altri moduli. Questo rafforza l’incapsulamento e riduce le possibilità di utilizzo non intenzionale di API interne.
9.2.3 Importazione di Moduli (Requires)
Per utilizzare classi o interfacce da altri moduli, è necessario dichiarare le dipendenze con la direttiva requires.
Esempio:
Se il nostro modulo necessita delle funzionalità offerte dal modulo java.logging, dobbiamo aggiungere:
module com.example.modulo {
exports com.example.modulo.publico;
requires java.logging;
}Tipi di Dipendenze:
-
requires: Indica una dipendenza obbligatoria. Il modulo non può essere compilato o eseguito senza il modulo richiesto.
-
requires transitive: Propaga la dipendenza ai moduli che dipendono dal nostro modulo. Se il modulo A
requires transitiveil modulo B, e il modulo C dipende da A, allora C avrà accesso anche a B.
Esempio di requires transitive:
module com.example.moduloA {
exports com.example.moduloA.api;
requires transitive com.example.moduloB;
}In questo caso, qualsiasi modulo che richiede com.example.moduloA avrà automaticamente accesso alle API esportate da com.example.moduloB.
9.2.4 Servizi e Fornitori (Uses e Provides)
Il sistema modulare supporta il meccanismo dei servizi, permettendo l’implementazione di principi di inversione del controllo e di design flessibili.
Definizione di un Servizio:
Supponiamo di avere un’interfaccia com.example.servizio.MioServizio.
Il modulo che utilizza il servizio:
module com.example.utilizzatore {
requires com.example.servizio;
uses com.example.servizio.MioServizio;
}Il modulo che fornisce l’implementazione:
module com.example.fornitore {
requires com.example.servizio;
provides com.example.servizio.MioServizio with com.example.fornitore.MioServizioImpl;
}Spiegazione:
-
uses: Indica che il modulo utilizza un servizio specificato.
-
provides … with …: Indica che il modulo fornisce un’implementazione per il servizio.
9.2.5 Esempio Pratico: Creazione di un Modulo Semplice
Supponiamo di voler creare un modulo che fornisce funzionalità matematiche avanzate.
Passo 1: Struttura dei File
moduli/
└── com.example.matematica
├── module-info.java
└── com
└── example
└── matematica
├── Algebra.java
└── Geometria.java
Contenuto di module-info.java:
module com.example.matematica {
exports com.example.matematica;
}Contenuto di Algebra.java:
package com.example.matematica;
public class Algebra {
public static int quadrato(int x) {
return x * x;
}
}Passo 2: Compilazione del Modulo
Da linea di comando:
javac -d out/com.example.matematica $(find . -name "*.java")Passo 3: Utilizzo del Modulo in un Altro Modulo
Creiamo un altro modulo che utilizza com.example.matematica.
Struttura dei File:
moduli/
└── com.example.app
├── module-info.java
└── com
└── example
└── app
└── Main.java
Contenuto di module-info.java:
module com.example.app {
requires com.example.matematica;
}Contenuto di Main.java:
package com.example.app;
import com.example.matematica.Algebra;
public class Main {
public static void main(String[] args) {
int risultato = Algebra.quadrato(5);
System.out.println("Il quadrato di 5 è: " + risultato);
}
}Compilazione e Esecuzione:
Compilazione:
javac --module-path out -d out/com.example.app $(find . -name "*.java")Esecuzione:
java --module-path out -m com.example.app/com.example.app.Main9.2.6 Vantaggi dell’Utilizzo dei Moduli
-
Incapsulamento Forte: I moduli permettono di controllare esattamente quali parti del codice sono accessibili dall’esterno.
-
Gestione delle Dipendenze: Le dipendenze tra moduli sono dichiarate esplicitamente, riducendo i problemi di conflitti di versione e classi duplicate.
-
Riduzione della Superficie di Attacco: Esportando solo i pacchetti necessari, si riduce la possibilità che codice esterno acceda a parti sensibili dell’applicazione.
-
Miglioramento delle Prestazioni: Il sistema modulare permette alla JVM di ottimizzare il caricamento delle classi e l’uso della memoria.
9.2.7 Best Practices
-
Nominare i Moduli in Modo Unico: Utilizzare il reverse domain name notation (ad esempio,
com.example.modulo) per evitare conflitti. -
Esportare Solo il Necessario: Limitare l’esportazione ai soli pacchetti che devono essere utilizzati da altri moduli.
-
Evitare Dipendenze Cicliche: Progettare i moduli in modo che le dipendenze siano unidirezionali.
-
Documentare le API Pubbliche: Fornire una chiara documentazione per le parti del modulo che sono destinate all’uso esterno.
-
Utilizzare
requires transitivecon Cautela: Propagare le dipendenze solo quando è realmente necessario.
9.2.8 Considerazioni Finali
L’introduzione del sistema modulare rappresenta un passo significativo nell’evoluzione di Java, offrendo strumenti potenti per la gestione del codice su larga scala. Comprendere come creare e utilizzare i moduli è fondamentale per sfruttare appieno le potenzialità del linguaggio nelle sue versioni più recenti.
Per i nuovi sviluppatori, familiarizzare con i moduli fin dall’inizio aiuterà a costruire applicazioni meglio organizzate e più sicure. Per gli sviluppatori esperti, l’adozione dei moduli può richiedere un adattamento delle pratiche esistenti, ma porta benefici significativi in termini di manutenzione e qualità del codice.
Esercizio Consigliato:
Creare un progetto composto da almeno tre moduli interdipendenti, sperimentando con l’esportazione selettiva dei pacchetti e l’utilizzo di servizi tramite uses e provides. Questo aiuterà a consolidare la comprensione pratica dei concetti discussi.
9.3 Compatibilità e Migrazione
Il sistema modulare introdotto in Java 9 rappresenta un cambiamento significativo nel modo in cui le applicazioni Java sono progettate e gestite. Per gli sviluppatori con applicazioni esistenti, la migrazione al nuovo sistema può sembrare un compito impegnativo. In questa sezione, esamineremo come adattare le applicazioni esistenti al sistema modulare, affrontando le sfide di compatibilità e fornendo linee guida pratiche per una migrazione efficace.
9.3.1 Perché Migrare al Sistema Modulare
Prima di iniziare il processo di migrazione, è importante comprendere i vantaggi offerti dal sistema modulare:
-
Incapsulamento Migliorato: I moduli permettono di controllare con precisione quali parti del codice sono esposte ad altri moduli, migliorando la sicurezza e la manutenibilità.
-
Riduzione delle Dimensioni: Con strumenti come
jlink, è possibile creare runtime personalizzati che includono solo i moduli necessari, riducendo le dimensioni dell’applicazione. -
Prestazioni Ottimizzate: Il sistema modulare può migliorare i tempi di avvio e l’efficienza complessiva dell’applicazione.
-
Gestione delle Dipendenze: I moduli definiscono esplicitamente le loro dipendenze, facilitando la gestione delle versioni e prevenendo conflitti.
9.3.2 Preparazione alla Migrazione
Prima di iniziare la migrazione, è consigliabile:
-
Analizzare l’Applicazione: Identificare tutte le dipendenze interne ed esterne, compresi i JAR di terze parti.
-
Verificare le Dipendenze: Controllare se le librerie utilizzate sono già modularizzate o se esistono versioni aggiornate compatibili con Java 9 o superiore.
-
Valutare l’Uso della Riflessività: L’uso intensivo della riflessione può causare problemi, poiché l’accesso ai membri non pubblici è più restrittivo nei moduli.
9.3.3 Strategie di Migrazione
Esistono diverse strategie per migrare un’applicazione esistente:
9.3.3.1 Modularizzazione Graduale
Iniziare creando moduli per le parti dell’applicazione che non dipendono da librerie non modularizzate.
-
Passo 1: Aggiungere un file
module-info.javaalle componenti interne che possono essere facilmente modularizzate. -
Passo 2: Utilizzare moduli automatici per le dipendenze non modularizzate. Java tratta i JAR tradizionali come moduli automatici, assegnando loro un nome di modulo basato sul nome del JAR.
Esempio:
Supponiamo di avere un JAR esterno legacy-library.jar. Puoi utilizzarlo come modulo automatico:
module com.example.myapp {
requires legacy.library;
}9.3.3.2 Migrazione Completa
Per applicazioni più piccole o quando tutte le dipendenze sono modularizzate:
-
Passo 1: Creare file
module-info.javaper tutti i componenti interni. -
Passo 2: Aggiornare tutte le dipendenze esterne a versioni modularizzate.
-
Passo 3: Rimuovere o sostituire le librerie non più mantenute.
9.3.4 Risoluzione delle Questioni di Compatibilità
9.3.4.1 Accesso Riflessivo Restringente
Il sistema modulare limita l’accesso riflessivo ai membri non pubblici. Se l’applicazione utilizza la riflessione per accedere a membri privati o di pacchetto, potrebbe lanciare IllegalAccessException.
- Soluzione: Utilizzare l’opzione
--add-opensalla JVM per consentire l’accesso riflessivo temporaneo.
Esempio:
java --add-opens com.example.myapp/module=ALL-UNNAMED -jar myapp.jar9.3.4.2 Conflitti di Nomi di Modulo
Se due moduli automatici hanno lo stesso nome, si verifica un errore.
- Soluzione: Rinominare uno dei JAR o modularizzare uno dei moduli per assegnare un nome univoco.
9.3.4.3 Dipendenze Non Modularizzate
Le librerie esterne non modularizzate possono causare problemi.
-
Soluzione Temporanea: Utilizzare moduli automatici.
-
Soluzione a Lungo Termine: Contattare i mantenitori della libreria o contribuire alla sua modularizzazione.
9.3.5 Passi Pratici per la Migrazione
9.3.5.1 Creare il File module-info.java
Per ogni componente dell’applicazione, creare un file module-info.java che dichiara:
-
Nome del Modulo: Solitamente basato sul nome del pacchetto principale.
-
Dipendenze: Moduli richiesti con
requires. -
Esportazioni: Pacchetti pubblici con
exports.
Esempio:
module com.example.myapp {
requires java.sql;
requires com.example.utils;
exports com.example.myapp.api;
}9.3.5.2 Compilare i Moduli
Utilizzare javac specificando il percorso dei moduli:
javac -d mods/com.example.myapp \
--module-path mods \
src/com.example.myapp/module-info.java \
src/com.example.myapp/com/example/myapp/*.java9.3.5.3 Testare l’Applicazione
Eseguire l’applicazione con il modulo principale:
java --module-path mods -m com.example.myapp/com.example.myapp.Main9.3.6 Utilizzo di Strumenti di Analisi
9.3.6.1 jdeps
Lo strumento jdeps aiuta a comprendere le dipendenze dell’applicazione.
Esempio:
jdeps --multi-release 9 --module-path mods --check com.example.myapp.jarQuesto comando mostra le dipendenze e aiuta a identificare i moduli richiesti.
9.3.7 Considerazioni sulla Compatibilità
9.3.7.1 Versioni di Java
Assicurarsi che l’applicazione e tutte le dipendenze siano compatibili con Java 9 o superiore.
9.3.7.2 API Deprecate
Verificare l’uso di API deprecate che potrebbero essere state rimosse o modificate.
9.3.8 Migrazione di Applicazioni Legacy
Per applicazioni molto grandi o legacy:
-
Approccio Graduale: Modularizzare nuove funzionalità mentre il codice esistente rimane nel classpath tradizionale.
-
Bridge tra Moduli e Classpath: Utilizzare l’opzione
--patch-moduleper includere classi dal classpath in un modulo.
Esempio:
java --module-path mods --patch-module com.example.myapp=classes \
-m com.example.myapp/com.example.myapp.Main9.3.9 Benefici a Lungo Termine
Nonostante la migrazione possa richiedere tempo e sforzo, i benefici includono:
-
Migliore Manutenibilità: Codice più organizzato e separato in moduli logici.
-
Sicurezza Rafforzata: Controllo sull’accesso alle classi e ai pacchetti.
-
Facilitazione dell’Integrazione Continua: Gestione più semplice delle dipendenze e delle versioni.
9.3.10 Risorse Aggiuntive
-
Documentazione Ufficiale: Guide to Migrating to Module System
-
Community: Forum e gruppi di sviluppatori Java per condividere esperienze e soluzioni.
Conclusione
La migrazione al sistema modulare di Java richiede una comprensione approfondita delle nuove funzionalità e un approccio strategico. Affrontando gradualmente la modularizzazione e sfruttando gli strumenti a disposizione, è possibile adattare le applicazioni esistenti per beneficiare delle migliorie offerte da Java 9 e versioni successive. Questo processo non solo modernizza l’applicazione ma prepara anche la base per future evoluzioni tecnologiche.
Capitolo 10: Evoluzione da Java 5 a Java 21
10.1 Principali Novità di Ogni Versione
In questa sezione, esploreremo le principali funzionalità e miglioramenti introdotti in ciascuna versione di Java, dalla versione 5 alla versione 21. Comprendere l’evoluzione del linguaggio non solo aiuta a sfruttare al meglio le sue capacità, ma è anche fondamentale per mantenere e aggiornare applicazioni esistenti.
Java 5 (Tiger)
Rilasciato nel 2004, Java 5 ha introdotto cambiamenti significativi al linguaggio:
-
Generics: Permettono di definire classi, interfacce e metodi parametrizzati, migliorando la sicurezza dei tipi e riducendo la necessità di cast espliciti.
-
Annotations: Forniscono un modo per aggiungere meta-informazioni al codice, utilizzate per configurazione, documentazione e trattamenti a tempo di compilazione o esecuzione.
-
Enhanced for loop: Una sintassi semplificata per iterare su array e collezioni, migliorando la leggibilità del codice.
-
Autoboxing/Unboxing: Conversione automatica tra tipi primitivi e i loro wrapper object (es.
inteInteger), semplificando le operazioni con tipi primitivi e oggetti. -
Varargs (Arguments variabili): Consentono di definire metodi che accettano un numero variabile di argomenti, aumentando la flessibilità delle API.
-
Enumerazioni (
enum): Un tipo di dato speciale per definire un insieme di costanti, migliorando la sicurezza e la leggibilità del codice.
Java 6 (Mustang)
Rilasciato nel 2006, Java 6 si è focalizzato su miglioramenti delle performance e del supporto per strumenti:
-
Miglioramenti alle API: Aggiornamenti a JDBC 4.0 per l’accesso ai database, integrazione di Web Services tramite JAX-WS, e supporto per linguaggi di scripting come JavaScript con il motore Rhino.
-
Compiler API: Permette di accedere al compilatore Java da codice Java, abilitando la compilazione dinamica.
-
Monitoring e Management: Miglioramenti a JMX (Java Management Extensions) e nuovi strumenti di diagnostica per monitorare le applicazioni in esecuzione.
-
Aggiornamenti alla JVM: Ottimizzazioni delle performance, miglioramenti al garbage collector e al tempo di avvio delle applicazioni.
Java 7 (Dolphin)
Rilasciato nel 2011, Java 7 ha introdotto diverse funzionalità linguistiche e miglioramenti:
-
Diamond Operator (
<>): Sintassi semplificata per l’uso dei generics, riducendo la verbosità nella dichiarazione dei tipi. -
Strings in
switch: Possibilità di utilizzare le stringhe nelle espressioniswitch, aumentando la flessibilità del controllo di flusso. -
Try-with-resources: Gestione automatica delle risorse che implementano l’interfaccia
AutoCloseable, semplificando il codice di gestione delle risorse. -
Miglioramenti alle eccezioni: Supporto per multi-catch (cattura di più eccezioni in un unico blocco
catch) e rethrow di eccezioni con tipi più specifici. -
NIO.2 (New I/O): Nuova API per I/O, con supporto migliorato per il file system, accesso asincrono ai file e gestione avanzata dei percorsi.
-
Fork/Join Framework: Supporto per il parallelismo su architetture multicore, facilitando la suddivisione e l’elaborazione parallela dei compiti.
Java 8
Rilasciato nel 2014, Java 8 è una delle versioni più significative, introducendo la programmazione funzionale:
-
Lambda Expressions: Permettono di trattare i comportamenti come dati, facilitando la scrittura di codice conciso e funzionale.
-
Stream API: Una nuova API per elaborare collezioni in modo dichiarativo e parallelo, migliorando le performance e la leggibilità.
-
Functional Interfaces: Interfacce con un unico metodo astratto, utilizzate con le lambda expressions, come
Predicate,Function,Consumer. -
Optional: Una classe per gestire valori che possono essere null, riducendo il rischio diNullPointerException. -
Date and Time API: Una nuova API per gestire date e orari (pacchetto
java.time), sostituendo le classi obsolete dijava.util.Dateejava.util.Calendar. -
Metodi predefiniti nelle interfacce: Possibilità di definire metodi con implementazione all’interno delle interfacce, permettendo l’evoluzione delle API senza rompere la compatibilità.
Java 9
Rilasciato nel 2017, Java 9 ha introdotto:
-
Sistema Modulare (Project Jigsaw): Introduzione dei moduli per migliorare la struttura, l’incapsulamento e la sicurezza delle applicazioni, riducendo le dimensioni del runtime.
-
JShell: Un REPL (Read-Eval-Print Loop) per Java, facilitando l’esplorazione interattiva del codice e il prototyping.
-
Miglioramenti alle Stream API: Metodi aggiuntivi come
takeWhile(),dropWhile(),iterate(), per operazioni più avanzate sui flussi di dati. -
Interfacce private: Possibilità di definire metodi privati all’interno delle interfacce per riutilizzare codice comune tra metodi predefiniti.
-
API di Process Handling: Miglioramenti per la gestione e il controllo dei processi di sistema.
Java 10
Rilasciato nel 2018, Java 10 ha introdotto:
-
Tipo
varlocale: Inferenza del tipo per le variabili locali con la parola chiavevar, riducendo la verbosità senza perdere la sicurezza dei tipi. -
Miglioramenti alla Garbage Collection: Ottimizzazioni e introduzione di Garbage Collector sperimentali come G1 per migliorare le performance.
-
Consolidamento del JDK: Integrazione di strumenti e librerie per semplificare lo sviluppo e la distribuzione.
Java 11
Rilasciato nel 2018, Java 11 è una release LTS (Long-Term Support):
-
Lettura di Stringhe da File: Metodi di convenienza in
Filesper leggere e scrivere stringhe in modo più semplice. -
Esecuzione di file Java: Possibilità di eseguire script Java direttamente con il comando
java, senza compilazione esplicita. -
Nuove API HTTP Client: Una nuova API per HTTP/2 e WebSocket, con supporto per richieste sincrone e asincrone.
-
Deprecazioni e Rimozioni: Rimozione del supporto per applet e Java Web Start, e di strumenti obsoleti come
javaws.
Java 12
Rilasciato nel 2019:
-
Switch Expressions (preview): Miglioramenti alla sintassi dello
switch, permettendo di usarlo come espressione e non solo come dichiarazione. -
JVM Constants API: Una nuova API per modellare costanti di classe in modo estensibile.
Java 13
Rilasciato nel 2019:
-
Text Blocks (preview): Introduzione di blocchi di testo multi-linea per stringhe, semplificando la gestione di testi formattati.
-
Reimplementazione dello Switch Expression: Ulteriori miglioramenti alla sintassi e funzionalità dello
switch.
Java 14
Rilasciato nel 2020:
-
Pattern Matching per
instanceof(preview): Semplificazione del casting dopo un controllo coninstanceof, riducendo il boilerplate code. -
Records (preview): Una nuova sintassi per dichiarare classi che sono semplici contenitori di dati immutabili.
-
NullPointerException migliorato: Messaggi di errore più dettagliati per facilitare il debug.
Java 15
Rilasciato nel 2020:
-
Sealed Classes (preview): Permettono di restringere quali classi o interfacce possono estendere o implementare una classe o interfaccia, migliorando il controllo sull’ereditarietà.
-
Hidden Classes: Classi che non possono essere utilizzate direttamente dal bytecode e sono usate da framework che generano classi dinamicamente.
-
Z Garbage Collector (ZGC): Diventa una funzionalità stabile, offrendo tempi di pausa estremamente bassi per la garbage collection.
Java 16
Rilasciato nel 2021:
-
Records: Diventano funzionalità definitiva, permettendo di creare classi di dati immutabili con sintassi concisa.
-
Pattern Matching per
instanceof: Diventa funzionalità definitiva, migliorando la leggibilità e la sicurezza del codice. -
Miglioramenti all’API Stream: Metodi come
toList()per una raccolta più semplice dei risultati.
Java 17
Rilasciato nel 2021, Java 17 è una release LTS:
-
Sealed Classes: Diventano funzionalità definitiva, offrendo maggior controllo sull’ereditarietà e l’estendibilità delle classi.
-
Pattern Matching per
switch(preview): Estende il pattern matching all’istruzioneswitch, aumentando la potenza espressiva. -
Deprecazioni e Rimozioni: Rimozione di funzionalità obsolete, come il Security Manager, per snellire la piattaforma.
Java 18
Rilasciato nel 2022:
-
UTF-8 di default: Il charset predefinito per la codifica dei caratteri è ora UTF-8, garantendo consistenza tra diverse piattaforme.
-
Simple Web Server: Un semplice server web integrato per il testing e lo sviluppo, accessibile tramite riga di comando.
-
Vector API (seconda incubazione): API per supportare l’elaborazione vettoriale, migliorando le performance per operazioni numeriche.
Java 19
Rilasciato nel 2022:
-
Virtual Threads (preview): Introduzione di thread leggeri per migliorare la concorrenza e semplificare la gestione dei thread.
-
Pattern Matching per
switch(seconda preview): Ulteriori miglioramenti e stabilizzazioni alla funzionalità. -
Foreign Function & Memory API (preview): Interazione sicura ed efficiente con codice e dati al di fuori della JVM, senza la necessità di JNI.
Java 20
Rilasciato nel 2023:
-
Scoped Values (incubazione): Una nuova modalità per condividere dati in modo sicuro tra thread, alternativa ai thread-local variables.
-
Record Patterns (preview): Estende il pattern matching ai record, permettendo deconstruzioni più potenti.
-
Terza preview di Virtual Threads e Pattern Matching per
switch: Raffinamenti basati sul feedback della community.
Java 21
Rilasciato nel 2023, Java 21 è una release LTS:
-
Virtual Threads: Diventano funzionalità definitiva, rivoluzionando la gestione della concorrenza con thread leggeri e altamente scalabili.
-
Pattern Matching per
switch: Diventa funzionalità definitiva, permettendo controlli e deconstruzioni più espressive. -
Record Patterns: Diventano funzionalità definitiva, permettendo pattern matching più ricco e conciso con i record.
-
Sequenced Collections: Introduzione di interfacce per collezioni con ordine sequenziale, unificando l’accesso ai dati ordinati.
-
String Templates (preview): Introduzione di template per la costruzione di stringhe, migliorando la leggibilità e la sicurezza rispetto alla concatenazione tradizionale.
Capitolo 10: Evoluzione da Java 5 a Java 21**
Questo riepilogo delle versioni da Java 5 a Java 21 evidenzia come il linguaggio si sia evoluto per rimanere moderno e competitivo, introducendo funzionalità che migliorano la produttività degli sviluppatori, le performance delle applicazioni e la sicurezza. Tenersi aggiornati con queste novità è fondamentale per scrivere codice efficiente e mantenibile.
10.2 Deprecazioni e Rimozioni
Nel corso delle varie release di Java, il linguaggio e la piattaforma hanno subito numerosi cambiamenti per migliorare le prestazioni, la sicurezza e la manutenibilità del codice. Un aspetto cruciale di questa evoluzione riguarda le deprecazioni e le rimozioni di API e funzionalità obsolete. Comprendere quali elementi sono stati deprecati o rimossi è fondamentale per mantenere il codice aggiornato e compatibile con le versioni più recenti di Java.
10.2.1 Comprendere Deprecazioni e Rimozioni
-
Deprecazione: Quando un’API o una funzionalità è marcata come deprecata, significa che è stata sostituita da una versione migliore o che presenta problemi noti. L’uso di elementi deprecati genera avvisi durante la compilazione, ma il codice continua a funzionare. È un avvertimento per gli sviluppatori affinché evitino l’uso di tali elementi nelle nuove implementazioni e pianifichino la migrazione del codice esistente.
-
Rimozione: Un elemento deprecato può essere eventualmente rimosso in una futura release. A quel punto, qualsiasi codice che dipende da quell’elemento non sarà più compilabile o eseguibile senza modifiche. La rimozione è un passo significativo che impone agli sviluppatori di aggiornare il proprio codice.
10.2.2 Deprecazioni e Rimozioni Significative da Java 5 a Java 21
Java 5 (JDK 1.5)
Thread.stop(),Thread.suspend(),Thread.resume(): Questi metodi sono stati deprecati a causa dei potenziali deadlock e incoerenze nello stato degli oggetti. Si raccomanda l’uso di meccanismi di controllo dell’interruzione dei thread tramite flag volatili.
Java 6 e Java 7
- Applet API: L’uso degli applet è stato scoraggiato a causa di problemi di sicurezza e della diminuzione del supporto nei browser. Sebbene non completamente rimossa, l’API è stata deprecata in attesa di una futura eliminazione.
Java 8
-
PermGenSpace: L’area di memoria PermGen è stata rimossa e sostituita con Metaspace, migliorando la gestione della memoria per le informazioni sulle classi. -
Thread.destroy()eThread.stop(Throwable): Completamente rimossi a causa dei gravi problemi di sicurezza e stabilità che potevano causare.
Java 9
-
Moduli e Incapsulamento: Con l’introduzione del sistema modulare, molte API interne (come quelle di
sun.misc.Unsafe) sono state rese inaccessibili per default. L’accesso a queste API richiede l’uso di opzioni specifiche del compilatore e della JVM. -
Deprecazione di API Java EE e CORBA: Le API legate a Java EE (come JAXB) e CORBA sono state deprecate con l’intento di rimuoverle in future release.
Java 10
- Non ci sono state deprecazioni o rimozioni significative, ma è proseguito l’avviso riguardo l’uso delle API deprecate in Java 9.
Java 11
-
Rimozione delle API Java EE e CORBA: Come preannunciato, le API deprecate in Java 9 sono state rimosse. Ciò include classi e pacchetti relativi a JAXB, JAX-WS, JAX-WS Annotation, CORBA e altri.
-
Rimozione del supporto per l’avvio di applet: L’avvio di applet tramite il comando
javaws(Java Web Start) è stato eliminato.
Java 14
- Deprecazione per la rimozione di
Nashorn JavaScript Engine: L’engine JavaScript Nashorn è stato deprecato, suggerendo l’uso di alternative esterne per l’esecuzione di codice JavaScript.
Java 15
-
Rimozione di
Nashorn JavaScript Engine: Nashorn è stato completamente rimosso dalla JDK. -
Deprecazione di
RMI Activation: L’API di attivazione RMI è stata deprecata a causa del suo limitato utilizzo e della complessità di mantenimento.
Java 17
-
Rimozione di
RMI Activation: Completando il processo iniziato in Java 15, l’API di attivazione RMI è stata rimossa. -
Deprecazione per la rimozione dell’
Applet API: L’Applet APIè stata deprecata per la rimozione in una futura release.
Java 18 e Java 19
- Non sono state annunciate rimozioni significative, ma è continuato il processo di deprecazione di elementi obsoleti.
Java 20
- Deprecazione di vecchie API di sicurezza: Alcune API legate alla sicurezza, obsolete e non più sicure, sono state deprecate in favore di versioni più aggiornate.
Java 21
-
Rimozione dell’
Applet API: L’API per gli applet è stata finalmente rimossa, segnando la fine di un’era per le applicazioni web integrate. -
Deprecazione per la rimozione di alcuni algoritmi crittografici: Alcuni algoritmi considerati insicuri sono stati deprecati per la rimozione, incoraggiando gli sviluppatori a migrare verso alternative più robuste.
10.2.3 Impatto sul Codice Esistente
La rimozione di API e funzionalità può avere un impatto significativo sulle applicazioni legacy. È essenziale che gli sviluppatori:
-
Monitorino gli avvisi di deprecazione: Gli avvisi durante la compilazione indicano quali parti del codice necessitano di attenzione.
-
Aggiornino gradualmente il codice: Pianificare gli aggiornamenti per sostituire le API deprecate con le loro controparti più recenti.
-
Testino accuratamente le applicazioni: Dopo le modifiche, è fondamentale effettuare test per assicurarsi che l’applicazione funzioni correttamente.
10.2.4 Strategie per Gestire Deprecazioni e Rimozioni
-
Utilizzare Tool di Analisi del Codice: Strumenti come jdeps possono aiutare a identificare le dipendenze dalle API deprecate o rimosse.
-
Consultare la Documentazione Ufficiale: Le note di rilascio di ogni versione di Java forniscono dettagli sulle deprecazioni e rimozioni.
-
Adottare Best Practices di Codifica: Evitare l’uso di API interne non documentate e aderire agli standard consigliati.
-
Formazione Continua: Mantenersi aggiornati sulle ultime modifiche del linguaggio e della piattaforma.
10.2.5 Esempio Pratico: Migrazione dall’API Java EE Rimossa in Java 11
Supponiamo di avere un’applicazione che utilizza JAXB per la manipolazione di XML:
import javax.xml.bind.JAXBContext;
import javax.xml.bind.JAXBException;
// Codice che utilizza JAXBDopo l’aggiornamento a Java 11, questo codice non compila più perché il pacchetto javax.xml.bind è stato rimosso. Per risolvere il problema:
- Aggiungere le Dipendenze Necessarie: JAXB è ora disponibile come libreria esterna. È possibile aggiungerla al progetto tramite un gestore di dipendenze come Maven o Gradle.
Esempio con Maven:
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>- Aggiornare le Importazioni se Necessario: In alcuni casi, potrebbe essere necessario aggiornare le importazioni ai nuovi pacchetti.
10.2.6 Conclusione
Le deprecazioni e rimozioni sono parte integrante dell’evoluzione di Java. Sebbene possano presentare sfide, offrono anche l’opportunità di migliorare e modernizzare il codice. Mantenere il codice aggiornato non solo garantisce la compatibilità con le ultime versioni del linguaggio, ma può anche portare benefici in termini di prestazioni, sicurezza e manutenibilità.
È essenziale adottare un approccio proattivo, monitorando costantemente gli avvisi di deprecazione e pianificando le migrazioni necessarie. In questo modo, gli sviluppatori possono assicurare che le loro applicazioni rimangano robuste e al passo con l’evoluzione del linguaggio Java.
10.3 Miglioramenti delle Prestazioni
Nel corso delle versioni, Java ha subito numerosi miglioramenti che hanno ottimizzato le prestazioni sia del linguaggio che della Java Virtual Machine (JVM). Questi miglioramenti sono stati fondamentali per garantire che Java rimanesse competitivo e adatto alle esigenze delle applicazioni moderne, che richiedono elevata efficienza e scalabilità.
Ottimizzazioni del Linguaggio
-
Generics e Type Erasure (Java 5):
L’introduzione dei Generics ha permesso di scrivere codice più sicuro e leggibile, evitando casting espliciti. Grazie al Type Erasure, i generics non introducono overhead a runtime, poiché le informazioni di tipo vengono rimosse durante la compilazione, mantenendo inalterate le prestazioni.
-
Autoboxing/Unboxing (Java 5):
Questa funzionalità automatizza la conversione tra tipi primitivi e oggetti wrapper, semplificando il codice. Tuttavia, un uso eccessivo può introdurre overhead, quindi è importante essere consapevoli del suo impatto sulle prestazioni.
-
StringBuilder invece di StringBuffer (Java 5):
La classe
StringBuilderè stata introdotta come alternativa non sincronizzata aStringBuffer, offrendo migliori prestazioni nella manipolazione delle stringhe quando non è necessaria la sicurezza dei thread. -
Lambda Expressions (Java 8):
Le espressioni lambda hanno introdotto la programmazione funzionale in Java, permettendo di scrivere codice più conciso e di sfruttare l’elaborazione parallela con l’API Stream, migliorando le prestazioni su sistemi multicore.
Esempio:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); int sum = numbers.stream().mapToInt(Integer::intValue).sum(); -
API Stream (Java 8):
L’API Stream consente elaborazioni dichiarative e potenzialmente parallele su collezioni di dati, ottimizzando l’uso delle risorse hardware.
-
Pattern Matching e Record (Java 14 e 16):
Queste funzionalità riducono la complessità del codice e permettono alla JVM di effettuare ottimizzazioni più efficaci grazie a una migliore prevedibilità del flusso di controllo.
Ottimizzazioni della JVM
-
Garbage Collector Migliorati:
-
G1 Garbage Collector (Java 7):
Il Garbage-First GC è progettato per ridurre le pause causate dalla raccolta dei rifiuti, migliorando le prestazioni in applicazioni con grandi heap di memoria.
-
Z Garbage Collector (Java 11):
ZGC offre tempi di pausa estremamente ridotti, anche con heap di dimensioni molto grandi, migliorando la reattività delle applicazioni.
-
Shenandoah GC (Java 12):
Simile a ZGC, si concentra sulla riduzione delle pause del garbage collector, migliorando le prestazioni in ambienti a bassa latenza.
-
-
Just-In-Time Compiler (JIT) Ottimizzato:
-
Tiered Compilation (Java 7):
Combina la compilazione interpretata e compilata per bilanciare tempi di avvio rapidi e prestazioni a runtime.
-
Graal JIT Compiler (Java 10+):
Un compilatore JIT avanzato che migliora l’ottimizzazione del codice a runtime, supportando anche linguaggi diversi da Java sulla JVM.
-
-
Class Data Sharing (CDS) Esteso (Java 10):
CDS riduce i tempi di avvio e l’uso della memoria condividendo tra processi le classi comuni precompilate.
-
Ahead-of-Time Compilation (AOT) (Java 9):
Consente di compilare il bytecode Java in codice nativo prima dell’esecuzione, riducendo i tempi di avvio e migliorando le prestazioni su dispositivi con risorse limitate.
-
Compressed Oops (Java 6u14):
L’uso di puntatori a oggetti compressi ottimizza l’utilizzo della memoria su JVM a 64 bit, migliorando l’efficienza del garbage collector.
Evoluzione dei Garbage Collector
-
Parallel Garbage Collector:
Migliora le prestazioni utilizzando più thread per la raccolta dei rifiuti, sfruttando i processori multicore.
-
Epsilon Garbage Collector (Java 11):
Un garbage collector “no-op” che non esegue la raccolta dei rifiuti, utile per testare le prestazioni senza l’overhead del GC.
Miglioramenti nella Concorrenza
-
Fork/Join Framework (Java 7):
Introduce un modello per dividere compiti complessi in sotto-compiti eseguibili in parallelo, migliorando l’efficienza su sistemi multicore.
-
CompletableFuture e API Concorrenza (Java 8):
Offre strumenti per la programmazione asincrona e reattiva, ottimizzando l’utilizzo delle risorse thread.
Ottimizzazioni Specifiche nelle Versioni Recenti
-
Java 15-17:
-
Hidden Classes:
Migliorano le prestazioni dei framework che generano classi dinamicamente, riducendo l’overhead della definizione di nuove classi.
-
Sealed Classes (Java 17):
Permettono al compilatore e alla JVM di effettuare ottimizzazioni basate su un set chiuso di sottoclassi.
-
-
Java 21:
-
Virtual Threads (Project Loom):
Introducono thread leggeri che permettono di gestire milioni di thread con un overhead minimo, migliorando drasticamente le prestazioni di applicazioni concorrenti.
Esempio:
Thread.startVirtualThread(() -> { // codice eseguito nel thread virtuale }); -
Record Patterns e Pattern Matching Esteso:
Migliorano la leggibilità e l’efficienza del codice, permettendo alla JVM di effettuare ottimizzazioni più aggressive.
-
Consigli per Sfruttare le Ottimizzazioni
-
Aggiornamento Costante:
Mantenere l’ambiente di sviluppo e di esecuzione aggiornato alle ultime versioni di Java per beneficiare delle ottimizzazioni introdotte.
-
Profilazione e Monitoraggio:
Utilizzare strumenti di profilazione per identificare colli di bottiglia e comprendere il comportamento dell’applicazione sotto carico.
-
Uso Appropriato delle Funzionalità:
Applicare le nuove funzionalità del linguaggio e della JVM quando pertinente, ma valutare l’impatto sulle prestazioni nel contesto specifico.
-
Consapevolezza dei Trade-off:
Comprendere che alcune funzionalità che migliorano la leggibilità del codice possono avere un costo in termini di prestazioni; è importante bilanciare questi aspetti in base alle esigenze dell’applicazione.
Conclusione
I miglioramenti delle prestazioni introdotti da Java 5 a Java 21 rappresentano un impegno costante per ottimizzare il linguaggio e la piattaforma in risposta alle esigenze in evoluzione del settore. Dalle ottimizzazioni del garbage collector ai miglioramenti nella concorrenza e nell’elaborazione parallela, Java offre agli sviluppatori gli strumenti per costruire applicazioni efficienti e scalabili. Sfruttare queste ottimizzazioni richiede una comprensione approfondita delle funzionalità disponibili e una valutazione attenta delle esigenze specifiche del progetto.
Appendice A: Argomenti Avanzati di Java
In questa appendice, esploreremo alcuni argomenti avanzati di Java che non sono stati trattati nei capitoli precedenti ma che sono fondamentali per una comprensione completa del linguaggio. Questi concetti non solo arricchiranno le tue competenze, ma sono anche spesso oggetto di discussione durante i colloqui tecnici. Affronteremo design pattern comuni, il meccanismo di reflection, le annotations, il modello di memoria di Java e aspetti avanzati dei generics.
A.1 Design Pattern in Java
A.1.1 Introduzione ai Design Pattern
I design pattern sono soluzioni ottimizzate e riutilizzabili a problemi comuni nell’ingegneria del software. Essi rappresentano pratiche consolidate che facilitano la scrittura di codice efficiente, mantenibile e scalabile. Comprendere e applicare i design pattern è essenziale per risolvere problemi complessi in modo strutturato.
A.1.2 Il Pattern Singleton
Descrizione:
Il Singleton è un design pattern creazionale che garantisce la creazione di una sola istanza di una classe e fornisce un punto di accesso globale ad essa.
Implementazione di Base:
public class Singleton {
private static Singleton instance;
private Singleton() {
// Costruttore privato per impedire l'istanziamento esterno
}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}Considerazioni:
-
Thread Safety: In un ambiente multi-thread, è necessario sincronizzare il metodo
getInstance()per evitare la creazione di istanze multiple. -
Eager Initialization: Un’alternativa è inizializzare l’istanza al momento della dichiarazione, garantendo la thread safety senza sincronizzazione.
Esempio con Eager Initialization:
public class Singleton {
private static final Singleton instance = new Singleton();
private Singleton() {
// Costruttore privato
}
public static Singleton getInstance() {
return instance;
}
}A.1.3 Il Pattern Factory
Descrizione:
Il Factory Pattern è un design pattern creazionale che fornisce un’interfaccia per creare oggetti in una superclass, ma permette alle subclass di alterare il tipo di oggetti che verranno creati.
Implementazione di Base:
public interface Shape {
void draw();
}
public class Circle implements Shape {
public void draw() {
System.out.println("Disegna un cerchio");
}
}
public class Rectangle implements Shape {
public void draw() {
System.out.println("Disegna un rettangolo");
}
}
public class ShapeFactory {
public Shape getShape(String shapeType) {
if (shapeType == null) return null;
if (shapeType.equalsIgnoreCase("CERCHIO")) {
return new Circle();
} else if (shapeType.equalsIgnoreCase("RETTANGOLO")) {
return new Rectangle();
}
return null;
}
}Utilizzo:
ShapeFactory shapeFactory = new ShapeFactory();
Shape shape1 = shapeFactory.getShape("CERCHIO");
shape1.draw();Vantaggi:
-
Incapsula la creazione di oggetti.
-
Facilita l’aggiunta di nuovi tipi di oggetti senza modificare il codice esistente.
A.1.4 Il Pattern Builder
Descrizione:
Il Builder Pattern separa la costruzione di un oggetto complesso dalla sua rappresentazione, consentendo la creazione passo-passo di oggetti immutabili.
Implementazione di Base:
public class User {
private final String nome;
private final String cognome;
private final int età;
private User(UserBuilder builder) {
this.nome = builder.nome;
this.cognome = builder.cognome;
this.età = builder.età;
}
public static class UserBuilder {
private String nome;
private String cognome;
private int età;
public UserBuilder setNome(String nome) {
this.nome = nome;
return this;
}
public UserBuilder setCognome(String cognome) {
this.cognome = cognome;
return this;
}
public UserBuilder setEtà(int età) {
this.età = età;
return this;
}
public User build() {
return new User(this);
}
}
}Utilizzo:
User user = new User.UserBuilder()
.setNome("Mario")
.setCognome("Rossi")
.setEtà(30)
.build();Vantaggi:
-
Facilita la creazione di oggetti complessi con molti parametri.
-
Migliora la leggibilità del codice.
-
Crea oggetti immutabili.
A.1.5 Il Pattern Observer
Descrizione:
L’Observer Pattern definisce una dipendenza uno-a-molti tra oggetti, in modo tale che quando un oggetto cambia stato, tutti i suoi dipendenti vengono notificati e aggiornati automaticamente.
Implementazione di Base:
public interface Observer {
void update(String message);
}
public class ConcreteObserver implements Observer {
public void update(String message) {
System.out.println("Messaggio ricevuto: " + message);
}
}
public class Subject {
private List<Observer> observers = new ArrayList<>();
private String stato;
public void attach(Observer observer) {
observers.add(observer);
}
public void setStato(String stato) {
this.stato = stato;
notifyAllObservers();
}
private void notifyAllObservers() {
for (Observer observer : observers) {
observer.update(stato);
}
}
}Utilizzo:
Subject subject = new Subject();
Observer obs1 = new ConcreteObserver();
Observer obs2 = new ConcreteObserver();
subject.attach(obs1);
subject.attach(obs2);
subject.setStato("Nuovo Stato");Vantaggi:
-
Promuove un accoppiamento debole tra soggetto e osservatori.
-
Facilita l’implementazione di sistemi reattivi.
A.2 Reflection e Annotations
A.2.1 Introduzione alla Reflection
La reflection è un meccanismo che permette a un programma Java di ispezionare e manipolare le sue componenti a runtime. Con la reflection, è possibile ottenere informazioni su classi, metodi, campi e costruttori, anche se non si conoscono i loro nomi a compile-time.
Esempio di Utilizzo:
Class<?> clazz = Class.forName("com.example.MyClass");
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {
System.out.println("Metodo: " + method.getName());
}Applicazioni:
-
Framework di testing (es. JUnit)
-
Dependency Injection
-
Serializzazione/Deserializzazione
A.2.2 Utilizzo della Reflection per l’Ispezione e la Modifica
Ottenere Informazioni sui Campi:
Field field = clazz.getDeclaredField("nomeCampo");
field.setAccessible(true);
Object valore = field.get(istanzaOggetto);Invocare Metodi Dinamicamente:
Method metodo = clazz.getDeclaredMethod("nomeMetodo", Parametri.class);
metodo.setAccessible(true);
Object risultato = metodo.invoke(istanzaOggetto, argomenti);Creare Istanze Dinamicamente:
Constructor<?> costruttore = clazz.getConstructor();
Object nuovaIstanze = costruttore.newInstance();Considerazioni di Sicurezza:
-
L’uso della reflection può violare l’incapsulamento.
-
Può avere impatti sulle prestazioni.
-
È soggetto a restrizioni di sicurezza in ambienti sandbox.
A.2.3 Annotations in Java
Le annotations sono meta-dati che forniscono informazioni aggiuntive al compilatore o ai tool di runtime. Possono essere applicate a classi, metodi, campi, parametri e altri elementi del codice.
Esempi di Annotations Predefinite:
-
@Override -
@Deprecated -
@SuppressWarnings
Utilizzo:
public class MyClass {
@Override
public String toString() {
return "Esempio di annotation @Override";
}
}A.2.4 Creazione di Annotations Personalizzate
Definizione:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MyAnnotation {
String valore();
}Utilizzo:
public class MyClass {
@MyAnnotation(valore = "Esempio")
public void metodoAnnotato() {
// ...
}
}Elaborazione a Runtime:
Method metodo = clazz.getMethod("metodoAnnotato");
if (metodo.isAnnotationPresent(MyAnnotation.class)) {
MyAnnotation annotation = metodo.getAnnotation(MyAnnotation.class);
System.out.println("Valore dell'annotation: " + annotation.valore());
}Applicazioni:
-
Configurazione di framework (es. Spring, JPA)
-
Generazione di codice
-
Validazione
A.3 Il Modello di Memoria di Java e Garbage Collection
A.3.1 Comprendere il Modello di Memoria di Java
Il modello di memoria di Java definisce come i thread interagiscono attraverso la memoria e specifica come le modifiche alle variabili effettuate da un thread diventano visibili ad altri thread.
Componenti Principali:
-
Heap: Area di memoria condivisa dove vengono allocati gli oggetti.
-
Stack dei Thread: Ogni thread ha il proprio stack per variabili locali e chiamate ai metodi.
-
Metaspace: Contiene informazioni sulle classi, come metodi e campi.
A.3.2 Meccanismi di Garbage Collection
Il Garbage Collector (GC) automatizza la gestione della memoria liberando lo spazio occupato da oggetti non più raggiungibili.
Algoritmi di Garbage Collection:
-
Serial GC: Utilizza un singolo thread per la garbage collection.
-
Parallel GC: Utilizza più thread per accelerare il processo.
-
CMS (Concurrent Mark Sweep): Minimizza le pause nell’applicazione.
-
G1 (Garbage First): Progettato per gestire grandi heap con pause prevedibili.
Fasi del Garbage Collection:
-
Marking: Identifica gli oggetti raggiungibili.
-
Deletion/Sweeping: Rimuove gli oggetti non raggiungibili.
-
Compaction: Compatta la memoria per ridurre la frammentazione.
A.3.3 Best Practices per la Gestione della Memoria
-
Evitare Memory Leaks: Assicurarsi che le referenze a oggetti non necessari vengano eliminate.
-
Utilizzare Strutture di Dati Appropriate: Scegliere le collezioni giuste per le esigenze dell’applicazione.
-
Profilare l’Applicazione: Usare strumenti come VisualVM o JProfiler per monitorare l’utilizzo della memoria.
-
Evitare la Creazione Inutile di Oggetti: Riutilizzare gli oggetti quando possibile.
Esempio di Memory Leak Comune:
List<String> lista = new ArrayList<>();
public void aggiungiElemento() {
lista.add("Nuovo Elemento");
// Se la lista non viene mai pulita, crescerà indefinitamente
}A.4 Generics Avanzati e Type Erasure
A.4.1 Type Erasure in Java
I generics in Java sono implementati attraverso un meccanismo chiamato type erasure, dove le informazioni sui tipi generici vengono rimosse a compile-time per mantenere la compatibilità con le versioni precedenti di Java.
Implicazioni:
-
Non è possibile usare tipi primitivi come parametri di tipo (es.
List<int>non è valido). -
Non è possibile creare istanze di tipi generici direttamente (es.
new T()non è permesso). -
Le informazioni sul tipo non sono disponibili a runtime.
A.4.2 Wildcards e Tipi Limitati
Wildcards:
-
Unbounded Wildcard (
?): Indica un tipo sconosciuto. -
Upper Bounded Wildcard (
<? extends Tipo>): Accetta Tipo o sottotipi. -
Lower Bounded Wildcard (
<? super Tipo>): Accetta Tipo o supertipi.
Esempio con Upper Bounded Wildcard:
public void stampaLista(List<? extends Number> lista) {
for (Number numero : lista) {
System.out.println(numero);
}
}A.4.3 Generics e Ereditarietà
I generics non supportano la covarianza e la contravarianza come gli array. Ad esempio, List<Number> non è supertipo di List<Integer>.
Esempio Errato:
List<Number> numeri = new ArrayList<Integer>(); // Errore di compilazioneUtilizzo Corretto con Wildcards:
List<? extends Number> numeri = new ArrayList<Integer>();Best Practices:
- PECS Principle (Producer Extends, Consumer Super): Utilizzare
extendsquando il parametro di tipo produce dati,superquando consuma dati.
Con questa appendice, abbiamo esplorato argomenti avanzati che completano la tua conoscenza di Java. Comprendere questi concetti è fondamentale non solo per scrivere codice più efficace ma anche per affrontare con successo colloqui tecnici che richiedono una conoscenza approfondita del linguaggio. Continua a sperimentare e applicare questi principi nei tuoi progetti per consolidare le tue competenze.
Capitolo 11: Introduzione a Spring Framework
11.1 Principi Fondamentali
Il successo e la diffusione di Spring Framework nel mondo Java sono in gran parte dovuti alla sua aderenza a principi di progettazione solidi che promuovono codice modulare, testabile e facilmente manutenibile. Tra questi principi, l’Inversion of Control (IoC) e la Dependency Injection (DI) occupano un ruolo centrale.
Inversion of Control (IoC)
Definizione e Contesto
L’Inversion of Control (IoC) è un principio di progettazione software in cui il flusso di controllo di un programma è invertito rispetto alla programmazione tradizionale. Invece di avere l’applicazione che gestisce direttamente il flusso e le dipendenze, questa responsabilità è delegata a un framework o a un contenitore esterno.
Esempio tradizionale (senza IoC):
public class Motore {
// Implementazione del motore
}
public class Auto {
private Motore motore;
public Auto() {
this.motore = new Motore(); // Creazione diretta dell'oggetto
}
}In questo scenario, la classe Auto è responsabile della creazione dell’istanza di Motore. Ciò porta a un forte accoppiamento tra le due classi, rendendo difficile sostituire Motore con una diversa implementazione senza modificare Auto.
Perché l’IoC è Importante?
-
Decoupling (Disaccoppiamento): L’IoC riduce la dipendenza tra i componenti, facilitando la manutenzione e l’estensibilità del codice.
-
Testabilità: Componenti disaccoppiati possono essere testati isolatamente utilizzando mock o stub.
-
Flessibilità: Permette di cambiare le implementazioni senza modificare il codice che le utilizza.
Applicazione dell’IoC
Con l’IoC, la creazione delle dipendenze è gestita da un contenitore esterno:
public class Auto {
private Motore motore;
public Auto(Motore motore) {
this.motore = motore; // Iniezione della dipendenza
}
}Qui, Auto non crea più direttamente un’istanza di Motore, ma la riceve dall’esterno, permettendo una maggiore flessibilità.
Dependency Injection (DI)
Definizione
La Dependency Injection (DI) è un pattern che realizza l’IoC fornendo le dipendenze necessarie a un oggetto dall’esterno, anziché lasciar che sia l’oggetto stesso a crearle o a cercarle.
Tipi di Iniezione
-
Iniezione tramite Costruttore:
public class Auto { private Motore motore; public Auto(Motore motore) { this.motore = motore; } } -
Iniezione tramite Setter:
public class Auto { private Motore motore; public void setMotore(Motore motore) { this.motore = motore; } } -
Iniezione tramite Campo (Field Injection):
public class Auto { @Autowired private Motore motore; }
Vantaggi della DI
-
Modularità: Permette di sostituire facilmente le implementazioni delle dipendenze.
-
Testabilità: Facilita l’utilizzo di mock per i test unitari.
-
Manutenibilità: Riduce la necessità di modifiche estensive quando si cambiano le dipendenze.
Implementazione di IoC e DI con Spring
Spring Framework fornisce un contenitore IoC che gestisce la creazione e l’iniezione dei bean (componenti) dell’applicazione.
Configurazione tramite Annotazioni
Definizione dei Bean:
@Component
public class MotoreDiesel implements Motore {
// Implementazione specifica
}
@Component
public class Auto {
private final Motore motore;
@Autowired
public Auto(Motore motore) {
this.motore = motore;
}
}-
@Componentindica a Spring che queste classi devono essere gestite come bean. -
@Autowiredindica che la dipendenza deve essere iniettata dal contenitore.
Configurazione tramite XML
beans.xml:
<beans xmlns="http://www.springframework.org/schema/beans" ...>
<bean id="motoreDiesel" class="com.example.MotoreDiesel"/>
<bean id="auto" class="com.example.Auto">
<constructor-arg ref="motoreDiesel"/>
</bean>
</beans>Esecuzione dell’Applicazione
public class Applicazione {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext("com.example");
Auto auto = context.getBean(Auto.class);
auto.avvia();
}
}Best Practices
-
Favorire l’Iniezione tramite Costruttore: Rende le dipendenze obbligatorie esplicite.
-
Utilizzare le Interfacce: Programmare verso le interfacce anziché le implementazioni concrete.
-
Evitare l’Iniezione tramite Campo se possibile: Anche se più comoda, rende il codice meno testabile.
-
Gestione Consistente delle Dipendenze: Mantenere uno stile coerente di iniezione all’interno dell’applicazione.
Esempio Pratico: Un Servizio di Notifiche
Definizione dell’Interfaccia:
public interface ServizioNotifica {
void inviaMessaggio(String destinatario, String messaggio);
}Implementazione del Servizio:
@Service
public class ServizioEmail implements ServizioNotifica {
@Override
public void inviaMessaggio(String destinatario, String messaggio) {
// Logica per inviare un'email
}
}Utilizzo del Servizio:
@Component
public class GestoreOrdini {
private final ServizioNotifica servizioNotifica;
@Autowired
public GestoreOrdini(ServizioNotifica servizioNotifica) {
this.servizioNotifica = servizioNotifica;
}
public void processaOrdine(Ordine ordine) {
// Logica di elaborazione dell'ordine
servizioNotifica.inviaMessaggio(ordine.getEmailCliente(), "Il tuo ordine è stato elaborato.");
}
}In questo esempio:
-
GestoreOrdinidipende daServizioNotifica, non da una specifica implementazione. -
ServizioEmailè un’implementazione concreta diServizioNotifica. -
La DI permette di sostituire
ServizioEmailcon un’altra implementazione senza modificareGestoreOrdini.
Vantaggi dell’Approccio Spring
-
Riduzione del Codice Boilerplate: Spring gestisce automaticamente la creazione e l’iniezione dei bean.
-
Facilità di Test: Le dipendenze possono essere facilmente mockate nei test unitari.
-
Modularità dell’Applicazione: I componenti possono essere sviluppati e mantenuti indipendentemente.
Considerazioni Finali
Comprendere l’IoC e la DI è fondamentale per sfruttare appieno le potenzialità di Spring Framework. Questi principi non solo migliorano la qualità e la manutenibilità del codice, ma sono anche spesso argomenti chiave nei colloqui tecnici per posizioni di sviluppatore Java/Spring.
Punti Chiave da Ricordare:
-
Inversion of Control (IoC): Il framework gestisce il flusso di controllo dell’applicazione.
-
Dependency Injection (DI): Le dipendenze vengono fornite agli oggetti anziché essere create internamente.
-
Spring IoC Container: È il componente di Spring che implementa IoC e DI, gestendo i bean dell’applicazione.
-
Configurazione Flessibile: Spring supporta diverse modalità di configurazione (annotazioni, XML, Java Config).
Prossimi Passi:
-
Esplorare le diverse modalità di configurazione offerte da Spring.
-
Approfondire come Spring gestisce il ciclo di vita dei bean.
-
Comprendere come la DI facilita l’integrazione di diversi componenti in un’applicazione enterprise.
11.2 Configurazione di Spring
La configurazione è un aspetto fondamentale nel framework Spring, poiché definisce come i componenti (bean) dell’applicazione vengono creati, configurati e gestiti. Spring offre diverse modalità per configurare un’applicazione:
-
Configurazione tramite XML
-
Configurazione basata su annotazioni
-
Configurazione con Java Config (classi Java)
Esploreremo ciascuna di queste modalità, comprendendone i vantaggi, gli svantaggi e gli scenari d’uso ideali.
11.2.1 Configurazione tramite XML
La configurazione XML è il metodo tradizionale utilizzato nelle prime versioni di Spring. Consiste nel definire i bean e le loro dipendenze all’interno di file XML esterni al codice sorgente.
Esempio:
<!-- file applicationContext.xml -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- Definizione di un bean -->
<bean id="servizioCliente" class="com.example.ServizioCliente">
<property name="repositoryCliente" ref="repositoryCliente"/>
</bean>
<bean id="repositoryCliente" class="com.example.RepositoryCliente"/>
</beans>In questo esempio, stiamo definendo due bean:
-
servizioCliente: un’istanza della classe
ServizioCliente, con una dipendenza darepositoryCliente. -
repositoryCliente: un’istanza della classe
RepositoryCliente.
Vantaggi:
-
Separazione tra configurazione e codice: La configurazione è esterna al codice sorgente, facilitando la gestione delle modifiche senza alterare il codice.
-
Flessibilità: È possibile modificare le dipendenze e le configurazioni senza ricompilare l’applicazione.
Svantaggi:
-
Verboso: La configurazione XML può diventare prolissa e difficile da mantenere in applicazioni complesse.
-
Meno intuitivo: Meno leggibile rispetto alla configurazione basata su codice, specialmente per sviluppatori abituati a lavorare direttamente con il codice Java.
11.2.2 Configurazione Basata su Annotazioni
La configurazione basata su annotazioni sfrutta le annotazioni del linguaggio Java per definire i bean e le loro dipendenze direttamente nel codice sorgente.
Esempio:
// Classe ServizioCliente.java
package com.example;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ServizioCliente {
private final RepositoryCliente repositoryCliente;
@Autowired
public ServizioCliente(RepositoryCliente repositoryCliente) {
this.repositoryCliente = repositoryCliente;
}
// Metodi del servizio
}
// Classe RepositoryCliente.java
package com.example;
import org.springframework.stereotype.Repository;
@Repository
public class RepositoryCliente {
// Metodi del repository
}In questo esempio:
-
@Service: Indica che la classe
ServizioClienteè un bean di tipo servizio. -
@Repository: Indica che la classe
RepositoryClienteè un bean di tipo repository. -
@Autowired: Inietta automaticamente la dipendenza
RepositoryClienteinServizioCliente.
Vantaggi:
-
Maggiore leggibilità: La configurazione è vicina al codice che viene configurato, rendendo più semplice comprendere le dipendenze.
-
Riduzione del codice: Meno configurazione esterna, riducendo il rischio di errori dovuti a disallineamenti tra codice e configurazione.
Svantaggi:
-
Coupling con il framework: Le classi dell’applicazione diventano dipendenti da Spring attraverso le annotazioni.
-
Flessibilità limitata: Modificare le dipendenze richiede modifiche al codice sorgente.
11.2.3 Configurazione con Java Config
Java Config utilizza classi Java annotate con @Configuration per definire i bean e le loro dipendenze, combinando la flessibilità della configurazione esterna con la potenza e la sicurezza tipica del linguaggio Java.
Esempio:
// Classe di configurazione AppConfig.java
package com.example.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AppConfig {
@Bean
public ServizioCliente servizioCliente() {
return new ServizioCliente(repositoryCliente());
}
@Bean
public RepositoryCliente repositoryCliente() {
return new RepositoryCliente();
}
}-
@Configuration: Indica che la classe contiene definizioni di bean.
-
@Bean: Indica che il metodo restituisce un bean gestito da Spring.
Esempio di utilizzo:
// Classe principale Applicazione.java
package com.example;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import com.example.config.AppConfig;
public class Applicazione {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
ServizioCliente servizio = context.getBean(ServizioCliente.class);
// Utilizzo del servizio
}
}Vantaggi:
-
Tipizzazione forte: Il codice di configurazione è controllato dal compilatore, riducendo gli errori.
-
Maggiore controllo: Possibilità di utilizzare la logica di programmazione per configurare i bean.
-
Facilità di test: Le classi di configurazione possono essere testate come qualsiasi altro codice Java.
Svantaggi:
-
Coupling con il framework: Simile alla configurazione con annotazioni, introduce dipendenze da Spring.
-
Verboso per semplici configurazioni: Per configurazioni molto semplici, potrebbe essere eccessivo.
11.2.4 Confronto tra le Modalità di Configurazione
11.2.5 Scelta della Modalità di Configurazione
La scelta del metodo di configurazione dipende da vari fattori:
-
Dimensione e complessità del progetto: Progetti più grandi potrebbero beneficiare della chiarezza dell’XML o della modularità di Java Config.
-
Preferenze del team: Alcuni sviluppatori preferiscono avere la configurazione separata dal codice, altri preferiscono le annotazioni per la loro immediatezza.
-
Requisiti di flessibilità: Se si prevede di modificare frequentemente la configurazione senza toccare il codice, l’XML potrebbe essere più adatto.
11.2.6 Best Practices nella Configurazione di Spring
-
Coerenza: Mantenere uno stile di configurazione coerente in tutto il progetto per facilitare la manutenzione.
-
Modularità: Suddividere la configurazione in più file o classi per gestire meglio la complessità.
-
Utilizzo di profili: Sfruttare i profili di Spring (
@Profile) per gestire configurazioni diverse per ambienti diversi (sviluppo, test, produzione). -
Evitare l’overconfiguration: Configurare solo ciò che è necessario, evitando definizioni ridondanti o inutili.
11.2.7 Esempio di Utilizzo dei Profili con Java Config
Definizione di profili:
// Classe di configurazione AppConfig.java
package com.example.config;
import org.springframework.context.annotation.*;
@Configuration
public class AppConfig {
@Bean
@Profile("sviluppo")
public DataSource dataSourceSviluppo() {
// Configurazione per l'ambiente di sviluppo
}
@Bean
@Profile("produzione")
public DataSource dataSourceProduzione() {
// Configurazione per l'ambiente di produzione
}
}Attivazione di un profilo specifico:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
context.getEnvironment().setActiveProfiles("sviluppo");
context.register(AppConfig.class);
context.refresh();11.2.8 Considerazioni Finali
Comprendere le diverse modalità di configurazione di Spring è essenziale per sfruttare al meglio il framework. Ogni metodo ha i suoi punti di forza e le sue debolezze, e spesso la scelta migliore è un approccio ibrido che combina più metodi per soddisfare le esigenze specifiche del progetto.
La configurazione basata su annotazioni e Java Config rappresentano lo stato dell’arte nello sviluppo con Spring, offrendo un equilibrio tra leggibilità, tipizzazione e controllo. Tuttavia, la configurazione XML rimane utile in alcuni scenari, specialmente quando si lavora con applicazioni legacy o quando si desidera mantenere la configurazione completamente separata dal codice.
11.3 Il Contesto dell’Applicazione
In questa sezione esploreremo il cuore pulsante di Spring Framework: il Contesto dell’Applicazione (Application Context). Comprendere come Spring gestisce i bean e il ciclo di vita delle applicazioni è fondamentale per sfruttare appieno le potenzialità del framework e per sviluppare applicazioni modulari, scalabili e facili da manutenere.
Cos’è il Contesto dell’Applicazione?
Il Contesto dell’Applicazione è un contenitore centrale in Spring che gestisce la creazione, l’inizializzazione, la configurazione e la gestione del ciclo di vita dei bean (i componenti della tua applicazione). Estende le funzionalità del BeanFactory, offrendo servizi avanzati come:
-
Integrazione con l’ambiente di esecuzione: Accesso a risorse, variabili di ambiente e proprietà del sistema.
-
Internazionalizzazione: Supporto per messaggi multilingue e localizzazione.
-
Pubblicazione di eventi: Meccanismi per comunicazione e coordinamento tra i bean.
-
Supporto per AOP (Aspect-Oriented Programming): Permette l’applicazione di aspetti come logging e sicurezza.
In pratica, il Contesto dell’Applicazione funge da “colla” che tiene insieme tutti i componenti dell’applicazione, gestendone le interazioni in modo efficiente e flessibile.
Come Spring Gestisce i Bean
Definizione e Registrazione dei Bean
I bean sono gli oggetti che compongono l’applicazione e che vengono gestiti dal Contesto dell’Applicazione. Possono essere definiti e registrati in diversi modi:
-
Configurazione XML: Metodo tradizionale, in cui i bean sono definiti in file XML.
-
Annotazioni: Utilizzando annotazioni come
@Component,@Service,@Repositorye@Controllerdirettamente sulle classi. -
Configurazione Java: Attraverso classi annotate con
@Configuratione metodi annotati con@Bean.
Esempio di definizione tramite annotazioni:
@Component
public class EmailService {
public void sendEmail(String to, String subject, String body) {
// Logica per inviare un'email
}
}Iniezione delle Dipendenze
Spring gestisce le dipendenze tra i bean tramite Dependency Injection (DI), permettendo di costruire applicazioni loosely coupled (a basso accoppiamento). Le dipendenze possono essere iniettate:
-
Per costruttore: Preferibile per l’immutabilità e la testabilità.
-
Per metodo setter: Utile quando le dipendenze sono opzionali.
-
Per campo: Meno consigliato per via della riflessione e della difficoltà di test.
Esempio di iniezione per costruttore:
@Service
public class OrderService {
private final EmailService emailService;
@Autowired
public OrderService(EmailService emailService) {
this.emailService = emailService;
}
public void placeOrder(Order order) {
// Logica per processare l'ordine
emailService.sendEmail(order.getCustomerEmail(), "Conferma Ordine", "Grazie per il tuo ordine!");
}
}Il Ciclo di Vita dei Bean
Il ciclo di vita di un bean gestito dal Contesto dell’Applicazione comprende diverse fasi:
-
Istanziazione: Creazione dell’oggetto bean.
-
Popolamento delle proprietà: Iniezione delle dipendenze.
-
Chiamata dei metodi di callback di inizializzazione:
-
Interfaccia
InitializingBean(afterPropertiesSet()). -
Metodo personalizzato definito tramite
@PostConstruct.
-
-
Utilizzo del bean: Il bean è pronto per essere utilizzato nell’applicazione.
-
Chiamata dei metodi di callback di distruzione:
-
Interfaccia
DisposableBean(destroy()). -
Metodo personalizzato definito tramite
@PreDestroy.
-
-
Garbage Collection: Rimozione dell’oggetto dalla memoria.
Esempio con metodi di callback:
@Component
public class CacheManager {
public void loadCache() {
// Carica dati nella cache
}
public void clearCache() {
// Pulisce la cache
}
@PostConstruct
public void init() {
loadCache();
}
@PreDestroy
public void shutdown() {
clearCache();
}
}Tipi di Contesto dell’Applicazione
Esistono diverse implementazioni del Contesto dell’Applicazione, ognuna adatta a specifici scenari:
-
ClassPathXmlApplicationContext: Carica i bean definiti in file XML presenti nel classpath. -
FileSystemXmlApplicationContext: Carica i bean da file XML nel filesystem. -
AnnotationConfigApplicationContext: Utilizza configurazioni basate su annotazioni e classi Java. -
AnnotationConfigWebApplicationContext: Specifico per applicazioni web, integrato con il ciclo di vita del servlet container.
Esempio di creazione di un contesto con configurazione Java:
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);Accesso al Contesto dell’Applicazione
Il Contesto dell’Applicazione può essere accessibile all’interno dei bean, se necessario. Tuttavia, è importante usarlo con parsimonia per evitare un forte accoppiamento.
Esempio con ApplicationContextAware:
@Component
public class MyBean implements ApplicationContextAware {
private ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.context = applicationContext;
}
public void doSomething() {
// Utilizza il contesto per ottenere altri bean
AnotherBean anotherBean = context.getBean(AnotherBean.class);
// ...
}
}Pubblicazione e Ascolto di Eventi
Il Contesto dell’Applicazione supporta un sistema di eventi che permette ai bean di comunicare in modo disaccoppiato.
Esempio di pubblicazione di un evento personalizzato:
public class OrderCreatedEvent extends ApplicationEvent {
private final Order order;
public OrderCreatedEvent(Object source, Order order) {
super(source);
this.order = order;
}
public Order getOrder() {
return order;
}
}Bean che pubblica l’evento:
@Component
public class OrderService {
private final ApplicationEventPublisher eventPublisher;
@Autowired
public OrderService(ApplicationEventPublisher eventPublisher) {
this.eventPublisher = eventPublisher;
}
public void createOrder(Order order) {
// Logica per creare l'ordine
eventPublisher.publishEvent(new OrderCreatedEvent(this, order));
}
}Bean che ascolta l’evento:
@Component
public class InventoryService {
@EventListener
public void onOrderCreated(OrderCreatedEvent event) {
Order order = event.getOrder();
// Aggiorna l'inventario in base all'ordine
}
}Gestione delle Risorse
Il Contesto dell’Applicazione fornisce meccanismi per accedere a risorse come file, URL o stream.
Esempio di accesso a una risorsa:
@Component
public class ResourceLoaderBean implements ResourceLoaderAware {
private ResourceLoader resourceLoader;
@Override
public void setResourceLoader(ResourceLoader resourceLoader) {
this.resourceLoader = resourceLoader;
}
public void loadResource(String resourcePath) throws IOException {
Resource resource = resourceLoader.getResource(resourcePath);
InputStream is = resource.getInputStream();
// Processa il contenuto della risorsa
}
}Internazionalizzazione (i18n)
Per supportare applicazioni multilingue, il Contesto dell’Applicazione offre il servizio MessageSource per gestire messaggi e risorse internazionalizzate.
Esempio di utilizzo di MessageSource:
@Component
public class MessageService {
private final MessageSource messageSource;
@Autowired
public MessageService(MessageSource messageSource) {
this.messageSource = messageSource;
}
public String getMessage(String code, Object[] args, Locale locale) {
return messageSource.getMessage(code, args, locale);
}
}Vantaggi dell’Utilizzo del Contesto dell’Applicazione
-
Modularità: Favorisce la separazione dei compiti e l’organizzazione del codice.
-
Testabilità: Facilita il testing grazie all’iniezione delle dipendenze e alla possibilità di sostituire facilmente i componenti.
-
Configurabilità: Permette di modificare il comportamento dell’applicazione senza cambiare il codice sorgente.
-
Scalabilità: Supporta la crescita dell’applicazione, gestendo efficacemente un numero crescente di componenti.
Considerazioni Finali
Il Contesto dell’Applicazione è un elemento chiave in Spring che offre un ambiente ricco e flessibile per la gestione dei componenti dell’applicazione. Comprendere il suo funzionamento è essenziale per:
-
Ottimizzare le prestazioni: Evitare problemi di memoria e garantire una gestione efficiente dei componenti.
-
Migliorare la manutenzione: Rendere il codice più leggibile e gestibile.
-
Potenziare lo sviluppo: Sfruttare appieno le funzionalità offerte da Spring per creare applicazioni robuste e professionali.
Invitiamo il lettore a sperimentare con i vari tipi di Contesto dell’Applicazione e a esplorare le numerose funzionalità che esso offre, in modo da acquisire una padronanza che sarà di grande valore sia nello sviluppo quotidiano che nella preparazione per colloqui tecnici avanzati.
Capitolo 12: Spring Boot - Fondamenti
12.1 Cos’è Spring Boot
Obiettivi e vantaggi; convenzione su configurazione
Introduzione a Spring Boot
Spring Boot è un framework open-source basato su Java, progettato per semplificare lo sviluppo di applicazioni stand-alone, pronte per la produzione. Sviluppato dal team di Pivotal (ora parte di VMware), Spring Boot estende il framework Spring tradizionale, fornendo una serie di strumenti e funzionalità che riducono drasticamente la quantità di configurazione manuale necessaria.
Spring Boot adotta una filosofia di “convenzione sulla configurazione” (convention over configuration), che permette agli sviluppatori di iniziare rapidamente senza dover impostare dettagli complessi. Questo approccio facilita la creazione di applicazioni robuste e scalabili, riducendo il tempo e gli sforzi richiesti per la configurazione iniziale.
Obiettivi di Spring Boot
Gli obiettivi principali di Spring Boot possono essere riassunti come segue:
-
Semplificazione della Configurazione: Eliminare la necessità di configurazioni XML o Java estese, grazie all’autoconfigurazione basata sulle dipendenze presenti nel classpath.
-
Avvio Rapido delle Applicazioni: Fornire un ambiente in cui gli sviluppatori possano iniziare a scrivere codice di business immediatamente, senza preoccuparsi dell’infrastruttura sottostante.
-
Creazione di Applicazioni Stand-alone: Consentire la creazione di applicazioni che possono essere eseguite autonomamente, senza la necessità di server applicativi esterni come Tomcat o JBoss.
-
Fornitura di Strumenti Integrati: Offrire funzionalità integrate per il monitoraggio, la gestione e il testing delle applicazioni, semplificando le operazioni di manutenzione e sviluppo.
Vantaggi di Spring Boot
-
Autoconfigurazione Intelligente: Spring Boot è in grado di configurare automaticamente molte delle librerie comuni basandosi sulle dipendenze presenti. Ad esempio, se si include
spring-boot-starter-web, il framework configurerà automaticamente un server web integrato. -
Starter POMs: Utilizzando gli “starter” POMs, è possibile includere rapidamente un insieme di dipendenze correlato a una funzionalità specifica, riducendo la complessità nella gestione delle dipendenze di Maven o Gradle.
-
Minimizzazione del Codice Boilerplate: Riduce la necessità di codice ripetitivo, permettendo agli sviluppatori di concentrarsi sulla logica dell’applicazione piuttosto che sulla configurazione.
-
Testing Facilitato: Offre supporto integrato per il testing unitario e di integrazione, semplificando la scrittura di test efficaci.
-
Deployment Semplificato: Le applicazioni Spring Boot possono essere facilmente containerizzate e distribuite su piattaforme cloud, grazie al loro design stand-alone.
Convenzione su Configurazione
La filosofia della “convenzione su configurazione” è un principio chiave di Spring Boot. Questo approccio presuppone che l’applicazione seguirà determinate convenzioni predefinite, riducendo così la necessità di configurazioni esplicite.
Esempio di Convenzione:
-
Struttura dei Pacchetti: Se si posiziona la classe principale dell’applicazione in un pacchetto base, Spring Boot scansionerà automaticamente quel pacchetto e i suoi sottopacchetti per componenti annotati come
@Component,@Service,@Repository, ecc. -
File di Configurazione: Un file denominato
application.propertiesoapplication.ymlnella cartellasrc/main/resourcessarà automaticamente rilevato e utilizzato per configurare l’applicazione.
Vantaggi della Convenzione su Configurazione:
-
Velocità di Sviluppo: Riducendo la necessità di configurazioni dettagliate, gli sviluppatori possono iniziare a lavorare più rapidamente.
-
Riduzione degli Errori: Meno configurazioni manuali significano meno possibilità di errori di configurazione che possono causare comportamenti inattesi.
-
Coerenza: Le applicazioni tendono ad essere più uniformi, facilitando la comprensione del codice e la collaborazione tra team.
Autoconfigurazione in Dettaglio
L’autoconfigurazione di Spring Boot funziona analizzando le dipendenze presenti nel classpath e attivando automaticamente le configurazioni appropriate.
Come Funziona:
-
Condizioni: Le classi di configurazione sono annotate con
@Conditionalper assicurarsi che vengano caricate solo se determinate condizioni sono soddisfatte (ad esempio, la presenza di una certa classe nel classpath). -
Proprietà di Configurazione: Le impostazioni possono essere personalizzate tramite proprietà nel file
application.properties, permettendo di sovrascrivere i valori di default dell’autoconfigurazione.
Esempio Pratico:
Se si include spring-boot-starter-jdbc come dipendenza, Spring Boot:
-
Configurerà automaticamente un
DataSourceper la connessione al database. -
Se trova
HikariCPnel classpath, lo utilizzerà come connection pool predefinito. -
Permetterà di configurare le proprietà del database tramite il file
application.properties:
spring.datasource.url=jdbc:mysql://localhost:3306/dbname
spring.datasource.username=root
spring.datasource.password=password
Personalizzazione e Flessibilità
Nonostante l’approccio basato su convenzioni, Spring Boot offre un elevato grado di flessibilità. Se le convenzioni non si adattano alle esigenze specifiche dell’applicazione, è possibile:
-
Disabilitare l’Autoconfigurazione: Utilizzando l’annotazione
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}), si possono escludere specifiche autoconfigurazioni. -
Definire Configurazioni Personalizzate: Creando classi di configurazione annotate con
@Configuration, è possibile definire bean e impostazioni specifiche.
Conclusione
Spring Boot rappresenta una soluzione potente per accelerare lo sviluppo di applicazioni Java moderne. Grazie alla sua filosofia di “convenzione su configurazione” e all’autoconfigurazione intelligente, permette di ridurre significativamente il tempo necessario per iniziare un nuovo progetto, mantenendo al contempo la flessibilità necessaria per soddisfare requisiti complessi.
Nel prossimo capitolo, esploreremo come creare una semplice applicazione Spring Boot, mettendo in pratica i concetti di autoconfigurazione e utilizzando gli starter POM per gestire le dipendenze.
12.2 Creazione di un’Applicazione Spring Boot
In questa sezione, impareremo come creare un’applicazione Spring Boot partendo da zero, esplorando la struttura di base e comprendendo come spring-boot-starter semplifichi il processo di sviluppo. Questo ci permetterà di gettare le fondamenta per applicazioni più complesse e robuste.
12.2.1 Struttura di Base di un’Applicazione Spring Boot
Una tipica applicazione Spring Boot si compone di:
-
Classe Principale: contiene il metodo
mainche avvia l’applicazione. -
File di Configurazione:
application.propertiesoapplication.ymlper configurazioni personalizzate. -
Dipendenze: gestite tramite Maven (
pom.xml) o Gradle (build.gradle). -
Package di Base: dove risiedono le classi e i componenti dell’applicazione.
Esempio di Struttura di Progetto:
my-spring-boot-app/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com.example.myspringbootapp/
│ │ │ └── MySpringBootAppApplication.java
│ │ └── resources/
│ │ └── application.properties
├── pom.xml
Questa struttura facilita la convenzione sulla configurazione, principio fondamentale di Spring Boot, che riduce al minimo le configurazioni necessarie per avviare un’applicazione.
12.2.2 Utilizzo di spring-boot-starter
Gli starter di Spring Boot sono un insieme di dipendenze preconfigurate che accelerano lo sviluppo integrando automaticamente le librerie necessarie per specifiche funzionalità.
Cos’è uno Starter?
Uno starter è un modulo di convenienza che raggruppa insieme un set di librerie per un determinato ambito funzionale. Ad esempio, spring-boot-starter-web include tutto il necessario per sviluppare applicazioni web, inclusi Spring MVC, Tomcat e Jackson.
Vantaggi degli Starter:
-
Semplificazione delle Dipendenze: Non è necessario dichiarare ogni singola libreria nel file di build.
-
Compatibilità Garantita: Le versioni delle librerie sono allineate e testate per funzionare insieme.
-
Configurazione Minima: Molte configurazioni sono gestite automaticamente grazie all’autoconfigurazione.
12.2.3 Creazione Passo-Passo di un’Applicazione Spring Boot
Vediamo ora come creare un’applicazione Spring Boot utilizzando Maven.
1. Creazione del Progetto con Spring Initializr
Spring Initializr è un tool web che genera un progetto Spring Boot base.
-
Accedi a start.spring.io.
-
Configura il progetto:
-
Project: Maven Project
-
Language: Java
-
Spring Boot: Seleziona la versione desiderata (es. 3.0.0)
-
Project Metadata:
-
Group:
com.example -
Artifact:
demo -
Name:
demo -
Package Name:
com.example.demo
-
-
-
Aggiungi le dipendenze necessarie:
- Spring Web (
spring-boot-starter-web)
- Spring Web (
-
Clicca su “Generate” per scaricare il progetto.
2. Esaminare il pom.xml
Il file pom.xml contiene le dipendenze e le configurazioni di build.
<dependencies>
<!-- Dipendenza per applicazioni web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Dipendenze per i test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>3. Creare la Classe Principale
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}Spiegazione:
-
@SpringBootApplication: è un’annotazione che combina@Configuration,@EnableAutoConfiguratione@ComponentScan. Indica a Spring Boot che questa è la classe principale e abilita l’autoconfigurazione. -
SpringApplication.run(...): avvia il contesto di Spring e l’applicazione integrata (come Tomcat per le applicazioni web).
4. Creare un Controller Semplice
Per testare l’applicazione, aggiungiamo un controller che risponde a una richiesta HTTP.
package com.example.demo.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello() {
return "Ciao, Spring Boot!";
}
}Spiegazione:
-
@RestController: combina@Controllere@ResponseBody, indicando che il controller restituisce dati direttamente nel corpo della risposta. -
@GetMapping("/hello"): mappa le richieste GET all’endpoint/hello.
5. Avviare l’Applicazione
Esegui il comando:
mvn spring-boot:runOppure, esegui la classe DemoApplication dal tuo IDE.
6. Testare l’Applicazione
Apri un browser o utilizza curl per accedere a:
http://localhost:8080/hello
Dovresti vedere la risposta:
Ciao, Spring Boot!
12.2.4 Comprendere l’Autoconfigurazione
Uno dei punti di forza di Spring Boot è l’autoconfigurazione, che riduce drasticamente la necessità di configurazioni manuali.
Come Funziona l’Autoconfigurazione:
-
Analisi del Classpath: Spring Boot verifica quali librerie sono presenti nel classpath.
-
Configurazione Condizionale: In base alle librerie trovate, abilita automaticamente determinate configurazioni tramite annotazioni come
@ConditionalOnClass. -
Proprietà di Configurazione: Le impostazioni predefinite possono essere sovrascritte utilizzando
application.propertiesoapplication.yml.
Esempio:
L’inclusione di spring-boot-starter-web aggiunge automaticamente un server Tomcat integrato e configura Spring MVC.
12.2.5 Personalizzazione delle Configurazioni
Sebbene l’autoconfigurazione sia potente, è spesso necessario personalizzare il comportamento dell’applicazione.
Utilizzo di application.properties:
Puoi sovrascrivere le proprietà predefinite aggiungendo chiavi nel file di configurazione.
Esempio: Cambiare la Porta del Server
Nel file src/main/resources/application.properties, aggiungi:
server.port=9090
L’applicazione ora ascolterà sulla porta 9090 invece della 8080 predefinita.
12.2.6 Comprendere spring-boot-starter
Gli starter sono pacchetti che includono un insieme coerente di dipendenze. Il prefisso spring-boot-starter indica che il pacchetto è gestito da Spring Boot.
Starter Comuni:
-
spring-boot-starter-web: per applicazioni web e RESTful. -
spring-boot-starter-data-jpa: per l’accesso ai dati con JPA. -
spring-boot-starter-security: per aggiungere sicurezza all’applicazione.
Vantaggi:
-
Riduzione del Tempo di Configurazione: Non devi preoccuparti di quali versioni di librerie sono compatibili.
-
Best Practices Incorporate: Gli starter sono configurati secondo le migliori pratiche raccomandate da Spring.
12.2.7 Approfondimento: Cosa Accade Dietro le Quinte
Quando avvii un’applicazione Spring Boot:
-
Bootstrap dell’Applicazione:
SpringApplication.run()avvia il processo. -
Creazione del Contesto: Viene creato il
ApplicationContextche gestisce i bean. -
Autoconfigurazione: Spring Boot esegue le classi di autoconfigurazione in base al classpath e alle proprietà.
-
Scansione dei Componenti: Vengono individuati e istanziati i componenti annotati (es.
@Component,@Service,@Repository). -
Avvio del Server Web: Se è presente
spring-boot-starter-web, viene avviato il server integrato (Tomcat, Jetty, ecc.).
Perché è Importante Capire Questo Processo?
-
Ottimizzazione: Sapendo cosa accade, puoi ottimizzare l’avvio dell’applicazione.
-
Debug: In caso di problemi, comprendere il flusso ti aiuta a individuare rapidamente la causa.
-
Personalizzazione: Puoi intervenire in punti specifici per modificare il comportamento predefinito.
12.2.8 Best Practices
-
Pacchettizzazione Corretta: Organizza il codice in pacchetti logici per facilitare la manutenzione.
-
Configurazioni Esternabili: Evita di hardcodare valori; utilizza file di configurazione o variabili d’ambiente.
-
Logging Adeguato: Configura correttamente il logging per monitorare il comportamento dell’applicazione.
-
Gestione delle Dipendenze: Includi solo le dipendenze necessarie per mantenere leggero il pacchetto.
Conclusione
Creare un’applicazione Spring Boot è un processo semplice grazie agli starter e all’autoconfigurazione. Comprendere la struttura di base e il funzionamento degli strumenti offerti da Spring Boot ti permette di sviluppare rapidamente applicazioni potenti e scalabili, concentrandoti sulla logica di business piuttosto che sulle configurazioni di base.
12.3 Autoconfigurazione e Starter
Introduzione all’Autoconfigurazione
L’autoconfigurazione è uno dei pilastri fondamentali di Spring Boot, progettata per semplificare lo sviluppo di applicazioni Java riducendo la necessità di configurazioni manuali. Questo meccanismo permette a Spring Boot di configurare automaticamente le componenti dell’applicazione in base alle dipendenze presenti nel classpath e alle proprietà definite nei file di configurazione (application.properties o application.yml).
Come Funziona l’Autoconfigurazione
-
Scansione delle Dipendenze:
Spring Boot analizza le dipendenze dichiarate nel progetto (ad esempio, tramite Maven o Gradle) per determinare quali componenti devono essere configurati automaticamente. Ad esempio, se nel
pom.xmlè presente la dipendenzaspring-boot-starter-data-jpa, Spring Boot rileva che è necessario configurare un ambiente JPA. -
Applicazione delle Configurazioni Predefinite:
Basandosi sulle dipendenze rilevate, Spring Boot applica configurazioni predefinite che coprono la maggior parte dei casi d’uso comuni. Questo elimina la necessità di scrivere manualmente configurazioni boilerplate.
-
Personalizzazione Tramite Proprietà:
Anche se l’autoconfigurazione fornisce delle impostazioni predefinite, è possibile sovrascriverle facilmente tramite proprietà personalizzate nei file di configurazione. Questo permette di adattare le configurazioni automatiche alle esigenze specifiche dell’applicazione.
-
Conditional Configuration:
L’autoconfigurazione utilizza le annotazioni
@Conditionalper applicare certe configurazioni solo se determinate condizioni sono soddisfatte. Ad esempio, una configurazione può essere applicata solo se una determinata classe è presente nel classpath.
Vantaggi dell’Autoconfigurazione
-
Riduzione del Boilerplate:
Minimizza la quantità di codice e configurazioni necessarie per avviare un’applicazione, permettendo agli sviluppatori di concentrarsi sulla logica di business.
-
Consistenza e Best Practices:
Promuove configurazioni standardizzate e best practices, garantendo che l’applicazione sia configurata in modo ottimale.
-
Rapidità nello Sviluppo:
Accelera il processo di sviluppo, consentendo di avviare rapidamente nuove applicazioni con configurazioni funzionali di default.
Personalizzazione dell’Autoconfigurazione
Nonostante l’autoconfigurazione offra impostazioni predefinite utili, spesso è necessario personalizzare tali configurazioni per soddisfare requisiti specifici. Spring Boot fornisce diverse modalità per personalizzare l’autoconfigurazione:
1. Utilizzo delle Proprietà di Configurazione
La personalizzazione più semplice avviene tramite la definizione di proprietà nei file application.properties o application.yml. Ad esempio, per configurare il database, si possono specificare proprietà come:
spring.datasource.url=jdbc:mysql://localhost:3306/miodb
spring.datasource.username=utente
spring.datasource.password=passw0rd
spring.jpa.hibernate.ddl-auto=update
Queste proprietà sovrascrivono le impostazioni predefinite dell’autoconfigurazione, permettendo una configurazione precisa del datasource e di Hibernate.
2. Esclusione dell’Autoconfigurazione
In alcuni casi, potrebbe essere necessario disabilitare completamente una specifica configurazione automatica. Questo può essere fatto utilizzando l’annotazione @SpringBootApplication con l’attributo exclude, come mostrato di seguito:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class MiaApplicazione {
public static void main(String[] args) {
SpringApplication.run(MiaApplicazione.class, args);
}
}Questo approccio è utile quando si desidera fornire una configurazione personalizzata che non deve essere influenzata dall’autoconfigurazione predefinita.
3. Creazione di Configurazioni Personalizzate
È possibile definire classi di configurazione personalizzate utilizzando l’annotazione @Configuration. Queste classi possono dichiarare bean specifici che sovrascrivono quelli generati automaticamente:
@Configuration
public class CustomDataSourceConfig {
@Bean
public DataSource dataSource() {
// Configurazione personalizzata del datasource
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl("jdbc:mysql://localhost:3306/miodb_custom");
dataSource.setUsername("customUser");
dataSource.setPassword("customPassw0rd");
return dataSource;
}
}In questo esempio, la configurazione personalizzata del DataSource sostituisce quella fornita dall’autoconfigurazione.
4. Uso delle Annotations Condizionali
Spring Boot utilizza diverse annotazioni condizionali come @ConditionalOnMissingBean, @ConditionalOnProperty, ecc., per applicare configurazioni solo se certe condizioni sono soddisfatte. Questo permette una maggiore flessibilità nella definizione delle configurazioni:
@Configuration
public class ConditionalConfig {
@Bean
@ConditionalOnProperty(name = "app.featureX.enabled", havingValue = "true")
public FeatureX featureX() {
return new FeatureX();
}
}In questo caso, il bean FeatureX viene creato solo se la proprietà app.featureX.enabled è impostata su true.
Introduzione agli Starter di Spring Boot
Gli Starter di Spring Boot sono dei pacchetti di dipendenze predefinite che raggruppano insieme librerie comuni necessarie per determinate funzionalità. Gli Starter semplificano l’aggiunta di dipendenze al progetto, evitando la necessità di gestire manualmente versioni e compatibilità delle librerie.
Vantaggi degli Starter
-
Semplificazione delle Dipendenze:
Permettono di includere un set completo di dipendenze con una singola dichiarazione, riducendo la complessità nella gestione delle versioni.
-
Consistenza:
Garantiscono che tutte le librerie incluse siano compatibili tra loro, prevenendo conflitti di versione.
-
Modularità:
Consentono di aggiungere funzionalità specifiche al progetto senza introdurre dipendenze non necessarie.
Esempi di Starter Comuni
-
spring-boot-starter-web:Include le dipendenze necessarie per sviluppare applicazioni web, come Spring MVC, Tomcat, Jackson, ecc.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> -
spring-boot-starter-data-jpa:Comprende Spring Data JPA, Hibernate e un driver JDBC per la persistenza dei dati.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> -
spring-boot-starter-security:Fornisce le dipendenze necessarie per implementare la sicurezza nelle applicazioni, inclusi Spring Security.
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency>
Creazione di Starter Personalizzati
Oltre agli starter forniti da Spring Boot, è possibile creare starter personalizzati per riutilizzare configurazioni e dipendenze comuni all’interno della propria organizzazione o progetto.
Passaggi per Creare uno Starter Personalizzato:
-
Creare un Nuovo Progetto Maven o Gradle:
Configurare un progetto separato che fungerà da starter.
-
Definire le Dipendenze:
Aggiungere le dipendenze comuni che si desidera includere nello starter.
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Altre dipendenze comuni --> </dependencies> -
Aggiungere la Configurazione Automatica (opzionale):
Se lo starter include configurazioni automatiche, creare una classe di configurazione e registrarla in
META-INF/spring.factories.org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.miaazienda.starter.CustomAutoConfiguration -
Pubblicare lo Starter:
Distribuire lo starter al repository di artefatti utilizzato (ad esempio, Maven Central, Nexus) per renderlo disponibile ai progetti che lo utilizzeranno.
Utilizzo degli Starter Personalizzati
Una volta creato e pubblicato uno starter personalizzato, può essere aggiunto come dipendenza nei progetti che necessitano delle configurazioni e delle dipendenze incluse nello starter.
<dependency>
<groupId>com.miaazienda.starter</groupId>
<artifactId>custom-starter</artifactId>
<version>1.0.0</version>
</dependency>Esempio Pratico: Autoconfigurazione e Starter
Supponiamo di voler sviluppare un’applicazione web che utilizza Spring MVC e Spring Data JPA. Grazie agli starter, possiamo configurare rapidamente l’ambiente di sviluppo.
-
Creazione del Progetto:
Utilizzando Spring Initializr, selezioniamo gli starter necessari:
-
spring-boot-starter-web -
spring-boot-starter-data-jpa -
spring-boot-starter-thymeleaf(per la gestione delle view)
-
-
Dichiarazione delle Dipendenze (pom.xml):
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies> -
Configurazione del Datasource (application.properties):
spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password= spring.jpa.database-platform=org.hibernate.dialect.H2Dialect spring.h2.console.enabled=true -
Avvio dell’Applicazione:
Con le dipendenze e le proprietà configurate, Spring Boot si occuperà automaticamente di configurare il server web integrato (Tomcat), il datasource per H2 e l’entity manager per JPA.
-
Personalizzazione Aggiuntiva:
Supponiamo di voler personalizzare il comportamento di JPA. Possiamo aggiungere ulteriori proprietà o definire una classe di configurazione personalizzata.
spring.jpa.show-sql=true spring.jpa.hibernate.ddl-auto=create-dropQueste proprietà attivano la visualizzazione delle query SQL e configurano Hibernate per creare e cancellare lo schema del database all’avvio e allo spegnimento dell’applicazione.
Conclusioni
L’autoconfigurazione e gli starter di Spring Boot rappresentano strumenti potenti per accelerare lo sviluppo di applicazioni Java, riducendo la complessità della configurazione e promuovendo best practices. Comprendere come funzionano e come personalizzarli è essenziale sia per i nuovi sviluppatori che per i professionisti senior che desiderano ottimizzare il proprio flusso di lavoro e prepararsi efficacemente a colloqui tecnici approfonditi.
Attraverso l’autoconfigurazione, Spring Boot consente di avviare rapidamente un progetto con configurazioni sensate, mentre gli starter semplificano la gestione delle dipendenze, garantendo coerenza e compatibilità. La capacità di personalizzare queste configurazioni permette di adattare l’applicazione alle specifiche esigenze, mantenendo al contempo la semplicità e l’efficienza che caratterizzano Spring Boot.
Esercizio Pratico
Obiettivo: Creare un’applicazione Spring Boot che utilizza l’autoconfigurazione per gestire un database H2 e personalizzare alcune impostazioni JPA.
Passaggi:
-
Creare un nuovo progetto Spring Boot con gli starter
spring-boot-starter-webespring-boot-starter-data-jpa. -
Aggiungere la dipendenza H2 al
pom.xml:<dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> -
Configurare il datasource nel file
application.properties:spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password= spring.jpa.hibernate.ddl-auto=update spring.jpa.show-sql=true spring.h2.console.enabled=true -
Creare una semplice entità JPA:
@Entity public class Utente { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String nome; private String email; // Getters e setters } -
Definire un repository JPA:
public interface UtenteRepository extends JpaRepository<Utente, Long> { } -
Creare un controller REST:
@RestController @RequestMapping("/utenti") public class UtenteController { @Autowired private UtenteRepository utenteRepository; @GetMapping public List<Utente> getAllUtenti() { return utenteRepository.findAll(); } @PostMapping public Utente createUtente(@RequestBody Utente utente) { return utenteRepository.save(utente); } } -
Avviare l’applicazione e testare gli endpoint REST utilizzando strumenti come Postman o cURL.
Risultato Atteso:
L’applicazione avviata dovrebbe essere in grado di gestire le richieste HTTP per creare e recuperare utenti, utilizzando automaticamente il database H2 configurato tramite l’autoconfigurazione di Spring Boot.
Best Practices
-
Limitare le Esclusioni dell’Autoconfigurazione: Evitare di escludere componenti automatici a meno che non sia strettamente necessario. Le esclusioni possono complicare la manutenzione e la comprensione dell’applicazione.
-
Utilizzare le Proprietà per la Personalizzazione: Preferire la configurazione tramite proprietà piuttosto che definire classi di configurazione personalizzate, quando possibile, per mantenere la configurazione centralizzata e facilmente modificabile.
-
Creare Starter Personalizzati per Reusable Components: Se si sviluppano componenti comuni riutilizzabili in più progetti, considerare la creazione di starter personalizzati per semplificare l’inclusione delle dipendenze e delle configurazioni necessarie.
-
Documentare le Configurazioni Personalizzate: Mantenere una documentazione chiara delle personalizzazioni effettuate sull’autoconfigurazione per facilitare la manutenzione e l’onboarding di nuovi sviluppatori nel progetto.
Attraverso l’uso efficace dell’autoconfigurazione e degli starter, è possibile costruire applicazioni Spring Boot robuste, modulari e facilmente manutenibili, riducendo al minimo la complessità e massimizzando la produttività.
Capitolo 13: Sviluppo Web con Spring Boot
13.1 Spring MVC
Introduzione a Spring MVC
Spring MVC (Model-View-Controller) è un modulo del framework Spring che facilita lo sviluppo di applicazioni web seguendo il paradigma architetturale Model-View-Controller. Questo approccio separa chiaramente le diverse responsabilità all’interno dell’applicazione, migliorando la manutenzione, la testabilità e la scalabilità del codice.
In questa sezione, esploreremo i concetti fondamentali di Spring MVC, la sua architettura e come gestisce le richieste HTTP per costruire applicazioni web robuste e modulari.
Architettura Model-View-Controller
L’architettura Model-View-Controller suddivide un’applicazione in tre componenti principali:
-
Model (Modello): Rappresenta i dati e la logica di business dell’applicazione. Gestisce l’accesso ai dati, le regole di validazione e le interazioni con il database.
-
View (Vista): Responsabile della presentazione dei dati all’utente. In Spring MVC, le viste possono essere implementate utilizzando tecnologie come JSP, Thymeleaf, FreeMarker, ecc.
-
Controller (Controllore): Gestisce le richieste dell’utente, interagisce con il modello per elaborare i dati e determina quale vista restituire come risposta.
Questa separazione consente di gestire in modo più efficiente le modifiche, poiché ogni componente può essere sviluppato e aggiornato indipendentemente dagli altri.
Componenti Principali di Spring MVC
-
DispatcherServlet: È il front controller di Spring MVC e funge da punto di ingresso per tutte le richieste HTTP. È responsabile del routing delle richieste ai controller appropriati.
-
Handler Mapping: Determina quale controller deve gestire una determinata richiesta in base all’URL e ad altre informazioni della richiesta.
-
Controller: Componenti che elaborano le richieste, interagiscono con il modello e restituiscono una vista.
-
View Resolver: Determina quale tecnologia di visualizzazione utilizzare per rendere la risposta all’utente.
-
ModelAndView: Oggetto che contiene sia i dati del modello che il nome della vista da renderizzare.
Gestione delle Richieste in Spring MVC
La gestione delle richieste in Spring MVC segue un flusso ben definito:
-
Ricezione della Richiesta: Una richiesta HTTP arriva al
DispatcherServlet. -
Mappatura del Controller: Il
DispatcherServletutilizza l’Handler Mappingper identificare il controller appropriato che gestirà la richiesta. -
Elaborazione nel Controller: Il controller esegue la logica di business necessaria, interagendo con il modello per recuperare o aggiornare i dati.
-
Preparazione della Vista: Il controller restituisce un oggetto
ModelAndViewche contiene i dati del modello e il nome della vista da utilizzare. -
Rendering della Vista: Il
View Resolverdetermina la tecnologia di visualizzazione appropriata e renderizza la risposta all’utente.
Esempio Pratico: Creazione di un’Applicazione Spring MVC
Vediamo come creare una semplice applicazione Spring MVC che gestisce richieste per visualizzare un elenco di prodotti.
Passo 1: Configurazione del Progetto
Utilizzeremo Spring Boot per semplificare la configurazione. Assicurati di avere configurato l’ambiente di sviluppo con JDK e un IDE (come IntelliJ IDEA o Eclipse).
File pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.esempio</groupId>
<artifactId>spring-mvc-demo</artifactId>
<version>1.0.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
</parent>
<dependencies>
<!-- Dipendenze Spring Boot Starter Web per Spring MVC -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Dipendenza per Thymeleaf come motore di template -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
</dependencies>
</project>Passo 2: Creazione del Modello
Definiamo una semplice classe Product che rappresenta un prodotto.
File Product.java:
package com.esempio.springmvcdemo.model;
public class Product {
private Long id;
private String name;
private Double price;
// Costruttori
public Product() {}
public Product(Long id, String name, Double price) {
this.id = id;
this.name = name;
this.price = price;
}
// Getter e Setter
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
}Passo 3: Creazione del Controller
Creiamo un controller che gestisce le richieste per visualizzare l’elenco dei prodotti.
File ProductController.java:
package com.esempio.springmvcdemo.controller;
import com.esempio.springmvcdemo.model.Product;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.Arrays;
import java.util.List;
@Controller
public class ProductController {
@GetMapping("/products")
public String listProducts(Model model) {
List<Product> products = Arrays.asList(
new Product(1L, "Laptop", 999.99),
new Product(2L, "Smartphone", 499.99),
new Product(3L, "Tablet", 299.99)
);
model.addAttribute("products", products);
return "product-list";
}
}Spiegazione:
-
L’annotazione
@Controllerindica che questa classe è un controller Spring MVC. -
Il metodo
listProductsè mappato all’URL/productsgrazie all’annotazione@GetMapping. -
Utilizza l’oggetto
Modelper aggiungere l’elenco dei prodotti che sarà disponibile nella vista. -
Restituisce il nome della vista (
product-list) che verrà renderizzata.
Passo 4: Creazione della Vista
Creiamo una vista Thymeleaf per visualizzare l’elenco dei prodotti.
File src/main/resources/templates/product-list.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Elenco Prodotti</title>
<meta charset="UTF-8">
</head>
<body>
<h1>Elenco dei Prodotti</h1>
<table border="1">
<thead>
<tr>
<th>ID</th>
<th>Nome</th>
<th>Prezzo (€)</th>
</tr>
</thead>
<tbody>
<tr th:each="product : ${products}">
<td th:text="${product.id}">1</td>
<td th:text="${product.name}">Laptop</td>
<td th:text="${product.price}">999.99</td>
</tr>
</tbody>
</table>
</body>
</html>Spiegazione:
-
Utilizziamo Thymeleaf come motore di template per generare dinamicamente il contenuto HTML.
-
L’iterazione
th:eachpercorre l’elenco dei prodotti passato dal controller. -
Le espressioni
th:textsostituiscono il contenuto delle celle della tabella con i dati dei prodotti.
Passo 5: Esecuzione dell’Applicazione
Creiamo la classe principale per avviare l’applicazione Spring Boot.
File SpringMvcDemoApplication.java:
package com.esempio.springmvcdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringMvcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringMvcDemoApplication.class, args);
}
}Esecuzione:
-
Compila ed esegui l’applicazione tramite l’IDE o utilizzando il comando Maven:
mvn spring-boot:run -
Apri il browser e naviga all’indirizzo http://localhost:8080/products.
Risultato:
Vedrai una pagina HTML che elenca i prodotti con i loro ID, nomi e prezzi.
Personalizzazione del Routing e delle Risposte
Spring MVC offre molta flessibilità nella gestione delle richieste. Vediamo alcune personalizzazioni comuni:
Mappatura di URL Dinamici
Possiamo gestire URL con parametri dinamici utilizzando le annotazioni di mappatura.
Esempio: Visualizzazione dei Dettagli di un Prodotto
Aggiungiamo un metodo nel controller per visualizzare i dettagli di un singolo prodotto.
Aggiornamento di ProductController.java:
@GetMapping("/products/{id}")
public String getProductDetails(@PathVariable Long id, Model model) {
// Simuliamo il recupero del prodotto da un database
Product product = new Product(id, "Prodotto " + id, 100.0 + id);
model.addAttribute("product", product);
return "product-details";
}File src/main/resources/templates/product-details.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Dettagli Prodotto</title>
<meta charset="UTF-8">
</head>
<body>
<h1>Dettagli del Prodotto</h1>
<p><strong>ID:</strong> <span th:text="${product.id}">1</span></p>
<p><strong>Nome:</strong> <span th:text="${product.name}">Laptop</span></p>
<p><strong>Prezzo:</strong> <span th:text="${product.price}">999.99</span> €</p>
<a href="/products">Torna all'elenco dei prodotti</a>
</body>
</html>Spiegazione:
-
L’annotazione
@PathVariableestrae il parametro{id}dall’URL. -
Il metodo recupera il prodotto corrispondente e lo aggiunge al modello.
-
La vista
product-details.htmlvisualizza i dettagli del prodotto.
Gestione delle Form e dei Dati POST
Spring MVC semplifica anche la gestione delle richieste POST e dei dati inviati tramite form.
Esempio: Aggiunta di un Nuovo Prodotto
Aggiungiamo funzionalità per inserire un nuovo prodotto attraverso un form.
Aggiornamento di ProductController.java:
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.ModelAttribute;
// Metodo per visualizzare il form di aggiunta prodotto
@GetMapping("/products/new")
public String showAddProductForm(Model model) {
model.addAttribute("product", new Product());
return "add-product";
}
// Metodo per gestire l'invio del form
@PostMapping("/products")
public String addProduct(@ModelAttribute Product product) {
// Qui si salverebbe il prodotto nel database
// Per questo esempio, semplicemente stampiamo i dettagli
System.out.println("Aggiunto prodotto: " + product.getName());
return "redirect:/products";
}File src/main/resources/templates/add-product.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Aggiungi Prodotto</title>
<meta charset="UTF-8">
</head>
<body>
<h1>Aggiungi un Nuovo Prodotto</h1>
<form action="#" th:action="@{/products}" th:object="${product}" method="post">
<p>
<label for="name">Nome:</label>
<input type="text" id="name" th:field="*{name}" />
</p>
<p>
<label for="price">Prezzo (€):</label>
<input type="text" id="price" th:field="*{price}" />
</p>
<p>
<button type="submit">Aggiungi</button>
</p>
</form>
<a href="/products">Torna all'elenco dei prodotti</a>
</body>
</html>Spiegazione:
-
Il metodo
showAddProductFormvisualizza un form vuoto per l’inserimento di un nuovo prodotto. -
L’annotazione
@ModelAttributecollega i campi del form agli attributi dell’oggettoProduct. -
Dopo l’invio del form, il metodo
addProductgestisce i dati e reindirizza l’utente all’elenco dei prodotti.
Gestione delle Eccezioni nel Controller
Spring MVC permette di gestire le eccezioni in modo centralizzato utilizzando l’annotazione @ExceptionHandler.
Esempio: Gestione di un’eccezione per prodotto non trovato
Aggiornamento di ProductController.java:
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ResponseStatus;
// Metodo per recuperare un prodotto simulando una condizione di errore
@GetMapping("/products/{id}")
public String getProductDetails(@PathVariable Long id, Model model) {
if (id <= 0) {
throw new ProductNotFoundException("ID del prodotto non valido: " + id);
}
Product product = new Product(id, "Prodotto " + id, 100.0 + id);
model.addAttribute("product", product);
return "product-details";
}
// Definizione di una classe eccezione personalizzata
@ResponseStatus(value = HttpStatus.NOT_FOUND)
public static class ProductNotFoundException extends RuntimeException {
public ProductNotFoundException(String message) {
super(message);
}
}
// Gestore globale delle eccezioni nel controller
@ExceptionHandler(ProductNotFoundException.class)
public String handleProductNotFound(ProductNotFoundException ex, Model model) {
model.addAttribute("errorMessage", ex.getMessage());
return "error";
}File src/main/resources/templates/error.html:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Errore</title>
<meta charset="UTF-8">
</head>
<body>
<h1>Si è verificato un errore</h1>
<p th:text="${errorMessage}">Messaggio di errore</p>
<a href="/products">Torna all'elenco dei prodotti</a>
</body>
</html>Spiegazione:
-
Definiamo una classe eccezione personalizzata
ProductNotFoundExceptioncon l’annotazione@ResponseStatusper impostare lo status HTTP. -
Il metodo
handleProductNotFoundgestisce le eccezioni di tipoProductNotFoundExceptione restituisce una vista di errore con un messaggio appropriato. -
Se viene richiesto un prodotto con un ID non valido (ad esempio,
id <= 0), viene lanciata un’eccezione e l’utente viene reindirizzato alla pagina di errore.
Best Practices nell’Utilizzo di Spring MVC
-
Separazione delle Responsabilità: Mantieni la logica di business nei servizi e lascia ai controller solo la gestione delle richieste e delle risposte.
-
Validazione dei Dati: Utilizza le API di validazione di Spring per garantire che i dati in ingresso siano corretti e sicuri.
-
Gestione Centralizzata delle Eccezioni: Implementa gestori di eccezioni globali per evitare la duplicazione del codice e migliorare la gestione degli errori.
-
Utilizzo di Template Engine Moderni: Thymeleaf è una scelta popolare grazie alla sua integrazione stretta con Spring e la facilità d’uso.
-
Sicurezza delle Applicazioni Web: Integra Spring Security per proteggere le tue applicazioni da accessi non autorizzati e vulnerabilità comuni.
-
Documentazione delle API: Se sviluppi API RESTful, utilizza strumenti come Swagger per documentare e testare le tue API in modo efficace.
Conclusioni
Spring MVC è un potente modulo del framework Spring che consente di sviluppare applicazioni web in modo efficiente e strutturato. Grazie alla sua architettura flessibile e alle numerose funzionalità integrate, è possibile costruire applicazioni scalabili, manutenibili e sicure. Comprendere i concetti di base di Spring MVC è fondamentale per avanzare verso lo sviluppo di microservizi con Spring Boot, che esploreremo nelle sezioni successive.
Esercizio Pratico
Obiettivo: Estendere l’applicazione Spring MVC creata per includere la funzionalità di modifica di un prodotto esistente.
Passaggi:
-
Aggiungere un metodo nel controller per visualizzare il form di modifica.
-
Creare una vista Thymeleaf per il form di modifica.
-
Gestire la richiesta POST per aggiornare il prodotto.
-
Testare l’applicazione assicurandosi che la modifica funzioni correttamente.
Suggerimento: Utilizza l’annotazione @PathVariable per identificare il prodotto da modificare e @ModelAttribute per legare i dati del form all’oggetto Product.
Questo conclude la sezione su Spring MVC. Nei prossimi paragrafi approfondiremo la creazione di API RESTful, la validazione dei dati e altre funzionalità avanzate offerte da Spring Boot per lo sviluppo web.
13.2 Creazione di API RESTful
Introduzione alle API RESTful
Le API (Application Programming Interface) RESTful rappresentano uno standard de facto per la comunicazione tra client e server nel mondo del web moderno. REST (REpresentational State Transfer) è uno stile architetturale che sfrutta i principi fondamentali del protocollo HTTP per creare servizi scalabili, leggeri e facilmente manutenibili. Le API RESTful permettono di esporre risorse tramite endpoint ben definiti, utilizzando metodi HTTP standard (GET, POST, PUT, DELETE) per operare su tali risorse.
Principi chiave delle API RESTful:
-
Client-Server: Separazione delle preoccupazioni tra client e server, permettendo a ciascuno di evolversi indipendentemente.
-
Stateless: Ogni richiesta del client al server deve contenere tutte le informazioni necessarie per comprendere e processare la richiesta. Il server non mantiene lo stato del client tra le richieste.
-
Cacheable: Le risposte devono indicare se possono essere memorizzate nella cache, migliorando le prestazioni e riducendo la latenza.
-
Interfaccia Uniforme: Utilizzo di convenzioni standard per la comunicazione, facilitando l’interoperabilità.
-
Layered System: Possibilità di utilizzare intermediari come proxy o bilanciatori di carico senza influire sulla comunicazione tra client e server.
-
Code on Demand (opzionale): Capacità di estendere le funzionalità del client tramite l’invio di codice eseguibile (es. JavaScript).
Creazione di API RESTful con Spring Boot
Spring Boot semplifica la creazione di API RESTful grazie alle sue funzionalità integrate e alla sua filosofia di “convenzione sulla configurazione”. Di seguito, esploreremo i passi fondamentali per creare una semplice API RESTful utilizzando Spring Boot.
1. Configurazione del Progetto
Prima di tutto, creiamo un nuovo progetto Spring Boot. Puoi utilizzare Spring Initializr per generare la struttura di base del progetto. Seleziona le seguenti dipendenze:
-
Spring Web: Necessaria per costruire applicazioni web, inclusi servizi RESTful.
-
Spring Data JPA: Per l’accesso ai dati (opzionale, se si prevede di interagire con un database).
-
H2 Database: Un database in memoria per scopi di sviluppo e testing (opzionale).
2. Definizione del Modello
Supponiamo di voler creare un’API per gestire una lista di Utenti. Iniziamo definendo una classe modello User.
package com.example.demo.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Costruttori
public User() {}
public User(String name, String email) {
this.name = name;
this.email = email;
}
// Getter e Setter
public Long getId() {
return id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}Spiegazione:
-
@Entity: Indica che questa classe è una entità JPA e sarà mappata a una tabella del database.
-
@Id e @GeneratedValue: Definiscono la chiave primaria e la strategia di generazione automatica dell’ID.
3. Creazione del Repository
Il repository fornisce un’interfaccia per interagire con il database senza la necessità di implementare manualmente le operazioni CRUD.
package com.example.demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.example.demo.model.User;
public interface UserRepository extends JpaRepository<User, Long> {
// Metodi di ricerca personalizzati possono essere aggiunti qui
}Spiegazione:
- JpaRepository<User, Long>: Fornisce metodi CRUD predefiniti per l’entità
Usercon ID di tipoLong.
4. Implementazione del Controller REST
Il controller gestisce le richieste HTTP e interagisce con il repository per eseguire le operazioni richieste.
package com.example.demo.controller;
import java.util.List;
import java.util.Optional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import com.example.demo.model.User;
import com.example.demo.repository.UserRepository;
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserRepository userRepository;
// GET /api/users - Recupera tutti gli utenti
@GetMapping
public List<User> getAllUsers() {
return userRepository.findAll();
}
// GET /api/users/{id} - Recupera un utente per ID
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
Optional<User> userOpt = userRepository.findById(id);
return userOpt.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// POST /api/users - Crea un nuovo utente
@PostMapping
public User createUser(@RequestBody User user) {
return userRepository.save(user);
}
// PUT /api/users/{id} - Aggiorna un utente esistente
@PutMapping("/{id}")
public ResponseEntity<User> updateUser(@PathVariable Long id, @RequestBody User userDetails) {
Optional<User> userOpt = userRepository.findById(id);
if (!userOpt.isPresent()) {
return ResponseEntity.notFound().build();
}
User user = userOpt.get();
user.setName(userDetails.getName());
user.setEmail(userDetails.getEmail());
User updatedUser = userRepository.save(user);
return ResponseEntity.ok(updatedUser);
}
// DELETE /api/users/{id} - Elimina un utente
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteUser(@PathVariable Long id) {
Optional<User> userOpt = userRepository.findById(id);
if (!userOpt.isPresent()) {
return ResponseEntity.notFound().build();
}
userRepository.delete(userOpt.get());
return ResponseEntity.noContent().build();
}
}Spiegazione:
-
@RestController: Indica che questa classe gestisce le richieste REST e che le risposte sono direttamente i corpi delle risposte HTTP (senza la necessità di utilizzare
@ResponseBodysu ogni metodo). -
@RequestMapping(“/api/users”): Definisce il percorso di base per tutte le richieste gestite da questo controller.
-
@GetMapping, @PostMapping, @PutMapping, @DeleteMapping: Mappe specifiche per i diversi metodi HTTP.
-
@PathVariable: Estrae valori dai segmenti del percorso URL.
-
@RequestBody: Indica che il corpo della richiesta HTTP deve essere deserializzato in un oggetto Java.
5. Gestione delle Risposte e degli Errori
Per una migliore gestione delle risposte e degli errori, è possibile utilizzare ResponseEntity per controllare lo stato HTTP restituito e il corpo della risposta.
Esempio: Recupero di un Utente per ID
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
Optional<User> userOpt = userRepository.findById(id);
return userOpt.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}In questo esempio, se l’utente con l’ID specificato esiste, viene restituito con uno status 200 OK. Altrimenti, viene restituito uno status 404 Not Found.
6. Validazione dei Dati
Per garantire che i dati in ingresso siano validi, Spring Boot supporta la Bean Validation API. È possibile annotare i campi del modello con annotazioni di validazione e utilizzare @Valid nel controller.
Aggiornamento del Modello User con Validazione:
package com.example.demo.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.validation.constraints.Email;
import javax.validation.constraints.NotBlank;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "Il nome non può essere vuoto")
private String name;
@Email(message = "L'email deve essere valida")
@NotBlank(message = "L'email non può essere vuota")
private String email;
// Costruttori, Getter e Setter...
}Aggiornamento del Controller per la Validazione:
@PostMapping
public ResponseEntity<User> createUser(@Valid @RequestBody User user, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
// Gestione degli errori di validazione
return ResponseEntity.badRequest().build();
}
User savedUser = userRepository.save(user);
return ResponseEntity.status(HttpStatus.CREATED).body(savedUser);
}Spiegazione:
-
@NotBlank e @Email: Annotations per la validazione dei campi.
-
@Valid: Indica che il corpo della richiesta deve essere validato secondo le annotazioni presenti nel modello.
-
BindingResult: Contiene i risultati della validazione. Se ci sono errori, possiamo gestirli appropriatamente.
7. Esempio Completo
Mettiamo insieme tutto ciò che abbiamo visto in un esempio completo di creazione di un’API RESTful per gestire gli utenti.
Passo 1: Creazione del Progetto
Utilizza Spring Initializr per creare un progetto con le dipendenze Spring Web, Spring Data JPA, e H2 Database.
Passo 2: Definizione del Modello User
package com.example.demo.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.validation.constraints.Email;
import javax.validation.constraints.NotBlank;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "Il nome non può essere vuoto")
private String name;
@Email(message = "L'email deve essere valida")
@NotBlank(message = "L'email non può essere vuota")
private String email;
// Costruttori, Getter e Setter...
}Passo 3: Creazione del Repository
package com.example.demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.example.demo.model.User;
public interface UserRepository extends JpaRepository<User, Long> {
}Passo 4: Implementazione del Controller UserController
package com.example.demo.controller;
import java.util.List;
import java.util.Optional;
import javax.validation.Valid;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.validation.BindingResult;
import org.springframework.web.bind.annotation.*;
import com.example.demo.model.User;
import com.example.demo.repository.UserRepository;
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserRepository userRepository;
// GET /api/users
@GetMapping
public List<User> getAllUsers() {
return userRepository.findAll();
}
// GET /api/users/{id}
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
Optional<User> userOpt = userRepository.findById(id);
return userOpt.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// POST /api/users
@PostMapping
public ResponseEntity<User> createUser(@Valid @RequestBody User user, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
// In un'applicazione reale, potresti restituire i messaggi di errore dettagliati
return ResponseEntity.badRequest().build();
}
User savedUser = userRepository.save(user);
return ResponseEntity.status(HttpStatus.CREATED).body(savedUser);
}
// PUT /api/users/{id}
@PutMapping("/{id}")
public ResponseEntity<User> updateUser(@PathVariable Long id, @Valid @RequestBody User userDetails, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
return ResponseEntity.badRequest().build();
}
Optional<User> userOpt = userRepository.findById(id);
if (!userOpt.isPresent()) {
return ResponseEntity.notFound().build();
}
User user = userOpt.get();
user.setName(userDetails.getName());
user.setEmail(userDetails.getEmail());
User updatedUser = userRepository.save(user);
return ResponseEntity.ok(updatedUser);
}
// DELETE /api/users/{id}
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteUser(@PathVariable Long id) {
Optional<User> userOpt = userRepository.findById(id);
if (!userOpt.isPresent()) {
return ResponseEntity.notFound().build();
}
userRepository.delete(userOpt.get());
return ResponseEntity.noContent().build();
}
}Passo 5: Configurazione dell’Applicazione
Assicurati di configurare il database in application.properties per utilizzare H2.
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.h2.console.enabled=true
spring.jpa.show-sql=true
Passo 6: Avvio dell’Applicazione
Esegui la classe principale dell’applicazione:
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}Una volta avviata l’applicazione, puoi testare le API utilizzando strumenti come Postman o cURL.
Esempi di Richieste:
-
Creare un Utente:
curl -X POST http://localhost:8080/api/users \ -H "Content-Type: application/json" \ -d '{"name": "Mario Rossi", "email": "mario.rossi@example.com"}' -
Recuperare Tutti gli Utenti:
curl http://localhost:8080/api/users -
Aggiornare un Utente:
curl -X PUT http://localhost:8080/api/users/1 \ -H "Content-Type: application/json" \ -d '{"name": "Maria Rossi", "email": "maria.rossi@example.com"}' -
Eliminare un Utente:
curl -X DELETE http://localhost:8080/api/users/1
Best Practices nella Creazione di API RESTful
-
Strutturazione degli Endpoint:
-
Utilizza nomi di risorse plurali (es.
/api/users). -
Evita di includere verbi negli endpoint; il verbo HTTP definisce l’azione.
-
-
Versionamento delle API:
- Implementa versioni nelle tue API per gestire modifiche future senza interrompere i client esistenti (es.
/api/v1/users).
- Implementa versioni nelle tue API per gestire modifiche future senza interrompere i client esistenti (es.
-
Gestione degli Errori:
-
Fornisci messaggi di errore chiari e coerenti.
-
Utilizza codici di stato HTTP appropriati (es.
400 Bad Request,404 Not Found,500 Internal Server Error).
-
-
Sicurezza:
-
Proteggi le tue API utilizzando meccanismi di autenticazione e autorizzazione (es. OAuth2, JWT).
-
Valida e sanifica tutte le input per prevenire attacchi come SQL Injection e XSS.
-
-
Documentazione:
-
Documenta le tue API in modo dettagliato utilizzando strumenti come Swagger o OpenAPI.
-
Fornisci esempi di richieste e risposte per facilitare l’adozione da parte dei client.
-
-
Pagination e Filtering:
-
Implementa la paginazione per gestire grandi quantità di dati.
-
Fornisci meccanismi di filtraggio e ordinamento per migliorare l’usabilità.
-
-
Utilizzo di HATEOAS (Hypermedia as the Engine of Application State):
- Includi link nelle risposte per guidare i client attraverso le operazioni disponibili.
Conclusioni
La creazione di API RESTful con Spring Boot è un processo semplificato grazie alle numerose funzionalità e convenzioni offerte dal framework. Seguendo i principi REST e le best practices, è possibile costruire servizi web robusti, scalabili e facili da manutenere. L’esempio fornito illustra i passaggi fondamentali per implementare un’API completa, ma Spring Boot offre molte altre funzionalità avanzate che possono essere esplorate per soddisfare esigenze più complesse.
Esercizio Pratico
Obiettivo: Estendere l’API degli utenti per includere una funzionalità di ricerca per nome.
Passi:
-
Aggiungere un Metodo Personalizzato nel Repository:
List<User> findByNameContainingIgnoreCase(String name); -
Implementare l’Endpoint di Ricerca nel Controller:
// GET /api/users/search?name=... @GetMapping("/search") public List<User> searchUsersByName(@RequestParam String name) { return userRepository.findByNameContainingIgnoreCase(name); } -
Testare l’Endpoint:
curl http://localhost:8080/api/users/search?name=mario
Risultato Atteso:
Una lista di utenti il cui nome contiene la stringa “mario”, indipendentemente dalla maiuscola o minuscola.
Seguendo questa sezione, avrai una solida base per comprendere come costruire API RESTful efficaci e mantenibili utilizzando Spring Boot. Continua a esplorare e sperimentare con le diverse funzionalità offerte dal framework per arricchire ulteriormente le tue applicazioni.
13.3 Validazione dei Dati
La validazione dei dati è un aspetto cruciale nello sviluppo di applicazioni web, poiché garantisce che le informazioni ricevute dall’utente o da altre fonti siano corrette, complete e conformi alle regole di business definite. In questo contesto, Spring Boot offre strumenti potenti e flessibili per implementare la validazione dei dati in modo efficace e semplice. In questa sezione, esploreremo i fondamenti della validazione dei dati utilizzando la Bean Validation API (JSR 380) e come integrarla nelle applicazioni Spring Boot attraverso esempi pratici.
13.3.1 Introduzione alla Bean Validation API
La Bean Validation API è uno standard Java (definito nella JSR 380) che fornisce un framework per la validazione dei dati a livello di bean, utilizzando annotazioni per definire le regole di validazione direttamente sui modelli di dati. Questa metodologia promuove una separazione chiara tra la logica di business e le regole di validazione, migliorando la manutenibilità e la leggibilità del codice.
Vantaggi della Bean Validation:
-
Semplicità: Utilizzo di annotazioni per definire le regole di validazione.
-
Riusabilità: Le stesse regole possono essere applicate in diversi contesti (controller, servizi, ecc.).
-
Estendibilità: Possibilità di creare validatori personalizzati per esigenze specifiche.
-
Integrazione: Compatibilità nativa con Spring Boot e altri framework Java.
13.3.2 Annotazioni di Validazione Comuni
La Bean Validation API fornisce una serie di annotazioni predefinite che possono essere utilizzate per specificare le regole di validazione. Di seguito sono elencate alcune delle annotazioni più comuni:
-
@NotNull: Assicura che il valore non sia
null.@NotNull(message = "Il campo non può essere nullo") private String nome; -
@Size: Specifica la dimensione minima e/o massima di una collezione, array, stringa, ecc.
@Size(min = 2, max = 30, message = "Il nome deve avere tra 2 e 30 caratteri") private String nome; -
@Min e @Max: Impongono un valore minimo e massimo su numeri.
@Min(value = 18, message = "L'età deve essere almeno 18") @Max(value = 65, message = "L'età non può superare i 65 anni") private Integer eta; -
@Email: Verifica che il valore sia un indirizzo email valido.
@Email(message = "Deve essere un indirizzo email valido") private String email; -
@Pattern: Valida il valore contro una regex specificata.
@Pattern(regexp = "^\\+?[0-9. ()-]{7,25}$", message = "Numero di telefono non valido") private String telefono;
13.3.3 Implementazione della Validazione in Spring Boot
Per integrare la validazione dei dati in un’applicazione Spring Boot, seguire i passaggi riportati di seguito:
-
Aggiungere le Dipendenze Necessarie
Assicurarsi che il progetto includa le dipendenze per la Bean Validation. Spring Boot Starter Web include già la dipendenza per
spring-boot-starter-validation, ma in caso contrario, aggiungerla manualmente.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> -
Definire il Modello di Dati con Annotazioni di Validazione
Creare una classe di modello e applicare le annotazioni di validazione sui campi.
import javax.validation.constraints.Email; import javax.validation.constraints.NotNull; import javax.validation.constraints.Size; public class Utente { @NotNull(message = "Il nome non può essere nullo") @Size(min = 2, max = 30, message = "Il nome deve avere tra 2 e 30 caratteri") private String nome; @NotNull(message = "L'email non può essere nulla") @Email(message = "Deve essere un indirizzo email valido") private String email; // Getters e Setters } -
Utilizzare le Annotazioni di Validazione nei Controller
Nel controller, utilizzare l’annotazione
@Validper attivare la validazione eBindingResultper gestire eventuali errori.import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.validation.BindingResult; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RestController; import javax.validation.Valid; @RestController public class UtenteController { @PostMapping("/utenti") public ResponseEntity<String> creaUtente(@Valid @RequestBody Utente utente, BindingResult result) { if (result.hasErrors()) { String errorMsg = result.getAllErrors() .stream() .map(error -> error.getDefaultMessage()) .collect(Collectors.joining(", ")); return new ResponseEntity<>(errorMsg, HttpStatus.BAD_REQUEST); } // Logica per salvare l'utente return new ResponseEntity<>("Utente creato con successo", HttpStatus.CREATED); } } -
Gestire gli Errori di Validazione Globalmente
Per una gestione centralizzata degli errori di validazione, è possibile creare un controller di eccezioni globale utilizzando
@ControllerAdvice.import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.validation.FieldError; import org.springframework.web.bind.MethodArgumentNotValidException; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.bind.annotation.ExceptionHandler; import java.util.HashMap; import java.util.Map; @ControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(MethodArgumentNotValidException.class) public ResponseEntity<Map<String, String>> handleValidationExceptions(MethodArgumentNotValidException ex) { Map<String, String> errors = new HashMap<>(); ex.getBindingResult().getAllErrors().forEach((error) -> { String fieldName = ((FieldError) error).getField(); String errorMessage = error.getDefaultMessage(); errors.put(fieldName, errorMessage); }); return new ResponseEntity<>(errors, HttpStatus.BAD_REQUEST); } }Questo approccio migliora la manutenibilità e consente di personalizzare le risposte di errore in modo coerente in tutta l’applicazione.
13.3.4 Creazione di Validatori Personalizzati
Oltre alle annotazioni predefinite, potrebbe essere necessario creare validatori personalizzati per soddisfare requisiti specifici. Ad esempio, supponiamo di voler validare che un campo password soddisfi determinate regole di complessità.
-
Definire l’Annotazione Personalizzata
import javax.validation.Constraint; import javax.validation.Payload; import java.lang.annotation.Documented; import java.lang.annotation.Retention; import java.lang.annotation.Target; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.RetentionPolicy.RUNTIME; @Documented @Constraint(validatedBy = PasswordValidator.class) @Target({ FIELD }) @Retention(RUNTIME) public @interface ValidPassword { String message() default "Password non valida"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; } -
Implementare il Validator
import javax.validation.ConstraintValidator; import javax.validation.ConstraintValidatorContext; public class PasswordValidator implements ConstraintValidator<ValidPassword, String> { @Override public void initialize(ValidPassword constraintAnnotation) { } @Override public boolean isValid(String password, ConstraintValidatorContext context) { if (password == null) { return false; } // Esempio di regole: almeno 8 caratteri, una lettera maiuscola, una minuscola e un numero return password.matches("^(?=.*[a-z])(?=.*[A-Z])(?=.*\\d).{8,}$"); } } -
Applicare l’Annotazione nel Modello
public class Utente { // Altri campi @ValidPassword private String password; // Getters e Setters }
13.3.5 Best Practices per la Validazione dei Dati
Per garantire una validazione efficace e mantenibile, seguire queste best practices:
-
Definire le Regole di Validazione nel Modello di Dati: Centralizzare le regole di validazione direttamente nei modelli facilita la comprensione e la gestione delle regole stesse.
-
Utilizzare Messaggi di Errore Chiari e Significativi: I messaggi di errore dovrebbero essere comprensibili per l’utente finale e fornire indicazioni precise su come correggere l’errore.
-
Validare sia lato Client che lato Server: Anche se la validazione lato client migliora l’esperienza utente, la validazione lato server è fondamentale per garantire la sicurezza e l’integrità dei dati.
-
Gestire Centralmente gli Errori di Validazione: Utilizzare
@ControllerAdviceper gestire gli errori in modo uniforme in tutta l’applicazione. -
Evitare la Logica di Validazione Complessa nei Validator Personalizzati: Mantieni i validatori semplici e focalizzati sulla verifica di una singola regola. Per logiche più complesse, considera l’implementazione di servizi di validazione separati.
13.3.6 Esempio Completo: Validazione di un Oggetto di Registrazione
Consideriamo un esempio completo in cui un utente si registra tramite un endpoint RESTful. Il processo include la validazione dei dati di input e la gestione degli errori.
-
Modello di Dati
import javax.validation.constraints.Email; import javax.validation.constraints.NotBlank; import javax.validation.constraints.Size; public class RegistrazioneRequest { @NotBlank(message = "Il nome utente è obbligatorio") @Size(min = 3, max = 20, message = "Il nome utente deve avere tra 3 e 20 caratteri") private String username; @NotBlank(message = "La password è obbligatoria") @ValidPassword private String password; @NotBlank(message = "L'email è obbligatoria") @Email(message = "Deve essere un indirizzo email valido") private String email; // Getters e Setters } -
Controller
import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RestController; import javax.validation.Valid; @RestController public class RegistrazioneController { @PostMapping("/registrazione") public ResponseEntity<String> registraUtente(@Valid @RequestBody RegistrazioneRequest request) { // Logica per registrare l'utente return new ResponseEntity<>("Registrazione avvenuta con successo", HttpStatus.CREATED); } } -
Gestione Globale degli Errori
import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.validation.FieldError; import org.springframework.web.bind.MethodArgumentNotValidException; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.bind.annotation.ExceptionHandler; import java.util.HashMap; import java.util.Map; @ControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(MethodArgumentNotValidException.class) public ResponseEntity<Map<String, String>> handleValidationExceptions(MethodArgumentNotValidException ex) { Map<String, String> errors = new HashMap<>(); ex.getBindingResult().getAllErrors().forEach((error) -> { String fieldName = ((FieldError) error).getField(); String errorMessage = error.getDefaultMessage(); errors.put(fieldName, errorMessage); }); return new ResponseEntity<>(errors, HttpStatus.BAD_REQUEST); } } -
Esempio di Richiesta e Risposta
Richiesta HTTP POST a
/registrazionecon il seguente JSON:{ "username": "jo", "password": "password", "email": "invalid-email" }Risposta HTTP 400 Bad Request:
{ "username": "Il nome utente deve avere tra 3 e 20 caratteri", "password": "Password non valida", "email": "Deve essere un indirizzo email valido" }In questo esempio, la richiesta contiene errori di validazione: il nome utente è troppo corto, la password non soddisfa le regole di complessità e l’email non è valida. La risposta fornisce messaggi chiari per ogni campo che ha fallito la validazione, facilitando la correzione da parte dell’utente.
13.3.7 Considerazioni Finali
La validazione dei dati è essenziale per garantire la qualità e la sicurezza delle applicazioni. Utilizzando la Bean Validation API insieme a Spring Boot, è possibile implementare regole di validazione robuste e mantenibili con un minimo sforzo. Ricorda di mantenere le regole di validazione semplici e di gestire gli errori in modo coerente per offrire una migliore esperienza utente e ridurre i rischi di errori e vulnerabilità.
Capitolo 14: Persistenza e Accesso ai Dati
14.1 Spring Data JPA
Introduzione a Spring Data JPA
Spring Data JPA è un modulo del framework Spring che semplifica l’interazione con i database relazionali utilizzando Java Persistence API (JPA). Fornisce un’astrazione di alto livello per la gestione dei dati, eliminando gran parte del boilerplate code necessario per operazioni CRUD (Create, Read, Update, Delete) e query complesse. L’obiettivo principale di Spring Data JPA è rendere lo sviluppo di applicazioni data-driven più rapido ed efficiente, consentendo agli sviluppatori di concentrarsi sulla logica di business piuttosto che sulla gestione dettagliata delle operazioni di persistenza.
Perché Utilizzare Spring Data JPA?
-
Riduzione del Boilerplate Code: Senza Spring Data JPA, le operazioni CRUD richiedono l’implementazione manuale di repository con metodi per ogni operazione. Spring Data JPA automatizza questo processo, riducendo la quantità di codice necessario.
-
Astrazione della Persistenza: Fornisce un livello di astrazione che separa la logica di accesso ai dati dal resto dell’applicazione, facilitando la manutenzione e l’evoluzione del codice.
-
Supporto per Query Complesse: Permette di definire query personalizzate utilizzando il linguaggio di query JPQL, SQL nativo o metodi di naming convenzionali, rendendo semplice l’accesso a dati complessi.
-
Integrazione con Spring Ecosystem: Si integra perfettamente con altri moduli di Spring, come Spring MVC e Spring Security, facilitando lo sviluppo di applicazioni complete e robuste.
Concetti Chiave di Spring Data JPA
-
Entity: Rappresenta una tabella nel database. Ogni istanza di un’entità corrisponde a una riga nella tabella.
-
Repository: Interfaccia che estende uno dei repository base di Spring Data, come
JpaRepository, fornendo metodi predefiniti per operazioni CRUD e la possibilità di definire metodi di query personalizzati. -
EntityManager: Componente di JPA responsabile della gestione del ciclo di vita delle entità e delle operazioni di persistenza.
Configurazione di Spring Data JPA
Prima di utilizzare Spring Data JPA, è necessario configurare l’applicazione per connettersi a un database e impostare le proprietà di JPA. Di seguito è riportato un esempio di configurazione utilizzando application.properties:
# Configurazione del Database
spring.datasource.url=jdbc:mysql://localhost:3306/nome_database
spring.datasource.username=tuo_username
spring.datasource.password=tuo_password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# Configurazione di JPA
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
Definizione delle Entità
Le entità sono classi Java annotate con @Entity che rappresentano le tabelle nel database. Ogni campo della classe corrisponde a una colonna della tabella.
Esempio: Definizione di un’Entità User
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Costruttori
public User() {}
public User(String name, String email) {
this.name = name;
this.email = email;
}
// Getter e Setter
public Long getId() {
return id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}Creazione di Repository con Spring Data JPA
Per interagire con il database, si definisce un’interfaccia repository che estende JpaRepository. Questa interfaccia fornisce metodi predefiniti per operazioni CRUD e la possibilità di definire query personalizzate.
Esempio: Definizione di UserRepository
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.Optional;
public interface UserRepository extends JpaRepository<User, Long> {
// Metodo di query personalizzato per trovare un utente per email
Optional<User> findByEmail(String email);
}In questo esempio, UserRepository estende JpaRepository, specificando User come tipo dell’entità e Long come tipo dell’identificatore. Spring Data JPA fornisce automaticamente implementazioni per i metodi CRUD di base. Inoltre, il metodo findByEmail è un esempio di metodo di query personalizzato basato sul naming convention, che consente di cercare un utente per email senza dover scrivere una query manuale.
Esempi Pratici di Operazioni CRUD
Creazione di un Nuovo Utente
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User createUser(String name, String email) {
User user = new User(name, email);
return userRepository.save(user);
}
}In questo esempio, il metodo createUser crea una nuova istanza di User e la salva nel database utilizzando il metodo save fornito da JpaRepository.
Lettura di Utenti dal Database
import java.util.List;
import java.util.Optional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getAllUsers() {
return userRepository.findAll();
}
public Optional<User> getUserByEmail(String email) {
return userRepository.findByEmail(email);
}
}Il metodo getAllUsers utilizza findAll per recuperare tutti gli utenti dal database. Il metodo getUserByEmail utilizza il metodo personalizzato findByEmail per cercare un utente specifico per email.
Aggiornamento di un Utente Esistente
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User updateUser(Long id, String newName, String newEmail) {
return userRepository.findById(id)
.map(user -> {
user.setName(newName);
user.setEmail(newEmail);
return userRepository.save(user);
})
.orElseThrow(() -> new ResourceNotFoundException("User not found with id " + id));
}
}Il metodo updateUser cerca un utente per id, aggiorna i suoi attributi e lo salva nuovamente nel database. Se l’utente non viene trovato, viene lanciata un’eccezione personalizzata.
Cancellazione di un Utente
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}Il metodo deleteUser elimina un utente dal database utilizzando il metodo deleteById fornito da JpaRepository.
Query Personalizzate con Spring Data JPA
Oltre ai metodi predefiniti, Spring Data JPA consente di definire query personalizzate in vari modi:
-
Basate sul Naming Convention: Come visto nell’esempio
findByEmail, dove il nome del metodo determina la query. -
JPQL (Java Persistence Query Language): Utilizzando l’annotazione
@Queryper definire query JPQL personalizzate. -
Query Nativo: Utilizzando l’annotazione
@Querycon l’attributonativeQuery=trueper definire query SQL native.
Esempio: Query Personalizzata con JPQL
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.name LIKE %:name%")
List<User> findByNameContaining(@Param("name") String name);
}In questo esempio, il metodo findByNameContaining utilizza una query JPQL per cercare utenti il cui nome contiene una determinata stringa.
Best Practices con Spring Data JPA
-
Utilizzare Interfacce per i Repository: Definire repository come interfacce anziché classi concrete facilita la manutenzione e il test del codice.
-
Evitare Query Nella Business Logic: Incapsulare le query nei repository per mantenere la separazione delle responsabilità.
-
Gestire le Transazioni in Modo Adeguato: Utilizzare l’annotazione
@Transactionalsui metodi di servizio per garantire la consistenza dei dati. -
Utilizzare DTO (Data Transfer Objects): Per evitare di esporre direttamente le entità, utilizzare DTO per trasferire i dati tra livelli diversi dell’applicazione.
-
Ottimizzare le Query: Evitare il caricamento eccessivo di dati utilizzando strategie di fetch appropriate (eager vs lazy) e limitando i risultati delle query.
Conclusione
Spring Data JPA è uno strumento potente e flessibile che semplifica notevolmente la gestione della persistenza dei dati nelle applicazioni Java. Fornendo un’astrazione di alto livello e una serie di funzionalità avanzate per la definizione di repository e query, consente agli sviluppatori di concentrarsi sulla logica di business, riducendo al contempo il rischio di errori e migliorando la manutenibilità del codice. Comprendere e utilizzare efficacemente Spring Data JPA è essenziale per lo sviluppo di applicazioni robuste e scalabili con Spring Boot.
Esempio Completo: Applicazione di Gestione Utenti
Per consolidare i concetti trattati, consideriamo un esempio completo di applicazione di gestione utenti utilizzando Spring Data JPA.
1. Definizione dell’Entità User
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Costruttori, Getter e Setter
}2. Definizione del Repository UserRepository
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.Optional;
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByEmail(String email);
}3. Implementazione del Servizio UserService
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Optional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public List<User> getAllUsers() {
return userRepository.findAll();
}
public Optional<User> getUserByEmail(String email) {
return userRepository.findByEmail(email);
}
@Transactional
public User createUser(String name, String email) {
User user = new User(name, email);
return userRepository.save(user);
}
@Transactional
public User updateUser(Long id, String newName, String newEmail) {
return userRepository.findById(id)
.map(user -> {
user.setName(newName);
user.setEmail(newEmail);
return userRepository.save(user);
})
.orElseThrow(() -> new ResourceNotFoundException("User not found with id " + id));
}
@Transactional
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
}4. Creazione del Controller UserController
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Optional;
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserService userService;
@GetMapping
public List<User> getAllUsers() {
return userService.getAllUsers();
}
@GetMapping("/email/{email}")
public ResponseEntity<User> getUserByEmail(@PathVariable String email) {
Optional<User> userOpt = userService.getUserByEmail(email);
return userOpt.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
@PostMapping
public User createUser(@RequestBody User user) {
return userService.createUser(user.getName(), user.getEmail());
}
@PutMapping("/{id}")
public ResponseEntity<User> updateUser(@PathVariable Long id, @RequestBody User userDetails) {
try {
User updatedUser = userService.updateUser(id, userDetails.getName(), userDetails.getEmail());
return ResponseEntity.ok(updatedUser);
} catch (ResourceNotFoundException ex) {
return ResponseEntity.notFound().build();
}
}
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteUser(@PathVariable Long id) {
userService.deleteUser(id);
return ResponseEntity.noContent().build();
}
}5. Esecuzione e Test dell’Applicazione
Avviando l’applicazione Spring Boot, si possono utilizzare strumenti come Postman o cURL per testare gli endpoint REST definiti nel controller UserController. Ad esempio:
-
Creare un Nuovo Utente
curl -X POST -H "Content-Type: application/json" -d '{"name":"Mario Rossi","email":"mario.rossi@example.com"}' http://localhost:8080/api/users -
Ottenere Tutti gli Utenti
curl http://localhost:8080/api/users -
Ottenere un Utente per Email
curl http://localhost:8080/api/users/email/mario.rossi@example.com -
Aggiornare un Utente
curl -X PUT -H "Content-Type: application/json" -d '{"name":"Mario Bianchi","email":"mario.bianchi@example.com"}' http://localhost:8080/api/users/1 -
Cancellare un Utente
curl -X DELETE http://localhost:8080/api/users/1
Conclusione
In questa sezione, abbiamo esplorato Spring Data JPA, un componente essenziale per la gestione della persistenza dei dati nelle applicazioni Spring Boot. Abbiamo visto come configurare l’ambiente, definire entità e repository, eseguire operazioni CRUD e creare query personalizzate. Inoltre, abbiamo illustrato un esempio completo di applicazione di gestione utenti per consolidare i concetti appresi. La padronanza di Spring Data JPA è cruciale per sviluppare applicazioni efficienti, scalabili e manutenibili, rendendola una competenza indispensabile per ogni sviluppatore Java.
14.2 Configurazione del Database
La configurazione del database è un passaggio cruciale nello sviluppo di applicazioni Spring Boot, in quanto determina come l’applicazione si connette e interagisce con il sistema di gestione di database relazionali (RDBMS). In questa sezione, esploreremo i passaggi fondamentali per configurare una connessione a un database relazionale utilizzando Hibernate come provider JPA all’interno di un’applicazione Spring Boot. Forniremo esempi pratici e discuteremo le ragioni dietro ciascuna configurazione per garantire una comprensione approfondita.
1. Scelta del Database Relazionale
Prima di procedere con la configurazione, è essenziale scegliere il database relazionale più adatto alle esigenze del progetto. Alcuni dei database relazionali più comuni includono:
-
MySQL: Popolare per la sua facilità d’uso e vasta comunità.
-
PostgreSQL: Conosciuto per la sua conformità agli standard e funzionalità avanzate.
-
Oracle Database: Utilizzato principalmente in contesti enterprise.
-
Microsoft SQL Server: Scelto spesso in ambienti Windows.
Per scopi didattici, utilizzeremo MySQL come esempio, ma i principi di configurazione sono applicabili ad altri RDBMS con lievi modifiche.
2. Aggiunta delle Dipendenze nel pom.xml
Per integrare Hibernate e MySQL in un progetto Spring Boot, è necessario aggiungere le dipendenze appropriate nel file pom.xml (per Maven) o build.gradle (per Gradle). Di seguito, un esempio di configurazione con Maven:
<dependencies>
<!-- Spring Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- Driver MySQL -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Altre dipendenze necessarie -->
</dependencies>Spiegazione:
-
spring-boot-starter-data-jpa: Fornisce le dipendenze necessarie per utilizzare Spring Data JPA e Hibernate.
-
mysql-connector-java: Il driver JDBC per MySQL, necessario per stabilire la connessione tra l’applicazione e il database.
3. Configurazione delle Proprietà del Database
Le proprietà di configurazione del database vengono solitamente definite nel file application.properties o application.yml situato nella cartella src/main/resources. Utilizzeremo application.properties per questo esempio.
# Configurazione del Datasource
spring.datasource.url=jdbc:mysql://localhost:3306/nome_database?useSSL=false&serverTimezone=UTC
spring.datasource.username=tuo_utente
spring.datasource.password=tuo_password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# Configurazione di Hibernate
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
Dettagli delle Proprietà:
-
spring.datasource.url: L’URL di connessione al database. Comprende il protocollo JDBC, il tipo di database (
mysql), l’host (localhost), la porta (3306), e il nome del database (nome_database). Le opzioni aggiuntive comeuseSSL=falseeserverTimezone=UTCaiutano a prevenire avvisi di sicurezza e problemi di fuso orario. -
spring.datasource.username & spring.datasource.password: Le credenziali per l’accesso al database. È buona pratica gestire queste informazioni in modo sicuro, utilizzando strumenti come Spring Cloud Config o variabili d’ambiente in ambienti di produzione.
-
spring.datasource.driver-class-name: Specifica la classe del driver JDBC da utilizzare. Per MySQL 8 e versioni successive, la classe è
com.mysql.cj.jdbc.Driver. -
spring.jpa.hibernate.ddl-auto: Determina come Hibernate gestisce la generazione dello schema del database. I valori comuni includono:
-
none: Non fare nulla. -
validate: Valida lo schema esistente. -
update: Aggiorna lo schema senza perdere i dati. -
create: Crea lo schema, eliminando i dati esistenti. -
create-drop: Crea lo schema all’avvio e lo elimina alla chiusura dell’applicazione.
Nota: In ambienti di produzione, è consigliabile utilizzare
validateo gestire lo schema manualmente per evitare perdite di dati. -
-
spring.jpa.show-sql: Se impostato su
true, Hibernate stamperà le query SQL generate nella console, utile per il debug e la comprensione delle operazioni effettuate. -
spring.jpa.properties.hibernate.dialect: Specifica il dialetto SQL utilizzato da Hibernate per generare query ottimizzate per il database scelto. Per MySQL 8, si utilizza
org.hibernate.dialect.MySQL8Dialect.
4. Configurazione Avanzata: Pool di Connessioni
Un aspetto importante nella configurazione del database è la gestione delle connessioni. Spring Boot utilizza HikariCP come pool di connessioni predefinito, noto per le sue alte prestazioni. Tuttavia, è possibile personalizzare le impostazioni del pool secondo le esigenze specifiche.
Esempio di configurazione avanzata nel application.properties:
# Configurazione di HikariCP
spring.datasource.hikari.maximum-pool-size=20
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariPool
spring.datasource.hikari.max-lifetime=1800000
spring.datasource.hikari.connection-timeout=30000
Descrizione delle Proprietà:
-
maximum-pool-size: Numero massimo di connessioni nel pool.
-
minimum-idle: Numero minimo di connessioni inattive mantenute nel pool.
-
idle-timeout: Tempo in millisecondi prima che una connessione inattiva venga chiusa.
-
pool-name: Nome del pool di connessioni, utile per il monitoraggio.
-
max-lifetime: Tempo massimo in millisecondi che una connessione può rimanere nel pool.
-
connection-timeout: Tempo massimo in millisecondi che l’applicazione attenderà per ottenere una connessione dal pool.
Considerazioni:
-
Performance: Configurare correttamente il pool di connessioni può migliorare significativamente le prestazioni dell’applicazione, soprattutto in scenari ad alto carico.
-
Sicurezza e Stabilità: Impostazioni inappropriate possono portare a esaurimento delle connessioni o a ritardi nelle risposte. È fondamentale testare e monitorare le impostazioni in ambienti di staging prima del deployment in produzione.
5. Definizione delle Entità e Repository
Una volta configurato il database, è possibile definire le entità JPA che rappresentano le tabelle del database e i repository per operazioni CRUD.
Esempio di Entità:
package com.example.demo.model;
import jakarta.persistence.*;
@Entity
@Table(name = "utenti")
public class Utente {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true)
private String username;
@Column(nullable = false)
private String password;
// Costruttori, getter e setter
public Utente() {}
public Utente(String username, String password) {
this.username = username;
this.password = password;
}
// Getters e Setters
}Spiegazione:
-
@Entity: Indica che la classe è un’entità JPA.
-
@Table(name = “utenti”): Specifica il nome della tabella nel database.
-
@Id & @GeneratedValue: Definiscono la chiave primaria e la strategia di generazione automatica degli ID.
-
@Column: Specifica le proprietà delle colonne, come
nullableeunique.
Esempio di Repository:
package com.example.demo.repository;
import com.example.demo.model.Utente;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.Optional;
public interface UtenteRepository extends JpaRepository<Utente, Long> {
Optional<Utente> findByUsername(String username);
}Descrizione:
-
JpaRepository: Fornisce metodi CRUD predefiniti e funzionalità di paging e ordinamento.
-
findByUsername: Metodo di query derivato per trovare un utente per username.
6. Test della Configurazione
Per verificare che la configurazione del database sia corretta, possiamo creare un semplice componente che interagisce con il repository.
Esempio di Componente di Test:
package com.example.demo;
import com.example.demo.model.Utente;
import com.example.demo.repository.UtenteRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class DatabaseTestRunner implements CommandLineRunner {
@Autowired
private UtenteRepository utenteRepository;
@Override
public void run(String... args) throws Exception {
// Creazione di un nuovo utente
Utente utente = new Utente("admin", "password123");
utenteRepository.save(utente);
System.out.println("Utente salvato: " + utente);
// Recupero dell'utente
utenteRepository.findByUsername("admin").ifPresent(u -> {
System.out.println("Utente trovato: " + u);
});
}
}Spiegazione:
-
CommandLineRunner: Un’interfaccia che permette di eseguire codice al momento dell’avvio dell’applicazione.
-
DatabaseTestRunner: Componente che crea e recupera un utente dal database, verificando così la corretta configurazione.
Esecuzione:
Avviando l’applicazione Spring Boot, dovremmo vedere nella console i messaggi di log relativi al salvataggio e al recupero dell’utente, confermando che la connessione al database funziona correttamente.
7. Best Practices nella Configurazione del Database
Per garantire una configurazione efficace e sicura del database, è consigliabile seguire alcune best practices:
-
Gestione Sicura delle Credenziali:
- Evitare di hardcodare le credenziali nel
application.properties. Utilizzare variabili d’ambiente o strumenti di gestione delle configurazioni sicure.
- Evitare di hardcodare le credenziali nel
-
Utilizzo di Profili Spring:
- Definire configurazioni diverse per ambienti di sviluppo, testing e produzione utilizzando i profili Spring (
application-dev.properties,application-prod.properties, ecc.).
- Definire configurazioni diverse per ambienti di sviluppo, testing e produzione utilizzando i profili Spring (
-
Ottimizzazione del Pool di Connessioni:
- Configurare il pool di connessioni in base al carico previsto e monitorare le prestazioni per evitare problemi di scalabilità.
-
Gestione delle Migrazioni del Database:
- Utilizzare strumenti come Flyway o Liquibase per gestire le migrazioni dello schema del database in modo controllato e tracciabile.
Esempio di Configurazione con Flyway:
Aggiungere la dipendenza nel pom.xml:
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-core</artifactId>
</dependency>Creare script di migrazione in src/main/resources/db/migration con nomi come V1__Creazione_tabella_utenti.sql:
CREATE TABLE utenti (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL UNIQUE,
password VARCHAR(100) NOT NULL
);Vantaggi:
-
Versionamento dello Schema: Ogni migrazione è versionata, facilitando il tracking delle modifiche.
-
Automazione: Flyway applica automaticamente le migrazioni all’avvio dell’applicazione.
-
Collaborazione: Consente a più sviluppatori di lavorare sullo stesso schema senza conflitti.
8. Considerazioni Finali
La corretta configurazione del database è fondamentale per lo sviluppo di applicazioni robuste e scalabili con Spring Boot e Hibernate. Comprendere le proprietà di configurazione, le best practices e gli strumenti di gestione delle migrazioni permette di creare applicazioni che non solo funzionano efficacemente ma sono anche facili da mantenere e aggiornare nel tempo.
In sintesi, i passaggi principali per configurare il database in un’applicazione Spring Boot sono:
-
Aggiungere le dipendenze necessarie.
-
Definire le proprietà di connessione nel file di configurazione.
-
Personalizzare il pool di connessioni per ottimizzare le prestazioni.
-
Definire entità e repository per l’interazione con il database.
-
Implementare best practices per garantire sicurezza e manutenibilità.
Seguendo queste linee guida, sarai in grado di configurare efficacemente il database per le tue applicazioni Spring Boot, assicurando una base solida per ulteriori sviluppi e integrazioni.
14.3 Transazioni e Gestione delle Transazioni
Introduzione alle Transazioni
Nel contesto delle applicazioni che interagiscono con un database, una transazione rappresenta un’unità logica di lavoro che deve essere completata integralmente o, in caso contrario, annullata completamente. Le transazioni sono fondamentali per garantire l’integrità e la coerenza dei dati, soprattutto in scenari in cui operazioni multiple devono essere eseguite in sequenza.
Principi Fondamentali delle Transazioni (ACID)
Le transazioni seguono il modello ACID, un insieme di proprietà che garantiscono la correttezza e l’affidabilità delle operazioni sui dati:
-
Atomicità (Atomicity): La transazione deve essere trattata come un’unica unità indivisibile. O tutte le operazioni all’interno della transazione vengono completate con successo, oppure nessuna viene applicata.
-
Consistenza (Consistency): Le transazioni devono portare il database da uno stato consistente a un altro stato consistente, rispettando tutte le regole di integrità e i vincoli definiti.
-
Isolamento (Isolation): Le transazioni concorrenti devono essere isolate l’una dall’altra, evitando interferenze e garantendo che l’esecuzione parallela non comprometta la coerenza dei dati.
-
Durabilità (Durability): Una volta che una transazione è stata confermata (commit), i suoi effetti sono permanenti e devono sopravvivere a eventuali guasti del sistema.
Gestione delle Transazioni in Spring Boot
Spring Boot, grazie al modulo Spring Framework, fornisce un supporto robusto per la gestione delle transazioni, semplificando notevolmente l’implementazione e il controllo delle transazioni nelle applicazioni.
Utilizzo dell’Annotazione @Transactional
L’annotazione @Transactional è il principale strumento offerto da Spring per gestire le transazioni. Può essere applicata a classi o metodi per definire i confini transazionali.
Esempio di Utilizzo:
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class OrdineService {
private final OrdineRepository ordineRepository;
private final InventarioRepository inventarioRepository;
public OrdineService(OrdineRepository ordineRepository, InventarioRepository inventarioRepository) {
this.ordineRepository = ordineRepository;
this.inventarioRepository = inventarioRepository;
}
@Transactional
public void creaOrdine(Ordine ordine) {
ordineRepository.save(ordine);
inventarioRepository.decrementaStock(ordine.getProdottoId(), ordine.getQuantita());
// Altre operazioni che devono essere atomiche
}
}In questo esempio, il metodo creaOrdine è annotato con @Transactional, indicando che tutte le operazioni all’interno del metodo devono essere eseguite all’interno di una singola transazione. Se una delle operazioni fallisce (ad esempio, se decrementaStock lancia un’eccezione), l’intera transazione viene annullata, ripristinando il database al suo stato precedente.
Configurazione delle Transazioni
Spring gestisce automaticamente le transazioni grazie alla configurazione basata sulle annotazioni. Tuttavia, è possibile personalizzare il comportamento delle transazioni utilizzando attributi dell’annotazione @Transactional, come:
-
propagation: Definisce come le transazioni si propagano nei metodi annidati. -
isolation: Specifica il livello di isolamento della transazione. -
timeout: Imposta un limite di tempo per la transazione. -
readOnly: Indica se la transazione è solo di lettura, ottimizzando le operazioni di accesso ai dati.
Esempio di Configurazione Avanzata:
@Transactional(propagation = Propagation.REQUIRED, isolation = Isolation.SERIALIZABLE, timeout = 30, readOnly = false)
public void aggiornaOrdine(Ordine ordine) {
// Implementazione del metodo
}Gestione delle Eccezioni nelle Transazioni
Per garantire che le transazioni siano gestite correttamente, è essenziale comprendere come Spring tratta le eccezioni. Per impostazione predefinita, Spring effettua il rollback della transazione solo quando viene lanciata un’eccezione non controllata (ad esempio, una sottoclasse di RuntimeException) o un errore (Error). Le eccezioni controllate (checked exceptions) non causano il rollback a meno che non siano specificate esplicitamente.
Esempio: Rollback su Eccezioni Controllate
@Transactional(rollbackFor = {SQLException.class, IOException.class})
public void metodoConEccezioniControllate() throws SQLException, IOException {
// Implementazione del metodo
}In questo caso, se viene lanciata una SQLException o una IOException, la transazione verrà annullata.
Best Practices nella Gestione delle Transazioni
-
Definire i Confini delle Transazioni in Modo Chiaro:
-
Annotare i metodi di servizio (
Service) che rappresentano unità logiche di lavoro. -
Evitare di annotare i metodi del repository (
Repository), lasciando che i servizi gestiscano le transazioni.
-
-
Minimizzare la Durata delle Transazioni:
- Tenere aperte le transazioni per il minor tempo possibile per ridurre il rischio di deadlock e migliorare la scalabilità.
-
Evitare Operazioni Lente all’Interno delle Transazioni:
- Evitare operazioni come l’accesso a file di grandi dimensioni o chiamate a servizi esterni all’interno di una transazione.
-
Gestire le Eccezioni in Modo Adeguato:
- Catturare e gestire le eccezioni in modo da non mascherare errori critici che richiedono il rollback della transazione.
-
Utilizzare Livelli di Isolamento Appropriati:
- Scegliere il livello di isolamento più basso che soddisfa i requisiti di coerenza per migliorare le prestazioni.
-
Testare le Transazioni:
- Implementare test unitari e di integrazione per verificare il comportamento delle transazioni in scenari diversi, inclusi i casi di errore.
Esempio Completo: Gestione delle Transazioni in un’Applicazione Spring Boot
Consideriamo un’applicazione di gestione degli ordini che deve registrare un nuovo ordine e aggiornare lo stock dell’inventario.
Entity Ordine:
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Ordine {
@Id
private Long id;
private Long prodottoId;
private int quantita;
// Getters e Setters
}Repository OrdineRepository:
import org.springframework.data.jpa.repository.JpaRepository;
public interface OrdineRepository extends JpaRepository<Ordine, Long> {
}Repository InventarioRepository:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.transaction.annotation.Transactional;
public interface InventarioRepository extends JpaRepository<Inventario, Long> {
@Modifying
@Transactional
@Query("UPDATE Inventario i SET i.stock = i.stock - :quantita WHERE i.prodottoId = :prodottoId")
void decrementaStock(Long prodottoId, int quantita);
}Service OrdineService:
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class OrdineService {
private final OrdineRepository ordineRepository;
private final InventarioRepository inventarioRepository;
public OrdineService(OrdineRepository ordineRepository, InventarioRepository inventarioRepository) {
this.ordineRepository = ordineRepository;
this.inventarioRepository = inventarioRepository;
}
@Transactional
public void creaOrdine(Ordine ordine) {
ordineRepository.save(ordine);
inventarioRepository.decrementaStock(ordine.getProdottoId(), ordine.getQuantita());
// Altre operazioni che devono essere atomiche
}
}Controller OrdineController:
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/ordini")
public class OrdineController {
private final OrdineService ordineService;
public OrdineController(OrdineService ordineService) {
this.ordineService = ordineService;
}
@PostMapping
public ResponseEntity<String> creaOrdine(@RequestBody Ordine ordine) {
try {
ordineService.creaOrdine(ordine);
return new ResponseEntity<>("Ordine creato con successo", HttpStatus.CREATED);
} catch (Exception e) {
return new ResponseEntity<>("Errore nella creazione dell'ordine", HttpStatus.INTERNAL_SERVER_ERROR);
}
}
}Spiegazione del Flusso:
-
Creazione dell’Ordine:
- Quando viene effettuata una richiesta POST a
/ordinicon i dettagli dell’ordine, ilOrdineControllerinvoca il metodocreaOrdinedelOrdineService.
- Quando viene effettuata una richiesta POST a
-
Gestione Transazionale:
- Il metodo
creaOrdineè annotato con@Transactional, garantendo che le operazioni di salvataggio dell’ordine e l’aggiornamento dello stock siano eseguite all’interno della stessa transazione.
- Il metodo
-
Persistenza e Aggiornamento:
-
ordineRepository.save(ordine)salva l’ordine nel database. -
inventarioRepository.decrementaStock(...)aggiorna lo stock dell’inventario.
-
-
Rollback in Caso di Errore:
- Se una delle operazioni fallisce (ad esempio, se lo stock non è sufficiente), viene lanciata un’eccezione che provoca il rollback della transazione, garantendo che nessuna delle operazioni venga applicata.
Conclusioni
La gestione delle transazioni è un aspetto cruciale nello sviluppo di applicazioni robuste e affidabili. Spring Boot, attraverso il supporto di Spring Framework, offre strumenti potenti e flessibili per gestire le transazioni in modo semplice ed efficace. Comprendere come utilizzare correttamente l’annotazione @Transactional e seguire le best practices nella gestione delle transazioni permette di garantire l’integrità dei dati e la coerenza delle operazioni nelle proprie applicazioni.
Capitolo 15: Sicurezza nelle Applicazioni Spring Boot
15.1 Introduzione a Spring Security
Cos’è Spring Security?
Spring Security è un framework altamente personalizzabile che fornisce servizi di sicurezza completi per applicazioni Java, in particolare quelle sviluppate con il framework Spring. Si occupa di vari aspetti della sicurezza applicativa, tra cui autenticazione, autorizzazione, protezione contro attacchi comuni (come CSRF, XSS, etc.), gestione delle sessioni e molto altro. Grazie alla sua integrazione stretta con l’ecosistema Spring, Spring Security permette di implementare soluzioni di sicurezza robuste e flessibili con un impatto minimo sulla struttura dell’applicazione.
Perché Utilizzare Spring Security?
-
Integrazione Semplificata: Spring Security si integra perfettamente con altri componenti di Spring, come Spring MVC e Spring Boot, facilitando l’implementazione di misure di sicurezza senza dover ricorrere a configurazioni complesse o framework esterni.
-
Flessibilità e Personalizzazione: Il framework è progettato per essere altamente configurabile, permettendo agli sviluppatori di adattare le funzionalità di sicurezza alle specifiche esigenze dell’applicazione.
-
Supporto per Standard di Sicurezza: Spring Security supporta i principali standard di sicurezza, inclusi OAuth2, JWT (JSON Web Token), e OpenID Connect, rendendo più semplice l’implementazione di soluzioni moderne di autenticazione e autorizzazione.
-
Protezione Contro Attacchi Comuni: Fornisce meccanismi integrati per difendere l’applicazione da vulnerabilità comuni come Cross-Site Request Forgery (CSRF), Cross-Site Scripting (XSS), e attacchi di session hijacking.
Concetti Fondamentali di Spring Security
-
Autenticazione: Processo di verifica dell’identità di un utente. Spring Security supporta diverse modalità di autenticazione, tra cui autenticazione basata su form, HTTP Basic, OAuth2, e autenticazione personalizzata.
-
Autorizzazione: Definisce i permessi e i privilegi degli utenti autenticati. Consente di controllare l’accesso a risorse specifiche all’interno dell’applicazione in base ai ruoli o alle autorità assegnate agli utenti.
-
Filtri di Sicurezza: Spring Security utilizza una catena di filtri per gestire le richieste in entrata, applicando le regole di sicurezza definite. Questi filtri possono essere personalizzati per aggiungere o modificare il comportamento predefinito.
-
Gestione delle Sessioni: Consente di controllare il comportamento delle sessioni utente, inclusa la gestione delle sessioni concorrenti, la scadenza delle sessioni e la protezione contro gli attacchi di session fixation.
Configurazione Standard di Spring Security
L’implementazione di Spring Security in un’applicazione Spring Boot è resa semplice grazie alla sua configurazione automatica. Tuttavia, è spesso necessario personalizzare la configurazione per soddisfare requisiti specifici. Di seguito, viene presentata una configurazione di base che illustra i concetti fondamentali.
1. Aggiunta delle Dipendenze
Per iniziare, è necessario aggiungere la dipendenza di Spring Security al progetto. Se si utilizza Maven, si aggiunge la seguente dipendenza nel file pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>Per Gradle, si aggiunge nel file build.gradle:
implementation 'org.springframework.boot:spring-boot-starter-security'
2. Configurazione di Base
Spring Boot configura automaticamente Spring Security con impostazioni predefinite quando la dipendenza è presente. Queste impostazioni includono:
-
Autenticazione Basata su Form: Spring Security fornisce una pagina di login predefinita.
-
Autorizzazione Globale: Tutti gli endpoint sono protetti e richiedono autenticazione.
-
Creazione di un Utente di Default: Un utente con username
usere una password generata automaticamente viene creato al momento dell’avvio.
3. Personalizzazione della Configurazione di Sicurezza
Per personalizzare la configurazione, è necessario creare una classe di configurazione che estende WebSecurityConfigurerAdapter (fino a Spring Security 5.7) o utilizzare il nuovo approccio basato su componenti (SecurityFilterChain) a partire da Spring Security 5.7 e successivi.
Esempio con WebSecurityConfigurerAdapter:
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/public/**").permitAll() // Permetti accesso a endpoint pubblici
.anyRequest().authenticated() // Richiedi autenticazione per tutte le altre richieste
.and()
.formLogin()
.loginPage("/login") // Pagina di login personalizzata
.permitAll()
.and()
.logout()
.permitAll();
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.inMemoryAuthentication()
.withUser("admin").password("{noop}password").roles("ADMIN") // Utente in memoria
.and()
.withUser("user").password("{noop}password").roles("USER");
}
}Spiegazione del Codice:
-
authorizeRequests(): Definisce le regole di autorizzazione per le richieste HTTP.
-
antMatchers("/public/**").permitAll(): Permette l’accesso a tutte le risorse sotto/public/senza autenticazione. -
anyRequest().authenticated(): Richiede l’autenticazione per tutte le altre richieste.
-
-
formLogin(): Configura la pagina di login.
-
loginPage("/login"): Specifica una pagina di login personalizzata. -
permitAll(): Permette a tutti di accedere alla pagina di login.
-
-
logout(): Configura la funzionalità di logout.
permitAll(): Permette a tutti di accedere alla funzionalità di logout.
-
configure(AuthenticationManagerBuilder auth): Configura i dettagli dell’autenticazione.
-
inMemoryAuthentication(): Configura utenti in memoria per scopi di testing o dimostrativi. -
withUser("admin").password("{noop}password").roles("ADMIN"): Crea un utenteadmincon passwordpassworde ruoloADMIN. -
{noop}: Indica che la password non è crittografata. Nota: In produzione, le password devono essere crittografate utilizzando un encoder appropriato.
-
4. Creazione di una Pagina di Login Personalizzata
Per creare una pagina di login personalizzata, è necessario definire un controller e la relativa vista.
Controller:
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class LoginController {
@GetMapping("/login")
public String login() {
return "login"; // Nome della vista (es. login.html)
}
}Vista (login.html):
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Login</title>
</head>
<body>
<h1>Login</h1>
<form th:action="@{/login}" method="post">
<div>
<label>Username:</label>
<input type="text" name="username"/>
</div>
<div>
<label>Password:</label>
<input type="password" name="password"/>
</div>
<div>
<button type="submit">Accedi</button>
</div>
</form>
</body>
</html>5. Protezione contro CSRF
Cross-Site Request Forgery (CSRF) è un tipo di attacco che forza un utente autenticato a eseguire azioni indesiderate su un’applicazione web in cui è autenticato. Spring Security fornisce una protezione automatica contro CSRF.
Configurazione Predefinita:
La protezione CSRF è abilitata per impostazione predefinita. Per confermare o personalizzare questa configurazione, si può modificare la classe di configurazione di sicurezza:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.csrf()
.csrfTokenRepository(CookieCsrfTokenRepository.withHttpOnlyFalse()) // Configurazione personalizzata
.and()
.authorizeRequests()
.antMatchers("/public/**").permitAll()
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.permitAll()
.and()
.logout()
.permitAll();
}Note Importanti:
-
Quando si utilizzano form personalizzati, è necessario includere il token CSRF nel modulo per garantire che le richieste POST siano legittime.
-
Nei client RESTful, spesso si disabilita la protezione CSRF poiché non si utilizzano sessioni tradizionali. In questi casi, è consigliabile utilizzare metodi di autenticazione stateless come JWT.
6. Gestione delle Password
La gestione sicura delle password è cruciale per la protezione delle applicazioni. Spring Security supporta vari encoder di password per garantire che le password siano archiviate in modo sicuro.
Esempio di Configurazione con BCrypt:
import org.springframework.context.annotation.Bean;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
// Altri metodi di configurazione...
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.inMemoryAuthentication()
.withUser("admin")
.password(passwordEncoder().encode("password"))
.roles("ADMIN")
.and()
.withUser("user")
.password(passwordEncoder().encode("password"))
.roles("USER");
}
}Spiegazione:
-
BCryptPasswordEncoder: Utilizza l’algoritmo BCrypt per crittografare le password, fornendo una robusta protezione contro attacchi di forza bruta.
-
passwordEncoder().encode(“password”): Codifica la password prima di salvarla nella configurazione in memoria. In un contesto reale, le password dovrebbero essere archiviate in un database crittografato.
7. Autorizzazione Basata sui Ruoli
Spring Security permette di definire l’accesso alle risorse basato sui ruoli assegnati agli utenti.
Esempio di Configurazione:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN") // Accesso solo per ADMIN
.antMatchers("/user/**").hasAnyRole("USER", "ADMIN") // Accesso per USER e ADMIN
.antMatchers("/public/**").permitAll() // Accesso pubblico
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.permitAll()
.and()
.logout()
.permitAll();
}Spiegazione:
-
hasRole(“ADMIN”): Permette l’accesso solo agli utenti con ruolo
ADMIN. -
hasAnyRole(“USER”, “ADMIN”): Permette l’accesso agli utenti con ruolo
USERoADMIN. -
permitAll(): Permette l’accesso a tutti senza autenticazione.
8. Best Practices nella Configurazione di Spring Security
-
Utilizzare Password Encoder Sicuri: Evitare di utilizzare
{noop}in produzione. Utilizzare encoder robusti comeBCryptPasswordEncoder. -
Principio del Minimo Privilegio: Assegnare agli utenti solo i ruoli e i permessi necessari per svolgere le loro funzioni.
-
Proteggere le API RESTful: Utilizzare meccanismi di autenticazione stateless come JWT e assicurarsi di proteggere gli endpoint appropriati.
-
Gestione Sicura delle Sessioni: Configurare le sessioni in modo da prevenire attacchi di session fixation e session hijacking. Ad esempio, invalidare la sessione all’uscita.
-
Monitoraggio e Logging: Abilitare il logging delle attività di sicurezza per rilevare e rispondere tempestivamente a potenziali minacce.
-
Aggiornamenti Costanti: Mantenere aggiornate le dipendenze di Spring Security per beneficiare delle ultime patch di sicurezza e miglioramenti.
Esempio Pratico Completo
Di seguito, un esempio completo di configurazione di Spring Security che implementa autenticazione e autorizzazione basate su ruoli, utilizza BCrypt per l’encoding delle password e definisce una pagina di login personalizzata.
Classe di Configurazione:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.csrf().disable() // Disabilita CSRF per semplicità (non consigliato in produzione)
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/user/**").hasAnyRole("USER", "ADMIN")
.antMatchers("/public/**").permitAll()
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.defaultSuccessUrl("/home", true)
.permitAll()
.and()
.logout()
.logoutSuccessUrl("/login?logout")
.permitAll();
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.inMemoryAuthentication()
.withUser("admin")
.password(passwordEncoder().encode("adminpass"))
.roles("ADMIN")
.and()
.withUser("user")
.password(passwordEncoder().encode("userpass"))
.roles("USER");
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}Controller per le Pagine:
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class HomeController {
@GetMapping("/login")
public String login() {
return "login"; // Vista login.html
}
@GetMapping("/home")
public String home() {
return "home"; // Vista home.html
}
@GetMapping("/admin/dashboard")
public String adminDashboard() {
return "adminDashboard"; // Vista adminDashboard.html
}
@GetMapping("/user/profile")
public String userProfile() {
return "userProfile"; // Vista userProfile.html
}
@GetMapping("/public/info")
public String publicInfo() {
return "publicInfo"; // Vista publicInfo.html
}
}Struttura delle Viste (Esempio con Thymeleaf):
- login.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Login</title>
</head>
<body>
<h1>Login</h1>
<form th:action="@{/login}" method="post">
<div>
<label>Username:</label>
<input type="text" name="username"/>
</div>
<div>
<label>Password:</label>
<input type="password" name="password"/>
</div>
<div>
<button type="submit">Accedi</button>
</div>
</form>
<div th:if="${param.error}">
<p>Credenziali non valide. Riprova.</p>
</div>
<div th:if="${param.logout}">
<p>Hai effettuato il logout con successo.</p>
</div>
</body>
</html>- home.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Home</title>
</head>
<body>
<h1>Benvenuto nella Home Page!</h1>
<a th:href="@{/logout}">Logout</a>
</body>
</html>- adminDashboard.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Admin Dashboard</title>
</head>
<body>
<h1>Dashboard Amministratore</h1>
<a th:href="@{/logout}">Logout</a>
</body>
</html>- userProfile.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>User Profile</title>
</head>
<body>
<h1>Profilo Utente</h1>
<a th:href="@{/logout}">Logout</a>
</body>
</html>- publicInfo.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Informazioni Pubbliche</title>
</head>
<body>
<h1>Questa è una pagina pubblica accessibile a tutti.</h1>
<a th:href="@{/login}">Login</a>
</body>
</html>Conclusioni
Spring Security rappresenta uno strumento potente e flessibile per implementare la sicurezza nelle applicazioni Java basate su Spring. La sua integrazione con Spring Boot semplifica notevolmente la configurazione iniziale, mentre la sua architettura modulare permette una personalizzazione avanzata per soddisfare esigenze specifiche. Comprendere i concetti di base e le configurazioni standard è fondamentale per costruire applicazioni sicure e resilienti, oltre a prepararsi efficacemente per colloqui tecnici focalizzati sulla sicurezza delle applicazioni.
15.2 Autenticazione e Autorizzazione
La sicurezza è un aspetto cruciale nello sviluppo di applicazioni web moderne. In Spring Boot, Spring Security è il framework di riferimento per implementare meccanismi di autenticazione e autorizzazione. Questa sezione esplorerà i concetti fondamentali di autenticazione e autorizzazione, illustrando come configurarli e gestirli efficacemente in un’applicazione Spring Boot.
15.2.1 Concetti di Base
Autenticazione vs. Autorizzazione
-
Autenticazione: Processo mediante il quale un sistema verifica l’identità di un utente. In altre parole, conferma che l’utente è chi dichiara di essere.
-
Autorizzazione: Processo che determina se un utente autenticato ha i permessi necessari per accedere a determinate risorse o eseguire specifiche azioni all’interno dell’applicazione.
15.2.2 Configurazione di Spring Security
Per integrare Spring Security in un progetto Spring Boot, è necessario aggiungere la dipendenza nel file pom.xml (per progetti Maven) o build.gradle (per progetti Gradle).
Esempio con Maven:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>15.2.3 Configurazione di Base per l’Autenticazione
Spring Security fornisce una configurazione di sicurezza predefinita che protegge tutte le richieste HTTP richiedendo l’autenticazione. Per personalizzare questa configurazione, è possibile estendere la classe WebSecurityConfigurerAdapter (nota: a partire da Spring Security 5.7, si consiglia di utilizzare la configurazione basata su componenti).
Esempio di Configurazione di Sicurezza:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.security.core.userdetails.User;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.provisioning.InMemoryUserDetailsManager;
@Configuration
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authorize -> authorize
.antMatchers("/public/**").permitAll() // Permette l'accesso senza autenticazione
.anyRequest().authenticated() // Richiede autenticazione per tutte le altre richieste
)
.formLogin(form -> form
.loginPage("/login") // Pagina di login personalizzata
.permitAll()
)
.logout(logout -> logout.permitAll());
return http.build();
}
@Bean
public InMemoryUserDetailsManager userDetailsService() {
UserDetails user = User.withDefaultPasswordEncoder()
.username("utente")
.password("password")
.roles("USER")
.build();
UserDetails admin = User.withDefaultPasswordEncoder()
.username("admin")
.password("admin")
.roles("ADMIN")
.build();
return new InMemoryUserDetailsManager(user, admin);
}
}Spiegazione:
-
SecurityFilterChain: Configura le regole di sicurezza HTTP.
-
Le richieste che corrispondono a
/public/**sono accessibili a tutti senza autenticazione. -
Tutte le altre richieste richiedono l’autenticazione.
-
Configura una pagina di login personalizzata (
/login). -
Abilita la funzionalità di logout.
-
-
InMemoryUserDetailsManager: Gestisce gli utenti in memoria. In un’applicazione reale, gli utenti sarebbero probabilmente memorizzati in un database.
15.2.4 Gestione dei Ruoli e delle Autorizzazioni
I ruoli determinano i permessi assegnati agli utenti. È possibile definire ruoli come USER, ADMIN, ecc., e configurare le autorizzazioni in base a questi ruoli.
Esempio di Autorizzazione Basata sui Ruoli:
http
.authorizeHttpRequests(authorize -> authorize
.antMatchers("/admin/**").hasRole("ADMIN") // Accesso solo per ADMIN
.antMatchers("/user/**").hasAnyRole("USER", "ADMIN") // Accesso per USER e ADMIN
.antMatchers("/public/**").permitAll()
.anyRequest().authenticated()
)Protezione di Endpoint Specifici:
Supponiamo di avere due endpoint: /admin/dashboard e /user/profile. Vogliamo che solo gli utenti con il ruolo ADMIN possano accedere al dashboard, mentre il profilo utente può essere accessibile sia da USER che da ADMIN.
Controller Esempio:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.security.access.prepost.PreAuthorize;
@RestController
public class MyController {
@GetMapping("/admin/dashboard")
@PreAuthorize("hasRole('ADMIN')")
public String adminDashboard() {
return "Benvenuto nel Dashboard Admin!";
}
@GetMapping("/user/profile")
@PreAuthorize("hasAnyRole('USER', 'ADMIN')")
public String userProfile() {
return "Ecco il tuo profilo utente.";
}
@GetMapping("/public/info")
public String publicInfo() {
return "Informazioni pubbliche accessibili a tutti.";
}
}Spiegazione:
-
@PreAuthorize: Annotation che permette di definire espressioni di sicurezza per autorizzare l’accesso ai metodi.
-
hasRole('ADMIN'): L’utente deve avere il ruoloADMIN. -
hasAnyRole('USER', 'ADMIN'): L’utente deve avere almeno uno dei ruoli specificati.
-
15.2.5 Implementazione di una Pagina di Login Personalizzata
Per migliorare l’esperienza utente, è possibile creare una pagina di login personalizzata anziché utilizzare quella predefinita di Spring Security.
Esempio di Controller per la Pagina di Login:
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class LoginController {
@GetMapping("/login")
public String login() {
return "login"; // Nome del template HTML della pagina di login
}
}Esempio di Template Thymeleaf per il Login (login.html):
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Login</title>
</head>
<body>
<h2>Accedi alla tua area</h2>
<form th:action="@{/login}" method="post">
<div>
<label>Username:</label>
<input type="text" name="username"/>
</div>
<div>
<label>Password:</label>
<input type="password" name="password"/>
</div>
<div>
<button type="submit">Login</button>
</div>
</form>
</body>
</html>15.2.6 Autorizzazione a Livello di Metodi
Oltre alla configurazione delle autorizzazioni a livello di HTTP, è possibile definire autorizzazioni a livello di metodo utilizzando annotazioni come @PreAuthorize o @Secured.
Abilitazione del Supporto per le Annotations di Sicurezza:
Aggiungere @EnableGlobalMethodSecurity nella classe di configurazione di sicurezza.
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfig {
// Configurazione precedente
}Esempio di Uso di @Secured:
import org.springframework.security.access.annotation.Secured;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class SecureController {
@GetMapping("/secure/data")
@Secured("ROLE_USER")
public String secureData() {
return "Dati sicuri accessibili solo agli utenti autenticati con ruolo USER.";
}
}15.2.7 Autenticazione Basata su Form e OAuth2
Spring Security supporta diversi metodi di autenticazione, tra cui l’autenticazione basata su form e OAuth2. In questa sezione, verrà illustrata l’implementazione di un’autenticazione basata su form, mentre l’autenticazione OAuth2 sarà trattata nella sezione successiva (15.2.3).
15.2.8 Esempio Completo: Implementazione di Autenticazione e Autorizzazione
Consideriamo un’applicazione che gestisce un blog con funzionalità per utenti e amministratori.
Struttura del Progetto:
src
├── main
│ ├── java
│ │ └── com.example.blog
│ │ ├── BlogApplication.java
│ │ ├── config
│ │ │ └── SecurityConfig.java
│ │ ├── controller
│ │ │ ├── LoginController.java
│ │ │ ├── AdminController.java
│ │ │ └── UserController.java
│ │ └── model
│ │ └── User.java
│ └── resources
│ ├── templates
│ │ └── login.html
│ └── application.properties
1. Classe di Avvio (BlogApplication.java):
package com.example.blog;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BlogApplication {
public static void main(String[] args) {
SpringApplication.run(BlogApplication.class, args);
}
}2. Configurazione di Sicurezza (SecurityConfig.java):
package com.example.blog.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.security.core.userdetails.User;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.provisioning.InMemoryUserDetailsManager;
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authorize -> authorize
.antMatchers("/public/**", "/login").permitAll()
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/user/**").hasAnyRole("USER", "ADMIN")
.anyRequest().authenticated()
)
.formLogin(form -> form
.loginPage("/login")
.defaultSuccessUrl("/user/profile", true)
.permitAll()
)
.logout(logout -> logout
.logoutSuccessUrl("/login?logout")
.permitAll()
);
return http.build();
}
@Bean
public InMemoryUserDetailsManager userDetailsService() {
UserDetails user = User.withDefaultPasswordEncoder()
.username("user")
.password("password")
.roles("USER")
.build();
UserDetails admin = User.withDefaultPasswordEncoder()
.username("admin")
.password("admin")
.roles("ADMIN")
.build();
return new InMemoryUserDetailsManager(user, admin);
}
}3. Controller per la Pagina di Login (LoginController.java):
package com.example.blog.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class LoginController {
@GetMapping("/login")
public String login() {
return "login";
}
}4. Controller per le Funzionalità Admin (AdminController.java):
package com.example.blog.controller;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class AdminController {
@GetMapping("/admin/dashboard")
@PreAuthorize("hasRole('ADMIN')")
public String adminDashboard() {
return "Benvenuto nel pannello di amministrazione!";
}
}5. Controller per le Funzionalità Utente (UserController.java):
package com.example.blog.controller;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@GetMapping("/user/profile")
@PreAuthorize("hasAnyRole('USER', 'ADMIN')")
public String userProfile() {
return "Questo è il profilo utente.";
}
}6. Template della Pagina di Login (login.html):
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Login - Blog Application</title>
</head>
<body>
<h2>Accedi al Blog</h2>
<form th:action="@{/login}" method="post">
<div>
<label>Username:</label>
<input type="text" name="username" required />
</div>
<div>
<label>Password:</label>
<input type="password" name="password" required />
</div>
<div>
<button type="submit">Accedi</button>
</div>
</form>
<div th:if="${param.error}">
<p style="color:red;">Username o password errati.</p>
</div>
<div th:if="${param.logout}">
<p style="color:green;">Hai effettuato il logout con successo.</p>
</div>
</body>
</html>7. Configurazione delle Proprietà dell’Applicazione (application.properties):
# Imposta la porta del server
server.port=8080
# Configurazione di Thymeleaf (opzionale se si utilizza Thymeleaf)
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.suffix=.html
15.2.9 Considerazioni Finali e Best Practices
-
Gestione delle Password: Nell’esempio precedente, le password sono memorizzate in chiaro per semplicità. In un’applicazione reale, è fondamentale hashare le password utilizzando algoritmi sicuri come BCrypt.
Esempio di Hashing delle Password:
import org.springframework.context.annotation.Bean; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import org.springframework.security.crypto.password.PasswordEncoder; @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); }Successivamente, le password devono essere codificate utilizzando
passwordEncoder.encode("password")prima di salvarle. -
Gestione delle Sessioni: Implementare strategie per prevenire attacchi di tipo session fixation e gestione sicura delle sessioni utente.
-
Protezione contro CSRF: Spring Security abilita la protezione CSRF per impostazione predefinita. Assicurarsi di comprendere come funziona e come gestire i token CSRF nelle richieste.
-
Utilizzo di HTTPS: Sempre utilizzare HTTPS per proteggere i dati in transito, specialmente le credenziali degli utenti.
-
Monitoraggio e Logging: Implementare un sistema di logging efficace per tracciare eventi di sicurezza e rilevare potenziali minacce.
15.2.10 Conclusioni
L’implementazione di autenticazione e autorizzazione è essenziale per garantire la sicurezza delle applicazioni web. Spring Security offre un set completo di strumenti e configurazioni che facilitano l’adozione di pratiche di sicurezza robuste e scalabili. Comprendere e applicare correttamente questi concetti non solo protegge l’applicazione da accessi non autorizzati, ma contribuisce anche a costruire una base solida per lo sviluppo di sistemi complessi e sicuri.
15.3 OAuth2 e JWT
In questo paragrafo esploreremo due tecnologie fondamentali per la sicurezza delle applicazioni moderne: OAuth2 e JWT (JSON Web Tokens). Questi strumenti sono essenziali per implementare meccanismi di autenticazione e autorizzazione robusti, soprattutto nelle architetture basate su microservizi e API RESTful. Comprendere OAuth2 e JWT non solo migliora la sicurezza delle applicazioni, ma è anche una competenza chiave per chi si prepara a colloqui tecnici approfonditi.
15.3.1 Introduzione a OAuth2
OAuth2 è un framework di autorizzazione standardizzato che consente alle applicazioni di ottenere accesso limitato alle risorse di un utente su un server, senza esporre le credenziali dell’utente stesso. È ampiamente utilizzato per consentire a terze parti di accedere a servizi web in modo sicuro.
Perché OAuth2?
-
Delegazione dell’Autorizzazione: OAuth2 permette a un’applicazione di agire per conto di un utente, senza gestire direttamente le credenziali.
-
Scalabilità e Flessibilità: Supporta diversi tipi di client e flussi di autorizzazione, adattandosi a varie esigenze applicative.
-
Sicurezza Migliorata: Minimizza il rischio di esposizione delle credenziali degli utenti, utilizzando token di accesso temporanei e limitati.
Componenti di OAuth2
-
Resource Owner (Proprietario delle Risorse): L’utente che possiede le risorse protette.
-
Client: L’applicazione che richiede accesso alle risorse del proprietario.
-
Resource Server (Server delle Risorse): Il server che ospita le risorse protette e accetta token di accesso.
-
Authorization Server (Server di Autorizzazione): Il server che autentica il proprietario delle risorse e rilascia token di accesso al client.
Flussi di Autorizzazione OAuth2
OAuth2 definisce diversi “grant types” o flussi di autorizzazione, tra cui:
-
Authorization Code Grant: Utilizzato principalmente da applicazioni web server-side. È considerato il flusso più sicuro.
-
Implicit Grant: Destinato a applicazioni client-side (es. SPA), ma meno sicuro rispetto all’Authorization Code Grant.
-
Resource Owner Password Credentials Grant: Utilizzato quando l’utente fornisce direttamente le proprie credenziali al client.
-
Client Credentials Grant: Utilizzato per la comunicazione tra server, senza coinvolgere un utente.
Esempio di Flusso di Authorization Code Grant
-
Richiesta di Autorizzazione: Il client reindirizza l’utente al server di autorizzazione con una richiesta di autorizzazione.
-
Autenticazione dell’Utente: L’utente si autentica presso il server di autorizzazione.
-
Concessione dell’Autorizzazione: Se l’utente autorizza, il server di autorizzazione redirige l’utente al client con un codice di autorizzazione.
-
Scambio del Codice: Il client scambia il codice di autorizzazione con un token di accesso presso il server di autorizzazione.
-
Accesso alle Risorse: Il client utilizza il token di accesso per richiedere le risorse protette al resource server.
15.3.2 Introduzione a JWT
JWT (JSON Web Tokens) è uno standard aperto (RFC 7519) che definisce un modo compatto e sicuro per trasmettere informazioni tra parti come oggetti JSON. È ampiamente utilizzato per la gestione dei token di autenticazione e autorizzazione nelle applicazioni web moderne.
Perché JWT?
-
Autocontenuto: I token JWT contengono tutte le informazioni necessarie per l’autenticazione e l’autorizzazione, riducendo la necessità di interrogare un database.
-
Sicurezza: JWT può essere firmato digitalmente utilizzando HMAC o una coppia di chiavi pubblica/privata (RSA o ECDSA), garantendo l’integrità e l’autenticità del token.
-
Scalabilità: Essendo autocontenuti, i token JWT sono ideali per applicazioni distribuite e architetture a microservizi.
Struttura di un JWT
Un token JWT è composto da tre parti separate da punti:
-
Header: Specifica l’algoritmo di firma e il tipo di token.
-
Payload: Contiene le dichiarazioni (claims) che rappresentano le informazioni sull’utente e le autorizzazioni.
-
Signature: Firma digitale che garantisce l’integrità del token.
Esempio di JWT:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
Tipi di Claims
-
Registered Claims: Claim predefiniti come
iss(issuer),exp(expiration time),sub(subject), eaud(audience). -
Public Claims: Claim definiti liberamente per condividere informazioni specifiche.
-
Private Claims: Claim utilizzati internamente tra le parti che condividono il token.
15.3.3 Implementazione di OAuth2 e JWT con Spring Boot
Spring Boot offre un’integrazione completa con OAuth2 e JWT tramite il modulo Spring Security. Vediamo come configurare un’applicazione Spring Boot per utilizzare OAuth2 con JWT per la sicurezza delle API RESTful.
Configurazione di Spring Security per OAuth2 e JWT
- Aggiungere le Dipendenze
Nel file pom.xml, aggiungere le seguenti dipendenze:
<dependencies>
<!-- Spring Boot Starter Security -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<!-- OAuth2 Resource Server -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-oauth2-resource-server</artifactId>
</dependency>
<!-- JWT Support -->
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-oauth2-jose</artifactId>
</dependency>
</dependencies>- Configurare il Resource Server
Nel file application.properties o application.yml, configurare le proprietà del resource server, ad esempio:
spring.security.oauth2.resourceserver.jwt.jwk-set-uri=https://example.com/.well-known/jwks.json
Questo URL fornisce le chiavi pubbliche necessarie per verificare la firma dei JWT.
- Configurare Spring Security
Creare una classe di configurazione per Spring Security:
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SecurityConfig {
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(auth -> auth
.antMatchers("/public/**").permitAll()
.anyRequest().authenticated()
)
.oauth2ResourceServer(oauth2 -> oauth2
.jwt()
);
return http.build();
}
}Questa configurazione protegge tutte le endpoint, eccetto quelle sotto /public/**, richiedendo un token JWT valido per accedere alle risorse.
Generazione e Validazione dei JWT
In un’architettura tipica, un Authorization Server gestisce l’autenticazione dell’utente e la generazione dei token JWT. Spring Security può essere utilizzato anche per configurare un Authorization Server, ma per semplicità, supponiamo di utilizzare un provider esterno come Auth0, Okta, o Keycloak.
Esempio di Protezione di un’API RESTful
Supponiamo di avere un controller REST che espone un endpoint protetto:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.security.core.annotation.AuthenticationPrincipal;
import org.springframework.security.oauth2.jwt.Jwt;
@RestController
public class UserController {
@GetMapping("/user/profile")
public String getUserProfile(@AuthenticationPrincipal Jwt jwt) {
String username = jwt.getSubject();
return "Profilo utente per: " + username;
}
}In questo esempio, l’endpoint /user/profile è protetto e richiede un token JWT valido. Il metodo getUserProfile estrae il soggetto (sub) dal token JWT, che rappresenta l’utente autenticato.
Generazione dei Token JWT nel Authorization Server
Se si decide di implementare un Authorization Server con Spring Boot, è possibile utilizzare il modulo Spring Authorization Server. Ecco un esempio semplificato di configurazione:
- Aggiungere le Dipendenze
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-oauth2-authorization-server</artifactId>
<version>0.4.0</version>
</dependency>- Configurare l’Authorization Server
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.oauth2.server.authorization.config.annotation.web.configuration.OAuth2AuthorizationServerConfiguration;
import org.springframework.security.web.SecurityFilterChain;
@Configuration
public class AuthorizationServerConfig {
@Bean
public SecurityFilterChain authorizationServerSecurityFilterChain(HttpSecurity http) throws Exception {
OAuth2AuthorizationServerConfiguration.applyDefaultSecurity(http);
return http.formLogin().and().build();
}
}Questa configurazione imposta un Authorization Server che gestisce la generazione e la firma dei token JWT.
Protezione delle API con Ruoli e Autorizzazioni
Oltre a autenticare gli utenti, OAuth2 e JWT permettono di gestire i ruoli e le autorizzazioni. Ad esempio, è possibile definire ruoli come ROLE_USER e ROLE_ADMIN e proteggere le risorse in base ai ruoli.
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(auth -> auth
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/user/**").hasRole("USER")
.anyRequest().authenticated()
)
.oauth2ResourceServer(oauth2 -> oauth2
.jwt()
);
return http.build();
}In questo esempio, le endpoint sotto /admin/** richiedono il ruolo ADMIN, mentre quelle sotto /user/** richiedono il ruolo USER.
15.3.4 Best Practices per OAuth2 e JWT
Per garantire la massima sicurezza e efficienza nell’implementazione di OAuth2 e JWT, è importante seguire alcune best practices:
-
Uso di HTTPS: Tutte le comunicazioni che coinvolgono token di accesso devono avvenire su connessioni sicure (HTTPS) per prevenire intercettazioni.
-
Gestione della Scadenza dei Token: Configurare una scadenza appropriata per i token JWT per limitare il periodo in cui un token compromesso può essere utilizzato.
-
Revoca dei Token: Implementare meccanismi per revocare i token JWT, ad esempio mantenendo una blacklist di token invalidati.
-
Minimizzare i Claims nei JWT: Includere solo le informazioni necessarie nei token per ridurre la superficie di attacco e la dimensione del token.
-
Firmare e/o Cifrare i JWT: Utilizzare firme digitali per garantire l’integrità del token e, se necessario, cifrare i token per proteggere le informazioni sensibili.
-
Validazione Stricte dei Token: Verificare sempre la firma, la scadenza e le altre claims dei token JWT prima di accettarli.
-
Limitare i Privilegi: Utilizzare scope e autorizzazioni granulari per limitare le azioni che un token può autorizzare.
15.3.5 Esempio Pratico: Protezione di un’API con OAuth2 e JWT
Di seguito, un esempio pratico che illustra come proteggere un’API RESTful utilizzando OAuth2 e JWT in un’applicazione Spring Boot.
1. Configurazione dell’Application.properties
spring.security.oauth2.resourceserver.jwt.jwk-set-uri=https://auth-server.com/.well-known/jwks.json
2. Configurazione di Spring Security
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SecurityConfig {
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(auth -> auth
.antMatchers("/public/**").permitAll()
.antMatchers("/admin/**").hasAuthority("ROLE_ADMIN")
.anyRequest().authenticated()
)
.oauth2ResourceServer(oauth2 -> oauth2
.jwt()
);
return http.build();
}
}3. Creazione di un Controller Protetto
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.security.core.annotation.AuthenticationPrincipal;
import org.springframework.security.oauth2.jwt.Jwt;
@RestController
public class SecureController {
@GetMapping("/admin/dashboard")
public String adminDashboard(@AuthenticationPrincipal Jwt jwt) {
String username = jwt.getSubject();
return "Dashboard Admin per: " + username;
}
@GetMapping("/user/profile")
public String userProfile(@AuthenticationPrincipal Jwt jwt) {
String username = jwt.getSubject();
return "Profilo utente per: " + username;
}
}4. Testare l’API Protetta
Utilizzando strumenti come Postman o cURL, è possibile testare le endpoint protette fornendo un token JWT valido nell’header Authorization:
curl -H "Authorization: Bearer <your_jwt_token>" http://localhost:8080/admin/dashboardSe il token è valido e l’utente ha il ruolo ADMIN, riceverai una risposta di successo. Altrimenti, l’accesso sarà negato.
15.3.6 Preparazione al Colloquio Tecnico
Conoscere OAuth2 e JWT è spesso richiesto nei colloqui tecnici per posizioni di sviluppo backend e full-stack. Ecco alcuni punti chiave da preparare:
-
Concetti Fondamentali: Comprendere le differenze tra OAuth2 e OpenID Connect, i vari grant types, e come funzionano i flussi di autorizzazione.
-
Implementazione Pratica: Sapere configurare Spring Security per utilizzare OAuth2 e JWT, inclusa la gestione dei token e la protezione delle endpoint.
-
Sicurezza dei Token: Conoscere le best practices per la generazione, validazione e revoca dei token JWT.
-
Problemi Comuni: Essere preparati a risolvere problemi legati alla gestione dei token, come il refresh dei token, la gestione delle scadenze e la protezione contro attacchi come la riproduzione dei token.
-
Architetture Distribuite: Comprendere come OAuth2 e JWT si integrano in architetture a microservizi e come gestire la sicurezza in ambienti distribuiti.
Esempio di Domanda di Colloquio:
Domanda: Spiega come funziona il flusso di Authorization Code Grant in OAuth2 e come implementeresti la protezione di un’API RESTful utilizzando Spring Boot e JWT.
Risposta Attesa: Il candidato dovrebbe descrivere i passaggi del flusso di Authorization Code Grant, spiegare come configurare Spring Security per gestire OAuth2 e JWT, e illustrare come proteggere le endpoint dell’API utilizzando i token JWT per l’autenticazione e l’autorizzazione.
15.3.7 Conclusioni
OAuth2 e JWT sono strumenti potenti per implementare sicurezza avanzata nelle applicazioni Spring Boot. La loro comprensione non solo garantisce la protezione delle risorse, ma dimostra anche una conoscenza approfondita delle best practices di sicurezza, essenziale per affrontare sfide tecniche complesse e per eccellere nei colloqui di lavoro.
Nel prossimo capitolo, approfondiremo il Testing delle Applicazioni, esplorando come garantire che le implementazioni di sicurezza siano affidabili e prive di vulnerabilità.
Capitolo 16: Testing delle Applicazioni
16.1 Testing Unitario con JUnit e Mockito
Il testing unitario è una pratica fondamentale nello sviluppo software moderno, che consente di verificare il corretto funzionamento di singole unità di codice, tipicamente metodi o classi, isolandoli dal resto dell’applicazione. In Java, due degli strumenti più utilizzati per il testing unitario sono JUnit e Mockito. Questa sezione esplorerà come utilizzare questi strumenti per scrivere test unitari efficaci, illustrando concetti chiave, best practices e fornendo esempi pratici.
16.1.1 Introduzione al Testing Unitario
Cos’è il Testing Unitario?
Il testing unitario consiste nel verificare che singole unità di codice funzionino come previsto. Ogni test unitario si concentra su una piccola porzione del codice, garantendo che ogni componente isolato si comporti correttamente in diversi scenari. Questo approccio facilita l’identificazione precoce di bug, migliora la manutenzione del codice e favorisce la scrittura di codice più modulare e testabile.
Perché è Importante?
-
Qualità del Codice: Identifica e corregge errori prima che il codice venga integrato in parti più grandi dell’applicazione.
-
Manutenzione Facilitata: Modifiche future diventano più sicure, poiché i test unitari possono rilevare regressioni.
-
Documentazione Vivente: I test forniscono esempi concreti di come le unità di codice dovrebbero comportarsi.
-
Design Migliore: Promuove un’architettura più modulare e decoupled, facilitando il testing e la riusabilità.
16.1.2 Introduzione a JUnit
Cos’è JUnit?
JUnit è uno dei framework di testing più diffusi per Java. Fornisce un insieme di annotazioni e asserzioni che semplificano la scrittura e l’esecuzione di test unitari. La versione più recente, JUnit 5, introduce nuove funzionalità e una maggiore modularità rispetto alle versioni precedenti.
Configurazione di JUnit
Per utilizzare JUnit in un progetto Spring Boot, è comune gestire le dipendenze tramite Maven o Gradle. Ecco un esempio di configurazione con Maven:
<dependencies>
<!-- JUnit 5 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.9.3</version>
<scope>test</scope>
</dependency>
<!-- Mockito -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>5.5.0</version>
<scope>test</scope>
</dependency>
</dependencies>16.1.3 Scrittura di Test Unitari con JUnit
Struttura di un Test Unitario
Un test unitario in JUnit 5 è generalmente composto da:
-
Annotazioni di Test:
@Testper indicare un metodo di test. -
Setup e Teardown:
@BeforeEache@AfterEachper configurare lo stato prima e dopo ogni test. -
Asserzioni: Metodi di JUnit per verificare i risultati attesi.
Esempio Pratico:
Supponiamo di avere una semplice classe Calculator con un metodo add:
public class Calculator {
public int add(int a, int b) {
return a + b;
}
}Scriviamo un test unitario per il metodo add:
import static org.junit.jupiter.api.Assertions.assertEquals;
import org.junit.jupiter.api.Test;
public class CalculatorTest {
@Test
void testAdd() {
// Arrange
Calculator calculator = new Calculator();
int a = 5;
int b = 7;
// Act
int result = calculator.add(a, b);
// Assert
assertEquals(12, result, "5 + 7 dovrebbe essere 12");
}
}Spiegazione:
-
Arrange: Configuriamo l’oggetto
Calculatore definiamo i valori di input. -
Act: Chiamiamo il metodo
addcon gli input. -
Assert: Verifichiamo che il risultato sia quello atteso utilizzando
assertEquals.
16.1.4 Mocking con Mockito
Cos’è Mockito?
Mockito è un framework di mocking per Java che consente di creare oggetti mock, simulando il comportamento delle dipendenze di una classe. Questo è particolarmente utile quando si testano unità di codice che dipendono da componenti esterni come database, servizi web o altre classi complesse.
Perché Usare Mockito?
-
Isolamento: Permette di testare una classe senza dipendere dalle sue dipendenze reali.
-
Controllo: Consente di definire comportamenti specifici delle dipendenze per scenari di test diversi.
-
Verifica: Facilita la verifica delle interazioni tra la classe sotto test e le sue dipendenze.
Configurazione di Mockito
Mockito può essere utilizzato insieme a JUnit 5 tramite annotazioni come @ExtendWith e @Mock. Ecco un esempio di configurazione:
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.junit.jupiter.MockitoExtension;
@ExtendWith(MockitoExtension.class)
public class ServiceTest {
// Test class
}Esempio Pratico:
Consideriamo una classe UserService che dipende da un UserRepository per recuperare dati degli utenti:
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User getUserById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new UserNotFoundException("User not found with id: " + id));
}
}Test Unitario con Mockito:
import static org.junit.jupiter.api.Assertions.*;
import static org.mockito.Mockito.*;
import java.util.Optional;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.InjectMocks;
import org.mockito.MockitoAnnotations;
public class UserServiceTest {
@Mock
private UserRepository userRepository;
@InjectMocks
private UserService userService;
@BeforeEach
void setUp() {
MockitoAnnotations.openMocks(this);
}
@Test
void testGetUserById_UserExists() {
// Arrange
Long userId = 1L;
User mockUser = new User(userId, "John Doe");
when(userRepository.findById(userId)).thenReturn(Optional.of(mockUser));
// Act
User user = userService.getUserById(userId);
// Assert
assertNotNull(user);
assertEquals("John Doe", user.getName());
verify(userRepository, times(1)).findById(userId);
}
@Test
void testGetUserById_UserDoesNotExist() {
// Arrange
Long userId = 2L;
when(userRepository.findById(userId)).thenReturn(Optional.empty());
// Act & Assert
Exception exception = assertThrows(UserNotFoundException.class, () -> {
userService.getUserById(userId);
});
assertEquals("User not found with id: 2", exception.getMessage());
verify(userRepository, times(1)).findById(userId);
}
}Spiegazione:
-
Annotazioni:
-
@Mock: Crea un mock dell’interfacciaUserRepository. -
@InjectMocks: Inietta i mock creati nelle istanze diUserService.
-
-
Setup:
MockitoAnnotations.openMocks(this): Inizializza i mock prima di ogni test.
-
Test Case 1 - Utente Esistente:
-
Arrange: Configuriamo il mock per restituire un utente specifico quando viene chiamato
findById. -
Act: Chiamiamo
getUserByIdcon un ID esistente. -
Assert: Verifichiamo che l’utente restituito non sia nullo, abbia il nome corretto e che
findByIdsia stato chiamato una volta.
-
-
Test Case 2 - Utente Inesistente:
-
Arrange: Configuriamo il mock per restituire
Optional.empty()quando viene chiamatofindById. -
Act & Assert: Verifichiamo che venga lanciata un’eccezione
UserNotFoundExceptioncon il messaggio corretto e chefindByIdsia stato chiamato una volta.
-
16.1.5 Best Practices per il Testing Unitario
-
Isolare le Unità di Test:
- Ogni test dovrebbe concentrarsi su una singola unità di codice, senza dipendere da altre parti dell’applicazione.
-
Utilizzare Nomi Descrittivi per i Test:
- I nomi dei metodi di test dovrebbero riflettere chiaramente cosa viene testato, ad esempio
testAdd_ValidInputs_ReturnsSum.
- I nomi dei metodi di test dovrebbero riflettere chiaramente cosa viene testato, ad esempio
-
Seguire l’Approccio Arrange-Act-Assert:
- Organizzare il codice di test in sezioni chiare per preparare il contesto, eseguire l’azione e verificare il risultato.
-
Evitare Logica Complessa nei Test:
- I test dovrebbero essere semplici e diretti. Evitare condizioni o logica complessa che potrebbe introdurre errori nei test stessi.
-
Mockare Solo le Dipendenze Necessarie:
- Utilizzare Mockito per simulare solo le dipendenze esterne che non sono direttamente rilevanti per il test in questione.
-
Scrivere Test Ripetibili e Deterministici:
- I test dovrebbero poter essere eseguiti in qualsiasi ordine e produrre sempre gli stessi risultati.
-
Eseguire i Test Frequentemente:
- Integrare l’esecuzione dei test nel processo di sviluppo quotidiano per rilevare rapidamente regressioni.
-
Mantenere i Test Aggiornati:
- Aggiornare i test quando il codice sottostante cambia per garantire che i test riflettano sempre lo stato attuale dell’applicazione.
16.1.6 Esempio Completo: Testing di un Servizio in Spring Boot
Consideriamo un’applicazione Spring Boot che gestisce prodotti. Abbiamo una classe ProductService che dipende da ProductRepository per accedere ai dati.
Classe Product:
public class Product {
private Long id;
private String name;
private Double price;
// Costruttori, getters e setters
}Interfaccia ProductRepository:
import java.util.Optional;
public interface ProductRepository {
Optional<Product> findById(Long id);
Product save(Product product);
// Altri metodi CRUD
}Classe ProductService:
public class ProductService {
private final ProductRepository productRepository;
public ProductService(ProductRepository productRepository) {
this.productRepository = productRepository;
}
public Product getProductById(Long id) {
return productRepository.findById(id)
.orElseThrow(() -> new ProductNotFoundException("Product not found with id: " + id));
}
public Product createProduct(Product product) {
// Logica aggiuntiva, ad esempio validazioni
return productRepository.save(product);
}
}Test Unitario per ProductService:
import static org.junit.jupiter.api.Assertions.*;
import static org.mockito.Mockito.*;
import java.util.Optional;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.mockito.*;
public class ProductServiceTest {
@Mock
private ProductRepository productRepository;
@InjectMocks
private ProductService productService;
private Product sampleProduct;
@BeforeEach
void setUp() {
MockitoAnnotations.openMocks(this);
sampleProduct = new Product(1L, "Laptop", 999.99);
}
@Test
void testGetProductById_ProductExists() {
// Arrange
when(productRepository.findById(1L)).thenReturn(Optional.of(sampleProduct));
// Act
Product product = productService.getProductById(1L);
// Assert
assertNotNull(product);
assertEquals("Laptop", product.getName());
verify(productRepository, times(1)).findById(1L);
}
@Test
void testGetProductById_ProductDoesNotExist() {
// Arrange
when(productRepository.findById(2L)).thenReturn(Optional.empty());
// Act & Assert
Exception exception = assertThrows(ProductNotFoundException.class, () -> {
productService.getProductById(2L);
});
assertEquals("Product not found with id: 2", exception.getMessage());
verify(productRepository, times(1)).findById(2L);
}
@Test
void testCreateProduct_ValidProduct() {
// Arrange
Product newProduct = new Product(null, "Smartphone", 499.99);
Product savedProduct = new Product(2L, "Smartphone", 499.99);
when(productRepository.save(newProduct)).thenReturn(savedProduct);
// Act
Product result = productService.createProduct(newProduct);
// Assert
assertNotNull(result);
assertEquals(2L, result.getId());
assertEquals("Smartphone", result.getName());
verify(productRepository, times(1)).save(newProduct);
}
}Spiegazione:
-
Annotazioni e Setup:
-
@Mockcrea un mock diProductRepository. -
@InjectMockscrea un’istanza diProductServicee inietta il mock diProductRepository. -
setUp()inizializza i mock e crea un oggettosampleProductda utilizzare nei test.
-
-
Test Case 1 - Prodotto Esistente:
- Verifica che
getProductByIdritorni il prodotto corretto quando esiste nel repository.
- Verifica che
-
Test Case 2 - Prodotto Inesistente:
- Verifica che venga lanciata un’eccezione
ProductNotFoundExceptionquando il prodotto non esiste.
- Verifica che venga lanciata un’eccezione
-
Test Case 3 - Creazione di un Prodotto:
- Verifica che
createProductsalvi correttamente un nuovo prodotto e ritorni l’istanza salvata con l’ID assegnato.
- Verifica che
16.1.7 Conclusioni
Il testing unitario è essenziale per garantire la qualità e la robustezza del codice. Utilizzando JUnit e Mockito, gli sviluppatori possono scrivere test chiari e affidabili che isolano le unità di codice e simulano le loro dipendenze. Adottare le best practices nel testing unitario non solo migliora la qualità del software, ma facilita anche la manutenzione e l’evoluzione delle applicazioni nel tempo. Continuare a praticare e approfondire questi strumenti e metodologie permetterà di affrontare con sicurezza le sfide tecniche sia nei progetti quotidiani che nei colloqui di lavoro.
16.2 Testing di Integrazione
Introduzione al Testing di Integrazione
Il testing di integrazione rappresenta una fase cruciale nel ciclo di vita dello sviluppo software, poiché verifica l’interazione tra diversi componenti o moduli di un’applicazione. A differenza del testing unitario, che si concentra sul singolo componente isolato, il testing di integrazione si assicura che le unità funzionino correttamente insieme, simulando scenari reali di utilizzo.
Nel contesto di applicazioni Spring Boot, il testing di integrazione consente di validare l’intero flusso dell’applicazione, inclusa la configurazione del contesto Spring, la comunicazione tra i vari bean, l’accesso al database e l’interazione con servizi esterni. Questo tipo di test è fondamentale per individuare problemi che potrebbero non emergere durante i test unitari, garantendo una maggiore affidabilità e robustezza dell’applicazione.
Perché il Testing di Integrazione è Importante
-
Verifica della Collaborazione tra Componenti: Assicura che i vari moduli dell’applicazione interagiscano correttamente, rispettando le interfacce e i contratti definiti.
-
Identificazione di Problemi di Configurazione: Rileva errori nella configurazione del contesto Spring, come la mancata iniezione di dipendenze o la configurazione errata dei bean.
-
Validazione delle Interazioni con il Database: Garantisce che le operazioni di persistenza funzionino come previsto, verificando le query SQL e le transazioni.
-
Simulazione di Scenari Realistici: Riproduce condizioni operative reali, facilitando l’individuazione di bug che potrebbero manifestarsi solo in ambienti complessi.
Strumenti e Tecniche per il Testing di Integrazione in Spring Boot
Spring Boot offre un supporto robusto per il testing di integrazione attraverso diverse annotazioni e strumenti integrati. Tra i principali strumenti utilizzati vi sono:
-
@SpringBootTest: Carica l’intero contesto Spring per eseguire test di integrazione completi.
-
Testcontainers: Utilizza container Docker per creare ambienti di test isolati e coerenti.
-
Embedded Databases: Banche dati in memoria come H2 per testare le operazioni di persistenza senza dipendere da un database esterno.
-
Mocking di Servizi Esterni: Simula le interazioni con API esterne o servizi remoti utilizzando strumenti come WireMock.
Configurazione di un Test di Integrazione con @SpringBootTest
L’annotazione @SpringBootTest è fondamentale per configurare un test di integrazione in Spring Boot. Essa permette di caricare l’intero contesto dell’applicazione, rendendo disponibili tutti i bean e le configurazioni necessarie per eseguire il test in un ambiente simile a quello di produzione.
Esempio Pratico: Test di Integrazione di un Servizio
Supponiamo di avere un semplice servizio che gestisce entità User. Vogliamo testare che il servizio possa salvare e recuperare correttamente un utente dal database.
1. Definizione dell’Entità User
// src/main/java/com/esempio/demo/model/User.java
package com.esempio.demo.model;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Costruttori, getter e setter
public User() {}
public User(String name, String email) {
this.name = name;
this.email = email;
}
// Getters e Setters
// ...
}2. Definizione del Repository UserRepository
// src/main/java/com/esempio/demo/repository/UserRepository.java
package com.esempio.demo.repository;
import com.esempio.demo.model.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
User findByEmail(String email);
}3. Definizione del Servizio UserService
// src/main/java/com/esempio/demo/service/UserService.java
package com.esempio.demo.service;
import com.esempio.demo.model.User;
import com.esempio.demo.repository.UserRepository;
import org.springframework.stereotype.Service;
import java.util.Optional;
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User saveUser(User user) {
return userRepository.save(user);
}
public Optional<User> getUserByEmail(String email) {
return Optional.ofNullable(userRepository.findByEmail(email));
}
}4. Configurazione del Test di Integrazione
// src/test/java/com/esempio/demo/service/UserServiceIntegrationTest.java
package com.esempio.demo.service;
import com.esempio.demo.model.User;
import com.esempio.demo.repository.UserRepository;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.ActiveProfiles;
import static org.assertj.core.api.Assertions.assertThat;
@SpringBootTest
@ActiveProfiles("test") // Utilizza le configurazioni specifiche per il test
public class UserServiceIntegrationTest {
@Autowired
private UserService userService;
@Autowired
private UserRepository userRepository;
@BeforeEach
void setUp() {
userRepository.deleteAll(); // Pulisce il database prima di ogni test
}
@Test
void testSaveAndRetrieveUser() {
// Creazione di un nuovo utente
User user = new User("Mario Rossi", "mario.rossi@example.com");
User savedUser = userService.saveUser(user);
// Verifica che l'utente sia stato salvato con un ID generato
assertThat(savedUser.getId()).isNotNull();
// Recupero dell'utente per email
Optional<User> retrievedUser = userService.getUserByEmail("mario.rossi@example.com");
// Verifica che l'utente recuperato non sia vuoto e abbia i dati corretti
assertThat(retrievedUser).isPresent();
assertThat(retrievedUser.get().getName()).isEqualTo("Mario Rossi");
assertThat(retrievedUser.get().getEmail()).isEqualTo("mario.rossi@example.com");
}
}5. Configurazione dell’Ambiente di Test
Per garantire che i test di integrazione non interferiscano con l’ambiente di produzione, è consigliabile utilizzare un database in memoria come H2 durante i test. Questo può essere configurato nel file application-test.properties.
# src/test/resources/application-test.properties
spring.datasource.url=jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=create-drop
Esecuzione del Test
Quando si esegue il test UserServiceIntegrationTest, Spring Boot caricherà il contesto completo dell’applicazione utilizzando le configurazioni specificate per il profilo test. Il database H2 in memoria verrà utilizzato per le operazioni di persistenza, garantendo un ambiente isolato e replicabile.
L’esecuzione del test verificherà che:
-
L’utente venga correttamente salvato nel database.
-
L’utente possa essere recuperato tramite il repository.
-
I dati dell’utente recuperato corrispondano a quelli originariamente salvati.
Best Practices per il Testing di Integrazione
-
Isolamento dei Test: Assicurarsi che ogni test sia indipendente dagli altri, evitando dipendenze tra i dati o lo stato dell’applicazione.
-
Utilizzo di Profili di Test: Configurare profili specifici per i test (
application-test.properties) per separare le configurazioni di produzione da quelle di test. -
Pulizia del Database: Utilizzare metodi come
@BeforeEacho@AfterEachper pulire il database prima o dopo ogni test, garantendo che ogni test parta da uno stato pulito. -
Utilizzo di Embedded Databases: Preferire l’uso di database in memoria per velocizzare i test e semplificare la configurazione.
-
Mocking di Servizi Esterni: Per evitare dipendenze da servizi esterni, utilizzare strumenti di mocking come WireMock per simulare le risposte delle API esterne.
-
Ridurre la Complessità del Contesto: Caricare solo i bean necessari per il test, evitando di caricare l’intero contesto quando non necessario, per migliorare le prestazioni dei test.
-
Utilizzo di Testcontainers: Per scenari più complessi, utilizzare Testcontainers per creare ambienti di test basati su container Docker, garantendo una maggiore coerenza con l’ambiente di produzione.
Conclusione
Il testing di integrazione in Spring Boot è essenziale per garantire che i vari componenti di un’applicazione funzionino armoniosamente. Utilizzando strumenti come @SpringBootTest, database in memoria e tecniche di isolamento, è possibile creare test robusti e affidabili che migliorano la qualità del software e riducono il rischio di bug in produzione. Adottare le best practices descritte assicura che i test di integrazione siano efficaci e mantenibili nel tempo, facilitando lo sviluppo di applicazioni Spring Boot scalabili e resilienti.
16.3 Test delle API REST
Nel contesto delle applicazioni moderne, le API REST (Representational State Transfer) costituiscono l’interfaccia principale attraverso cui i client interagiscono con il server. Garantire la correttezza e l’affidabilità di queste API è fondamentale per il successo di qualsiasi applicazione. In questa sezione, esploreremo come testare efficacemente le API REST in un’applicazione Spring Boot utilizzando due strumenti potenti: MockMvc e RestAssured. Attraverso esempi pratici, comprenderemo come configurare e scrivere test che assicurino il corretto funzionamento degli endpoint REST.
16.3.1 Introduzione ai Test delle API REST
I test delle API REST mirano a verificare che gli endpoint esposti dall’applicazione rispondano correttamente alle richieste, gestiscano adeguatamente i dati e mantengano l’integrità delle operazioni. Questi test possono essere suddivisi in:
-
Test Unitari: Verificano singoli componenti o metodi isolati.
-
Test di Integrazione: Valutano l’interazione tra più componenti dell’applicazione.
-
Test End-to-End: Simulano scenari reali di utilizzo dell’applicazione dall’inizio alla fine.
In questa sezione, ci concentreremo principalmente sui test di integrazione delle API REST utilizzando MockMvc e RestAssured.
16.3.2 Strumenti per il Testing delle API REST
MockMvc e RestAssured sono due strumenti ampiamente utilizzati per testare le API REST in applicazioni Spring Boot. Ognuno di essi ha caratteristiche distintive che li rendono adatti a diversi scenari di testing.
-
MockMvc: Integrato con Spring, consente di testare i controller in modo rapido e isolato senza avviare un server web.
-
RestAssured: Offre una sintassi fluente per testare API RESTful reali, richiedendo che l’applicazione sia in esecuzione su un server.
16.3.3 Test delle API REST con MockMvc
MockMvc è uno strumento potente per testare i controller Spring MVC senza la necessità di avviare un server web. Questo rende i test più veloci e facili da configurare.
Configurazione di MockMvc
Per utilizzare MockMvc, è necessario includere le dipendenze appropriate nel progetto. Aggiungi le seguenti dipendenze nel tuo pom.xml (se utilizzi Maven):
<dependencies>
<!-- Altre dipendenze -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Esempio Pratico: Test di un Endpoint GET
Supponiamo di avere un controller che gestisce le richieste per ottenere informazioni su un utente:
@RestController
@RequestMapping("/api/users")
public class UserController {
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
// Simulazione del recupero dell'utente
User user = new User(id, "Mario Rossi", "mario.rossi@example.com");
return ResponseEntity.ok(user);
}
}Creiamo un test per verificare che l’endpoint GET /api/users/{id} funzioni correttamente.
@SpringBootTest
@AutoConfigureMockMvc
public class UserControllerTest {
@Autowired
private MockMvc mockMvc;
@Test
public void testGetUserById() throws Exception {
mockMvc.perform(get("/api/users/{id}", 1L))
.andExpect(status().isOk())
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
.andExpect(jsonPath("$.id").value(1L))
.andExpect(jsonPath("$.name").value("Mario Rossi"))
.andExpect(jsonPath("$.email").value("mario.rossi@example.com"));
}
}Spiegazione del Test:
-
@SpringBootTest: Carica l’intero contesto dell’applicazione per i test.
-
@AutoConfigureMockMvc: Configura automaticamente MockMvc.
-
mockMvc.perform(…): Esegue una richiesta HTTP simulata.
-
andExpect(…): Verifica le aspettative sulla risposta.
Esempio Pratico: Test di un Endpoint POST
Consideriamo un endpoint che permette di creare un nuovo utente:
@PostMapping
public ResponseEntity<User> createUser(@RequestBody User user) {
// Simulazione della creazione dell'utente
user.setId(2L);
return ResponseEntity.status(HttpStatus.CREATED).body(user);
}Testiamo questo endpoint:
@Test
public void testCreateUser() throws Exception {
User newUser = new User(null, "Luigi Verdi", "luigi.verdi@example.com");
ObjectMapper objectMapper = new ObjectMapper();
String userJson = objectMapper.writeValueAsString(newUser);
mockMvc.perform(post("/api/users")
.contentType(MediaType.APPLICATION_JSON)
.content(userJson))
.andExpect(status().isCreated())
.andExpect(content().contentType(MediaType.APPLICATION_JSON))
.andExpect(jsonPath("$.id").value(2L))
.andExpect(jsonPath("$.name").value("Luigi Verdi"))
.andExpect(jsonPath("$.email").value("luigi.verdi@example.com"));
}Spiegazione del Test:
-
Creazione dell’oggetto User: Prepara un oggetto
Userda inviare nel corpo della richiesta. -
ObjectMapper: Converte l’oggetto
Userin una stringa JSON. -
mockMvc.perform(post(…)): Esegue una richiesta POST simulata con il corpo JSON.
-
andExpect(…): Verifica che la risposta abbia lo status 201 (Created) e i campi corretti.
16.3.4 Test delle API REST con RestAssured
RestAssured è una libreria Java dedicata al testing delle API RESTful con una sintassi fluente e intuitiva. A differenza di MockMvc, RestAssured richiede che l’applicazione sia in esecuzione su un server, permettendo di testare l’API in un ambiente più vicino a quello di produzione.
Configurazione di RestAssured
Aggiungi le dipendenze di RestAssured nel tuo pom.xml:
<dependencies>
<!-- Altre dipendenze -->
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>5.3.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Esempio Pratico: Test di un Endpoint GET con RestAssured
Assumiamo lo stesso controller UserController. Creiamo un test utilizzando RestAssured.
import io.restassured.RestAssured;
import org.junit.jupiter.api.BeforeEach;
import org.springframework.boot.web.server.LocalServerPort;
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class UserControllerRestAssuredTest {
@LocalServerPort
private int port;
@BeforeEach
public void setUp() {
RestAssured.port = port;
}
@Test
public void testGetUserById() {
RestAssured.given()
.when()
.get("/api/users/{id}", 1L)
.then()
.statusCode(200)
.contentType(MediaType.APPLICATION_JSON_VALUE)
.body("id", equalTo(1))
.body("name", equalTo("Mario Rossi"))
.body("email", equalTo("mario.rossi@example.com"));
}
}Spiegazione del Test:
-
@SpringBootTest(webEnvironment = RANDOM_PORT): Avvia l’applicazione su una porta casuale per i test.
-
@LocalServerPort: Inietta la porta assegnata.
-
RestAssured.port: Configura RestAssured per utilizzare la porta assegnata.
-
RestAssured.given().when().get(…).then(): Definisce la richiesta e le aspettative sulla risposta.
Esempio Pratico: Test di un Endpoint POST con RestAssured
Testiamo l’endpoint POST per creare un nuovo utente:
@Test
public void testCreateUser() {
User newUser = new User(null, "Luigi Verdi", "luigi.verdi@example.com");
RestAssured.given()
.contentType(MediaType.APPLICATION_JSON_VALUE)
.body(newUser)
.when()
.post("/api/users")
.then()
.statusCode(201)
.contentType(MediaType.APPLICATION_JSON_VALUE)
.body("id", equalTo(2))
.body("name", equalTo("Luigi Verdi"))
.body("email", equalTo("luigi.verdi@example.com"));
}Spiegazione del Test:
-
Definizione dell’oggetto User: Prepara un oggetto
Userda inviare nella richiesta. -
RestAssured.given(): Configura la richiesta con il tipo di contenuto e il corpo JSON.
-
.when().post(…).then(): Esegue la richiesta POST e definisce le aspettative sulla risposta.
16.3.5 Best Practices per il Test delle API REST
Per garantire che i test delle API REST siano efficaci e mantenibili, è importante seguire alcune best practices:
-
Isolamento dei Test: Ogni test dovrebbe essere indipendente dagli altri, evitando dipendenze esterne come database o servizi esterni. Utilizza mock o database in memoria quando possibile.
-
Chiarezza e Semplicità: I test dovrebbero essere facili da leggere e comprendere. Utilizza nomi di metodi descrittivi e commenti quando necessario.
-
Copertura Completa: Assicurati di testare tutti gli endpoint, inclusi casi di successo e scenari di errore. Verifica anche la validazione dei dati e la gestione delle eccezioni.
-
Automazione dei Test: Integra i test nel processo di build e deployment per eseguire automaticamente i test ad ogni modifica del codice.
-
Utilizzo di Dati di Test Realistici: Usa dati che riflettano scenari reali per garantire che i test siano significativi e utili.
-
Manutenzione dei Test: Mantieni i test aggiornati con le modifiche dell’applicazione. Test obsoleti o fragili possono causare falsi positivi o negativi.
16.3.6 Considerazioni Finali
Il testing delle API REST è una componente essenziale nello sviluppo di applicazioni Spring Boot robuste e affidabili. Utilizzando strumenti come MockMvc e RestAssured, è possibile scrivere test efficaci che garantiscano il corretto funzionamento degli endpoint, facilitando la manutenzione e l’evoluzione dell’applicazione. Seguendo le best practices descritte, si può assicurare una copertura di test completa e una maggiore fiducia nella qualità del codice.
Capitolo 17: Microservizi con Spring Boot
17.1 Architettura a Microservizi
L’architettura a microservizi rappresenta un paradigma di progettazione software che suddivide un’applicazione in una collezione di servizi piccoli, autonomi e altamente specializzati. Questo approccio contrasta con l’architettura monolitica tradizionale, offrendo una serie di vantaggi in termini di scalabilità, manutenzione e flessibilità. In questa sezione, esploreremo i principi fondamentali dell’architettura a microservizi e le principali differenze rispetto all’architettura monolitica.
Principi Fondamentali dell’Architettura a Microservizi
-
Servizi Indipendenti: Ogni microservizio è un’unità autonoma che incapsula una specifica funzionalità di business. Questo isolamento permette di sviluppare, distribuire e scalare i servizi in modo indipendente l’uno dall’altro.
-
Single Responsibility Principle (SRP): Ogni microservizio dovrebbe avere una singola responsabilità o una singola ragione per cambiare. Questo principio favorisce la modularità e facilita la manutenzione del codice.
-
Comunicazione tramite API: I microservizi interagiscono tra loro attraverso interfacce ben definite, solitamente API RESTful o messaggistica asincrona. Questa separazione delle interfacce garantisce che i servizi possano evolvere indipendentemente.
-
Decentralizzazione dei Dati: Ogni microservizio gestisce il proprio database o sistema di persistenza, evitando dipendenze dirette sui dati gestiti da altri servizi. Questo approccio riduce i colli di bottiglia e aumenta la resilienza dell’applicazione.
-
Automazione e DevOps: L’adozione di pratiche DevOps, come l’integrazione continua e il deployment continuo (CI/CD), è essenziale per gestire efficacemente un’architettura a microservizi. L’automazione facilita il rilascio frequente e affidabile dei servizi.
-
Scalabilità: I microservizi possono essere scalati in modo indipendente in base alle necessità, ottimizzando l’uso delle risorse e migliorando le prestazioni complessive dell’applicazione.
-
Resilienza: L’architettura a microservizi promuove la tolleranza agli errori, poiché il fallimento di un servizio non compromette l’intera applicazione. Tecniche come il circuit breaker e il retry mechanism aiutano a gestire le interazioni tra servizi in modo robusto.
Differenze Rispetto all’Architettura Monolitica
L’architettura monolitica e quella a microservizi rappresentano due approcci distinti alla progettazione delle applicazioni, ognuno con i propri vantaggi e svantaggi. Di seguito, evidenziamo le principali differenze tra i due paradigmi:
Vantaggi dell’Architettura a Microservizi
-
Flessibilità Tecnologica: Permette di adottare diverse tecnologie e linguaggi di programmazione per ciascun microservizio, ottimizzando le scelte tecnologiche in base alle specifiche esigenze.
-
Scalabilità Migliorata: Consente di scalare solo le parti dell’applicazione che necessitano di risorse aggiuntive, riducendo i costi e migliorando le prestazioni.
-
Velocità di Sviluppo: I team possono lavorare in parallelo su diversi microservizi, accelerando il ciclo di sviluppo e il time-to-market.
-
Resilienza e Affidabilità: Isolando i servizi, si riduce il rischio che un singolo punto di guasto comprometta l’intera applicazione.
-
Manutenzione Facilitata: La modularità favorisce una maggiore facilità nella gestione del codice, nella risoluzione dei bug e nell’implementazione di nuove funzionalità.
Sfide dell’Architettura a Microservizi
Nonostante i numerosi vantaggi, l’architettura a microservizi presenta anche delle sfide:
-
Complessità di Gestione: Coordinare e gestire numerosi servizi può diventare complicato, richiedendo strumenti e competenze specifiche.
-
Comunicazione Interservizi: Garantire comunicazioni efficienti e affidabili tra i microservizi può essere impegnativo, specialmente in scenari di rete complessi.
-
Consistenza dei Dati: Mantenere la consistenza dei dati tra servizi indipendenti può richiedere l’adozione di strategie avanzate come l’event sourcing o il sagas pattern.
-
Monitoraggio e Debugging: Identificare e risolvere problemi in un ambiente distribuito richiede strumenti di monitoraggio avanzati e pratiche di logging centralizzato.
Conclusione
L’architettura a microservizi offre un approccio moderno e flessibile per la progettazione di applicazioni scalabili e manutenibili. Sebbene introduca una maggiore complessità rispetto all’architettura monolitica, i benefici in termini di scalabilità, resilienza e agilità di sviluppo la rendono una scelta preferita per molte organizzazioni, soprattutto in contesti di grandi dimensioni e progetti complessi. Comprendere i principi fondamentali e le differenze rispetto ai modelli tradizionali è essenziale per sfruttare appieno il potenziale dei microservizi e affrontare con successo le sfide associate.
17.2 Spring Cloud
Introduzione a Spring Cloud
Nel contesto dell’architettura a microservizi, la gestione e l’orchestrazione di numerosi servizi indipendenti possono diventare complesse e difficili da gestire senza strumenti adeguati. Spring Cloud si presenta come un insieme di strumenti e framework che estendono le capacità di Spring Boot, facilitando la costruzione di sistemi distribuiti robusti, scalabili e facilmente manutenibili. Spring Cloud fornisce soluzioni pronte all’uso per affrontare le sfide comuni nelle architetture a microservizi, come la gestione della configurazione, il service discovery, il bilanciamento del carico, la tolleranza ai guasti e molto altro.
Componenti Chiave di Spring Cloud
Spring Cloud integra diversi componenti e progetti open source che semplificano lo sviluppo e la gestione di microservizi. Tra i principali componenti troviamo:
-
Spring Cloud Config: Fornisce un sistema centralizzato per la gestione delle configurazioni delle applicazioni distribuite. Consente di mantenere le configurazioni in un repository Git, SVN o filesystem, facilitando la gestione delle proprietà in ambienti diversi (sviluppo, test, produzione).
-
Spring Cloud Netflix: Integra diversi progetti Netflix OSS, tra cui:
-
Eureka: Un service registry per il service discovery, che permette ai microservizi di registrarsi e di scoprire altri servizi all’interno del sistema.
-
Ribbon: Un client-side load balancer che distribuisce le richieste tra le istanze di un servizio registrato.
-
Hystrix: Implementa il pattern Circuit Breaker, migliorando la resilienza del sistema gestendo le chiamate fallimentari e prevenendo il cascamento degli errori.
-
Zuul: Un API Gateway che funge da punto di ingresso per tutte le richieste esterne, gestendo il routing, la sicurezza e altre responsabilità trasversali.
-
-
Spring Cloud Gateway: Un’alternativa moderna a Zuul, offre funzionalità avanzate di routing e filtraggio delle richieste, migliorando le performance e la flessibilità nella gestione del traffico.
-
Spring Cloud Sleuth e Zipkin: Strumenti per il tracciamento distribuito, che permettono di monitorare e diagnosticare le richieste che attraversano più microservizi, facilitando l’individuazione di colli di bottiglia e problemi di latenza.
-
Spring Cloud Stream: Facilita la costruzione di applicazioni basate su eventi e messaggistica, integrandosi con broker come Kafka e RabbitMQ.
Configurazione e Integrazione con Spring Boot
L’integrazione di Spring Cloud in un progetto Spring Boot è semplice grazie all’ecosistema di starter forniti. Ad esempio, per utilizzare Eureka come service discovery, è sufficiente aggiungere le dipendenze necessarie e configurare l’applicazione.
Esempio di configurazione di Eureka Client:
- Aggiungere le dipendenze nel
pom.xml:
<dependencies>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Spring Cloud Starter Netflix Eureka Client -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR12</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>- Configurare l’applicazione
application.yml:
spring:
application:
name: mio-servizio
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka/- Abilitare Eureka Client nel main application class:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
@SpringBootApplication
@EnableEurekaClient
public class MioServizioApplication {
public static void main(String[] args) {
SpringApplication.run(MioServizioApplication.class, args);
}
}Esempio Pratico: Implementazione di un Service Discovery con Eureka
Consideriamo un’architettura semplice composta da un Eureka Server e due Eureka Clients. L’Eureka Server fungerà da registry centrale, mentre i client si registreranno automaticamente al server e potranno scoprire altri servizi registrati.
-
Configurazione del Eureka Server:
- Aggiungere le dipendenze nel
pom.xml:
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> </dependencies>- Configurare l’applicazione
application.yml:
server: port: 8761 eureka: client: register-with-eureka: false fetch-registry: false server: enable-self-preservation: false- Abilitare Eureka Server nel main application class:
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication @EnableEurekaServer public class EurekaServerApplication { public static void main(String[] args) { SpringApplication.run(EurekaServerApplication.class, args); } } - Aggiungere le dipendenze nel
-
Configurazione dei Eureka Clients:
Riprendendo l’esempio precedente, ogni microservizio che desidera registrarsi presso Eureka deve includere la dipendenza
spring-cloud-starter-netflix-eureka-client, configurare ilapplication.ymle abilitare il client con l’annotazione@EnableEurekaClient. -
Avvio e Verifica:
-
Avviare l’Eureka Server.
-
Avviare i microservizi client.
-
Accedere alla dashboard di Eureka all’indirizzo
http://localhost:8761per verificare che i client siano registrati correttamente.
-
Best Practices e Considerazioni
Quando si utilizza Spring Cloud per la costruzione di microservizi, è importante seguire alcune best practices per garantire la scalabilità, la manutenibilità e la resilienza del sistema:
-
Centralizzare la Configurazione: Utilizzare Spring Cloud Config per mantenere le configurazioni centralizzate e gestibili, facilitando le modifiche senza dover ridistribuire i servizi.
-
Implementare il Service Discovery: Adottare un service registry come Eureka per permettere ai microservizi di trovare e comunicare tra loro in modo dinamico, riducendo le dipendenze hard-coded.
-
Gestire il Bilanciamento del Carico: Utilizzare Ribbon o Spring Cloud LoadBalancer per distribuire le richieste tra le diverse istanze di un servizio, migliorando la distribuzione del carico e la disponibilità.
-
Aggiungere Resilienza con Circuit Breaker: Implementare Hystrix o altre soluzioni di circuit breaking per prevenire il cascamento degli errori e migliorare la resilienza del sistema in caso di guasti parziali.
-
Utilizzare un API Gateway: Adottare Spring Cloud Gateway per gestire il routing, la sicurezza e altre funzionalità trasversali, centralizzando l’accesso ai microservizi.
-
Monitorare e Tracciare le Richieste: Integrare strumenti come Spring Cloud Sleuth e Zipkin per monitorare il flusso delle richieste attraverso i microservizi, facilitando il debugging e l’ottimizzazione delle performance.
-
Automatizzare il Deployment: Utilizzare containerizzazione (Docker) e orchestrazione (Kubernetes) per semplificare il deployment e la gestione dei microservizi in ambienti di produzione.
Conclusione
Spring Cloud si rivela un alleato indispensabile nella costruzione di architetture a microservizi, offrendo una vasta gamma di strumenti e soluzioni per affrontare le sfide della scalabilità, della resilienza e della gestione distribuita. Comprendere e sfruttare appieno le potenzialità di Spring Cloud permette agli sviluppatori di creare sistemi robusti, facilmente manutenibili e pronti a crescere con le esigenze del business.
Esempio Completo: Configurazione di Spring Cloud Config Server e Client
Per illustrare concretamente l’utilizzo di Spring Cloud, vediamo un esempio di configurazione di un Config Server e di un Config Client.
-
Config Server:
- Aggiungere le dipendenze nel
pom.xml:
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency> </dependencies>- Configurare l’applicazione
application.yml:
server: port: 8888 spring: cloud: config: server: git: uri: https://github.com/tuo-username/tuo-repo-config clone-on-start: true- Abilitare Config Server nel main application class:
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.config.server.EnableConfigServer; @SpringBootApplication @EnableConfigServer public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class, args); } } - Aggiungere le dipendenze nel
-
Config Client:
- Aggiungere le dipendenze nel
pom.xml:
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-config</artifactId> </dependency> </dependencies>- Configurare l’applicazione
bootstrap.yml:
spring: application: name: mio-servizio cloud: config: uri: http://localhost:8888- Avviare il Config Server e il Config Client: Il client scaricherà automaticamente le configurazioni dal server al momento dell’avvio.
- Aggiungere le dipendenze nel
Questo esempio dimostra come centralizzare la gestione delle configurazioni, semplificando la manutenzione e la coerenza delle proprietà tra diversi ambienti e servizi.
Attraverso l’adozione di Spring Cloud, gli sviluppatori possono concentrarsi maggiormente sulla logica di business, delegando a Spring le complessità legate alla gestione dell’infrastruttura distribuita. Questo approccio non solo accelera lo sviluppo, ma garantisce anche una maggiore affidabilità e scalabilità delle applicazioni.
17.3 Comunicazione tra Servizi
In un’architettura a microservizi, i diversi servizi devono comunicare tra loro in modo efficiente, affidabile e scalabile. La comunicazione tra servizi può avvenire tramite vari protocolli e meccanismi, ma due concetti fondamentali per gestire questa interazione sono Service Discovery e Load Balancing. In questa sezione esploreremo come implementare questi concetti utilizzando Eureka per la scoperta dei servizi e Ribbon per il bilanciamento del carico, entrambi componenti del Spring Cloud.
17.3.1 Service Discovery con Eureka
Service Discovery è un meccanismo che permette ai servizi di registrarsi e scoprire automaticamente altri servizi all’interno di un’architettura distribuita. Questo elimina la necessità di configurare manualmente gli indirizzi dei servizi, facilitando la scalabilità e la gestione dinamica delle istanze.
Eureka è un servizio di discovery sviluppato da Netflix e integrato in Spring Cloud. Consiste principalmente di due componenti:
-
Eureka Server: Un server centrale dove i servizi si registrano e da cui possono scoprire altri servizi.
-
Eureka Client: I microservizi che si registrano al server Eureka e che possono cercare altri servizi registrati.
17.3.1.1 Configurazione di Eureka Server
-
Creazione del Progetto Eureka Server:
-
Utilizza Spring Initializr per creare un nuovo progetto Spring Boot.
-
Aggiungi la dipendenza Eureka Server (
spring-cloud-starter-netflix-eureka-server).
-
-
Configurazione del Server:
- Nella classe principale, abilita Eureka Server con l’annotazione
@EnableEurekaServer.
package com.example.eurekaserver; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication @EnableEurekaServer public class EurekaServerApplication { public static void main(String[] args) { SpringApplication.run(EurekaServerApplication.class, args); } } - Nella classe principale, abilita Eureka Server con l’annotazione
-
Configurazione di
application.yml:server: port: 8761 eureka: client: register-with-eureka: false fetch-registry: false server: enable-self-preservation: false spring: application: name: eureka-server -
Avvio del Server:
- Avvia l’applicazione e accedi alla dashboard di Eureka all’indirizzo
http://localhost:8761.
- Avvia l’applicazione e accedi alla dashboard di Eureka all’indirizzo
17.3.1.2 Configurazione di Eureka Client
-
Creazione del Progetto Eureka Client:
- Crea un nuovo progetto Spring Boot con la dipendenza Eureka Discovery Client (
spring-cloud-starter-netflix-eureka-client).
- Crea un nuovo progetto Spring Boot con la dipendenza Eureka Discovery Client (
-
Configurazione del Client:
- Nel file
application.yml, configura il client per registrarsi al server Eureka.
server: port: 8080 eureka: client: service-url: defaultZone: http://localhost:8761/eureka/ instance: prefer-ip-address: true spring: application: name: microservice-example - Nel file
-
Abilitazione del Client:
- Nella classe principale, aggiungi l’annotazione
@EnableEurekaClient.
package com.example.microservice; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication @EnableEurekaClient public class MicroserviceApplication { public static void main(String[] args) { SpringApplication.run(MicroserviceApplication.class, args); } } - Nella classe principale, aggiungi l’annotazione
-
Verifica della Registrazione:
- Avvia l’applicazione client e verifica che sia registrata nella dashboard di Eureka.
17.3.2 Load Balancing con Ribbon
Load Balancing distribuisce le richieste in ingresso su diverse istanze di un servizio, migliorando la distribuzione del carico e aumentando la disponibilità e la resilienza dell’applicazione.
Ribbon è un client-side load balancer fornito da Netflix e integrato in Spring Cloud. Ribbon seleziona dinamicamente l’istanza del servizio a cui indirizzare la richiesta, basandosi su diversi algoritmi di bilanciamento del carico come Round Robin, Availability Filtering e Response Time Weighted.
17.3.2.1 Configurazione di Ribbon in un Client
-
Aggiunta delle Dipendenze:
- Assicurati che il progetto abbia la dipendenza
spring-cloud-starter-netflix-ribbon.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-ribbon</artifactId> </dependency> - Assicurati che il progetto abbia la dipendenza
-
Utilizzo di Ribbon con RestTemplate:
- Configura un
RestTemplatebilanciato con Ribbon.
package com.example.client; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; @Configuration public class AppConfig { @Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); } } @RestController public class ClientController { @Autowired private RestTemplate restTemplate; @GetMapping("/call-service") public String callService() { // "microservice-example" è il nome del servizio registrato in Eureka return restTemplate.getForObject("http://microservice-example/hello", String.class); } } - Configura un
-
Implementazione del Servizio Destinatario:
- Nel servizio che riceve la richiesta (
microservice-example), definisci un endpoint/hello.
package com.example.microservice; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; @RestController public class HelloController { @GetMapping("/hello") public String sayHello() { return "Ciao dal Microservizio!"; } } - Nel servizio che riceve la richiesta (
-
Test del Bilanciamento del Carico:
-
Avvia più istanze del microservizio destinatario (es. su porte diverse).
-
Quando si effettua una chiamata a
/call-service, Ribbon distribuisce le richieste tra le diverse istanze in base all’algoritmo configurato.
-
17.3.2.2 Configurazione Avanzata di Ribbon
Ribbon permette di personalizzare il comportamento del bilanciamento del carico attraverso configurazioni specifiche. È possibile definire regole di bilanciamento, timeout, retry e altre proprietà per adattare Ribbon alle esigenze specifiche dell’applicazione.
Esempio di Configurazione Personalizzata di Ribbon:
# application.yml del client
microservice-example:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
ConnectTimeout: 3000
ReadTimeout: 5000
MaxAutoRetries: 1
MaxAutoRetriesNextServer: 2In questo esempio:
-
RandomRule: Ribbon seleziona casualmente un’istanza del servizio. -
ConnectTimeouteReadTimeout: Definiscono i timeout per le connessioni e le letture. -
MaxAutoRetrieseMaxAutoRetriesNextServer: Configurano il numero di tentativi di retry in caso di errori.
17.3.3 Alternative Moderne a Ribbon
È importante notare che Ribbon è stato deprecato in favore di soluzioni più recenti come Spring Cloud LoadBalancer. Sebbene Ribbon sia ancora utilizzabile, si consiglia di adottare Spring Cloud LoadBalancer per nuove implementazioni, in quanto offre un’integrazione più stretta con le funzionalità di Spring e riceve aggiornamenti più recenti.
17.3.3.1 Spring Cloud LoadBalancer
Spring Cloud LoadBalancer fornisce un meccanismo di bilanciamento del carico lato client integrato con le funzionalità di Spring, supportando diversi algoritmi e facilitando la configurazione attraverso le proprietà di Spring.
Configurazione di Spring Cloud LoadBalancer:
-
Aggiunta delle Dipendenze:
- Includi
spring-cloud-starter-loadbalancernel progetto.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> - Includi
-
Utilizzo con RestTemplate:
- Configura un
RestTemplatebilanciato come mostrato in precedenza, ma senza necessità di Ribbon.
@Bean @LoadBalanced public RestTemplate restTemplate() { return new RestTemplate(); } - Configura un
-
Scelta dell’Algoritmo di Bilanciamento:
- Spring Cloud LoadBalancer utilizza Round Robin per impostazione predefinita, ma supporta anche altre strategie.
spring: cloud: loadbalancer: ribbon: enabled: false # Disabilita Ribbon se presente default: strategy: round_robin
17.3.4 Comunicazione Sincrona vs Asincrona
La comunicazione tra microservizi può avvenire in modalità sincrona o asincrona, ciascuna con i propri vantaggi e scenari di utilizzo.
-
Comunicazione Sincrona:
-
Utilizza protocolli come HTTP/REST.
-
Ideale per operazioni che richiedono una risposta immediata.
-
Semplice da implementare ma può introdurre dipendenze strette tra servizi.
-
-
Comunicazione Asincrona:
-
Utilizza code di messaggi come RabbitMQ, Kafka o ActiveMQ.
-
Migliora la resilienza e la scalabilità, permettendo ai servizi di operare in modo indipendente.
-
Adatto per operazioni che possono essere gestite in modo differito.
-
Esempio di Comunicazione Asincrona con RabbitMQ:
-
Aggiunta delle Dipendenze:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> -
Configurazione di RabbitMQ:
spring: rabbitmq: host: localhost port: 5672 username: guest password: guest -
Definizione di Producer e Consumer:
// Producer @Service public class MessageProducer { @Autowired private RabbitTemplate rabbitTemplate; public void sendMessage(String message) { rabbitTemplate.convertAndSend("exchange", "routingKey", message); } } // Consumer @Service public class MessageConsumer { @RabbitListener(queues = "queueName") public void receiveMessage(String message) { System.out.println("Ricevuto: " + message); } } -
Definizione delle Code e degli Exchange:
@Configuration public class RabbitConfig { @Bean public Queue queue() { return new Queue("queueName", false); } @Bean public DirectExchange exchange() { return new DirectExchange("exchange"); } @Bean public Binding binding(Queue queue, DirectExchange exchange) { return BindingBuilder.bind(queue).to(exchange).with("routingKey"); } }
17.3.5 Best Practices nella Comunicazione tra Servizi
-
Idempotenza: Progettare le API in modo che le richieste multiple abbiano lo stesso effetto della singola richiesta.
-
Timeout e Retry: Implementare timeout appropriati e meccanismi di retry per gestire fallimenti temporanei.
-
Circuit Breaker: Utilizzare pattern come Circuit Breaker (es. con Hystrix o Resilience4j) per prevenire il fallimento a cascata dei servizi.
-
Monitoraggio e Logging: Implementare strumenti di monitoraggio e logging per tracciare le comunicazioni e identificare eventuali problemi.
-
Sicurezza: Proteggere le comunicazioni tra servizi utilizzando protocolli sicuri (es. HTTPS) e meccanismi di autenticazione/autorizzazione.
17.3.6 Esempio Completo: Implementazione di Service Discovery e Load Balancing
Di seguito un esempio pratico che combina Eureka per la scoperta dei servizi e Spring Cloud LoadBalancer per il bilanciamento del carico.
-
Eureka Server:
-
Configurato come descritto nella sezione 17.3.1.1.
-
Avviato su
localhost:8761.
-
-
Microservizio Provider (
microservice-provider):-
Configurato come Eureka Client.
-
Definisce un endpoint
/hello.
@RestController public class HelloController { @GetMapping("/hello") public String sayHello() { return "Ciao dal Provider!"; } } -
-
Microservizio Consumer (
microservice-consumer):-
Configurato come Eureka Client e utilizza
RestTemplatebilanciato. -
Chiamata all’endpoint
/hellodel provider.
@RestController public class ConsumerController { @Autowired private RestTemplate restTemplate; @GetMapping("/consume") public String consume() { return restTemplate.getForObject("http://microservice-provider/hello", String.class); } } -
-
Avvio e Test:
-
Avvia più istanze di
microservice-providersu porte diverse (es. 8081, 8082). -
Avvia
microservice-consumer. -
Effettua chiamate a
http://localhost:8080/consumee verifica che le richieste vengano distribuite tra le diverse istanze del provider.
-
Conclusione
La comunicazione efficace tra microservizi è cruciale per il successo di un’architettura distribuita. Utilizzando strumenti come Eureka per la scoperta dei servizi e Ribbon o Spring Cloud LoadBalancer per il bilanciamento del carico, è possibile costruire sistemi scalabili, resilienti e facili da gestire. È importante anche considerare l’adozione di pattern e best practices per garantire la robustezza e la sicurezza delle interazioni tra i servizi.
Capitolo 18: Evoluzione da Spring Boot 2 a Spring Boot 3
18.1 Principali Cambiamenti
Con l’introduzione di Spring Boot 3, sono stati apportati numerosi aggiornamenti significativi rispetto alla versione precedente, Spring Boot 2. Questi cambiamenti mirano a migliorare le prestazioni, la sicurezza, la compatibilità con le ultime tecnologie e a semplificare lo sviluppo di applicazioni moderne. In questa sezione, esploreremo i principali cambiamenti introdotti in Spring Boot 3, evidenziando le nuove funzionalità e gli aggiornamenti che rendono questa versione un’evoluzione sostanziale rispetto a Spring Boot 2.
1. Migrazione a Jakarta EE 9
Uno dei cambiamenti più rilevanti in Spring Boot 3 è la migrazione delle API Java EE a Jakarta EE 9. Questa transizione comporta un cambiamento significativo nei namespace delle librerie, passando da javax.* a jakarta.*.
Perché è importante:
-
Compatibilità: Garantisce che le applicazioni siano allineate con gli standard più recenti, facilitando l’integrazione con nuove tecnologie e framework.
-
Evoluzione del Linguaggio: Consente di sfruttare le ultime innovazioni e miglioramenti di Jakarta EE.
Esempio di aggiornamento:
Supponiamo di avere un’applicazione Spring Boot 2 che utilizza le servlet di Java EE:
Spring Boot 2 (Java EE):
import javax.servlet.http.HttpServlet;
public class MyServlet extends HttpServlet {
// Implementazione
}Spring Boot 3 (Jakarta EE):
import jakarta.servlet.http.HttpServlet;
public class MyServlet extends HttpServlet {
// Implementazione
}2. Requisiti di Java Aggiornati
Spring Boot 3 richiede Java 17 come versione minima, abbandonando il supporto per versioni precedenti come Java 8 o Java 11. Questo aggiornamento consente agli sviluppatori di sfruttare le ultime funzionalità del linguaggio e miglioramenti delle prestazioni introdotti nelle versioni più recenti di Java.
Perché è importante:
-
Nuove Funzionalità: Accesso a funzionalità moderne di Java come pattern matching, records, e miglioramenti delle API.
-
Miglioramenti delle Prestazioni: Ottimizzazioni della JVM e del linguaggio che migliorano l’efficienza delle applicazioni.
Esempio di utilizzo di Records in Java 17:
Spring Boot 2 (Java 11):
public class User {
private final String name;
private final int age;
// Costruttore, getter, etc.
}Spring Boot 3 (Java 17):
public record User(String name, int age) {}3. Supporto Nativo e GraalVM
Spring Boot 3 offre un supporto nativo migliorato per la compilazione con GraalVM, consentendo di creare eseguibili nativi che avviano più rapidamente e consumano meno risorse rispetto alle tradizionali applicazioni JVM.
Perché è importante:
-
Performance Migliorata: Tempi di avvio ridotti e minore consumo di memoria, ideali per ambienti cloud e containerizzati.
-
Efficienza Operativa: Eseguibili nativi semplificano il deployment e la gestione delle applicazioni.
Esempio di configurazione per GraalVM:
Aggiungere il plugin Spring Boot per GraalVM nel pom.xml:
<dependency>
<groupId>org.springframework.experimental</groupId>
<artifactId>spring-graalvm-native</artifactId>
<version>0.11.1</version>
</dependency>Eseguire la build nativa:
./mvnw spring-boot:build-image -Dspring-boot.build-image.imageName=myapp:latest4. Miglioramenti all’Osservabilità con Micrometer
Spring Boot 3 integra Micrometer in modo più approfondito, offrendo migliori strumenti di monitoraggio e metriche. Sono stati aggiunti nuovi registri e integrazioni con sistemi di monitoraggio moderni.
Perché è importante:
-
Monitoraggio Avanzato: Consente di tracciare meglio le prestazioni e la salute delle applicazioni.
-
Integrazione Facilitata: Compatibilità con piattaforme di monitoraggio come Prometheus, Grafana, e altri strumenti di osservabilità.
Esempio di configurazione di Micrometer:
Aggiungere le dipendenze nel pom.xml:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>Configurare l’esportazione delle metriche in application.properties:
management.endpoints.web.exposure.include=prometheus
management.metrics.export.prometheus.enabled=true
5. Allineamento con Spring Framework 6
Spring Boot 3 è strettamente allineato con Spring Framework 6, garantendo una coerenza nelle API e nelle funzionalità. Questo allineamento facilita l’adozione di nuove caratteristiche e migliora la stabilità delle applicazioni.
Perché è importante:
-
Coerenza: Un’unica base di codice e API rende più semplice lo sviluppo e la manutenzione.
-
Aggiornamenti Semplificati: Riduce i conflitti e le incompatibilità tra Spring Boot e Spring Framework.
Esempio di utilizzo di nuove funzionalità di Spring Framework 6:
Utilizzo delle nuove annotazioni per la configurazione dei bean:
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyServiceImpl();
}
}6. Rimozione delle Funzionalità Deprecate
Spring Boot 3 ha eliminato molte funzionalità deprecate presenti in Spring Boot 2, semplificando l’architettura e migliorando la sicurezza. Questa pulizia del codice rimuove componenti obsoleti e riduce la complessità.
Perché è importante:
-
Sicurezza e Manutenibilità: Rimuovere codice obsoleto riduce la superficie di attacco e facilita la manutenzione.
-
Prestazioni Migliorate: Codice più snello e ottimizzato contribuisce a migliori prestazioni.
Esempio di rimozione di configurazioni deprecate:
In Spring Boot 2, si poteva configurare una proprietà in application.properties in modo diverso:
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
In Spring Boot 3, si utilizza una configurazione più diretta:
spring.datasource.hikari.maximum-pool-size=20
7. Miglioramenti alla Configurazione e al Profiling
Spring Boot 3 introduce miglioramenti significativi nella gestione delle configurazioni e dei profili, rendendo più semplice personalizzare le applicazioni per diversi ambienti.
Perché è importante:
-
Flessibilità: Facilita la gestione di configurazioni complesse e ambienti diversi.
-
Scalabilità: Migliora la capacità di adattare le applicazioni a diverse esigenze operative.
Esempio di utilizzo dei profili:
Definire configurazioni specifiche per l’ambiente di sviluppo e produzione:
# application-dev.properties
spring.datasource.url=jdbc:h2:mem:devdb
# application-prod.properties
spring.datasource.url=jdbc:mysql://prodserver:3306/proddb
Avviare l’applicazione con un profilo specifico:
java -jar myapp.jar --spring.profiles.active=prod8. Supporto Avanzato per Kotlin e Programmazione Funzionale
Spring Boot 3 migliora il supporto per Kotlin, facilitando lo sviluppo di applicazioni funzionali e reattive. Le API di Kotlin sono integrate più profondamente, offrendo una migliore esperienza di sviluppo.
Perché è importante:
-
Modernità: Sfrutta i paradigmi di programmazione funzionale e le caratteristiche avanzate di Kotlin.
-
Produttività: Riduce il boilerplate code e semplifica la scrittura di codice conciso e leggibile.
Esempio di utilizzo di Kotlin con Spring Boot 3:
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RestController
@SpringBootApplication
class MyApplication
fun main(args: Array<String>) {
runApplication<MyApplication>(*args)
}
@RestController
class GreetingController {
@GetMapping("/greet")
fun greet() = "Hello, Kotlin!"
}9. Aggiornamenti ai Server Embedded
Spring Boot 3 aggiorna i server embedded come Tomcat, Jetty e Undertow alle ultime versioni, offrendo migliori prestazioni, sicurezza e supporto per le nuove funzionalità del protocollo HTTP/2 e HTTP/3.
Perché è importante:
-
Prestazioni Migliorate: Versioni aggiornate dei server offrono ottimizzazioni delle prestazioni e minore latenza.
-
Sicurezza: Le ultime versioni includono patch di sicurezza e miglioramenti.
Esempio di configurazione di Tomcat aggiornato:
Aggiungere la dipendenza aggiornata nel pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<version>3.0.0</version>
</dependency>Configurare le proprietà di Tomcat in application.properties:
server.tomcat.max-threads=200
server.tomcat.accesslog.enabled=true
10. Miglioramenti nella Sicurezza
Spring Boot 3 introduce nuove funzionalità di sicurezza e migliora quelle esistenti, rendendo più semplice implementare meccanismi di autenticazione e autorizzazione robusti.
Perché è importante:
-
Protezione Avanzata: Implementa le migliori pratiche di sicurezza per proteggere le applicazioni da minacce comuni.
-
Facilità d’Uso: Configurazioni semplificate per implementare soluzioni di sicurezza complesse.
Esempio di configurazione di Spring Security:
Configurare una sicurezza di base con Spring Security:
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.web.SecurityFilterChain;
@Configuration
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authz -> authz
.anyRequest().authenticated()
)
.formLogin(withDefaults());
return http.build();
}
}Conclusione
La transizione da Spring Boot 2 a Spring Boot 3 rappresenta un significativo passo avanti nell’evoluzione del framework, offrendo miglioramenti sostanziali in termini di prestazioni, sicurezza, supporto tecnologico e facilità di sviluppo. Adottare Spring Boot 3 permette agli sviluppatori di sfruttare le ultime innovazioni e di costruire applicazioni più robuste, scalabili e mantenibili. È essenziale comprendere questi cambiamenti per poter migrare efficacemente le applicazioni esistenti e per sfruttare appieno le potenzialità della nuova versione.
18.2 Migrazione delle Applicazioni
La migrazione da Spring Boot 2 a Spring Boot 3 rappresenta un passo significativo per sfruttare le ultime innovazioni, miglioramenti delle prestazioni e nuove funzionalità offerte dal framework. Questa sezione fornisce una guida dettagliata e passo-passo per aggiornare le applicazioni esistenti, affrontando le modifiche principali e risolvendo i problemi comuni che possono emergere durante il processo.
18.2.1 Preparazione alla Migrazione
Prima di iniziare la migrazione, è fondamentale eseguire alcune operazioni preparatorie per assicurare un aggiornamento senza intoppi.
-
Backup del Codice Esistente:
-
Motivazione: Proteggere il codice attuale consente di ripristinare una versione funzionante in caso di problemi durante la migrazione.
-
Azione: Utilizzare un sistema di controllo versione (ad es., Git) per creare un branch separato dedicato alla migrazione.
-
-
Aggiornamento delle Dipendenze:
-
Motivazione: Verificare che tutte le dipendenze siano compatibili con Spring Boot 3.
-
Azione: Consultare la documentazione ufficiale per identificare le versioni compatibili delle librerie utilizzate.
-
-
Revisione delle Note di Rilascio:
-
Motivazione: Le note di rilascio contengono informazioni cruciali sulle modifiche, deprecazioni e nuove funzionalità.
-
Azione: Esaminare attentamente le note di rilascio di Spring Boot 3 per comprendere le principali differenze rispetto alla versione 2.
-
18.2.2 Aggiornamento del File di Configurazione del Progetto
Il primo passo pratico nella migrazione consiste nell’aggiornare il file di configurazione del progetto (ad es., pom.xml per Maven o build.gradle per Gradle) per utilizzare le versioni compatibili di Spring Boot e Java.
Maven (pom.xml):
-
Aggiornamento della Versione di Spring Boot:
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.0.0</version> <relativePath/> <!-- lookup parent from repository --> </parent> -
Aggiornamento del
java.version:<properties> <java.version>17</java.version> </properties> -
Revisione delle Dipendenze:
-
Motivazione: Alcune dipendenze potrebbero essere deprecate o sostituite.
-
Azione: Aggiornare le versioni delle dipendenze e rimuovere quelle non più supportate.
<dependencies> <!-- Esempio: aggiornamento di Spring Data JPA --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> <version>3.0.0</version> </dependency> <!-- Altre dipendenze aggiornate --> </dependencies> -
Gradle (build.gradle):
-
Aggiornamento della Versione di Spring Boot:
plugins { id 'org.springframework.boot' version '3.0.0' id 'io.spring.dependency-management' version '1.1.0' id 'java' } -
Aggiornamento del
sourceCompatibility:java { sourceCompatibility = JavaVersion.VERSION_17 targetCompatibility = JavaVersion.VERSION_17 } -
Revisione delle Dipendenze:
dependencies { implementation 'org.springframework.boot:spring-boot-starter-data-jpa:3.0.0' // Altre dipendenze aggiornate }
18.2.3 Adattamento al Nuovo Modello di Configurazione
Spring Boot 3 introduce alcune modifiche significative nel modo in cui le applicazioni sono configurate e gestite. È essenziale adattare il codice esistente per allinearsi a questi cambiamenti.
-
Migrazione a Jakarta EE:
-
Motivazione: A partire da Spring Boot 3, molte dipendenze Java EE sono state spostate sotto l’ombrello di Jakarta EE, con un cambiamento di package da
javax.*ajakarta.*. -
Azione: Aggiornare gli import nel codice sorgente.
// Prima (Spring Boot 2) import javax.persistence.Entity; // Dopo (Spring Boot 3) import jakarta.persistence.Entity; -
-
Aggiornamento delle Annotazioni:
-
Motivazione: Alcune annotazioni potrebbero essere state modificate o sostituite.
-
Azione: Verificare e aggiornare le annotazioni secondo le nuove specifiche di Spring Boot 3.
// Prima @RestController public class MyController { ... } // Dopo (se necessario, verificare eventuali cambiamenti) @RestController public class MyController { ... } -
-
Rimozione delle API Deprecate:
-
Motivazione: Le API deprecate in Spring Boot 2 potrebbero essere rimosse in Spring Boot 3.
-
Azione: Identificare e sostituire l’uso di API deprecate con alternative supportate.
// Prima (uso di un'API deprecata) @Autowired private OldService oldService; // Dopo (sostituzione con una nuova API) @Autowired private NewService newService; -
18.2.4 Risoluzione delle Dipendenze e dei Conflitti
Durante la migrazione, è comune incontrare conflitti di dipendenze o incompatibilità. Seguire questi passaggi per risolverli:
-
Verifica delle Dipendenze Transitiva:
-
Motivazione: Alcune dipendenze potrebbero tirare dentro versioni incompatibili di librerie.
-
Azione: Utilizzare strumenti come
mvn dependency:tree(Maven) o./gradlew dependencies(Gradle) per analizzare l’albero delle dipendenze e identificare conflitti.
-
-
Esclusione delle Dipendenze Incompatibili:
-
Motivazione: Rimuovere le dipendenze problematiche per evitare conflitti.
-
Azione: Escludere le dipendenze problematiche nel file di configurazione.
<!-- Esempio Maven --> <dependency> <groupId>com.example</groupId> <artifactId>example-library</artifactId> <version>1.0.0</version> <exclusions> <exclusion> <groupId>org.old</groupId> <artifactId>old-dependency</artifactId> </exclusion> </exclusions> </dependency> -
-
Aggiornamento Manuale delle Versioni:
-
Motivazione: Alcune librerie potrebbero richiedere una versione specifica per essere compatibili con Spring Boot 3.
-
Azione: Specificare manualmente le versioni delle dipendenze nel file di configurazione.
<!-- Esempio Maven --> <dependencyManagement> <dependencies> <dependency> <groupId>org.some</groupId> <artifactId>some-library</artifactId> <version>2.0.0</version> </dependency> </dependencies> </dependencyManagement> -
18.2.5 Testing e Validazione
Una volta completati gli aggiornamenti, è essenziale testare l’applicazione per garantire che tutto funzioni correttamente.
-
Esecuzione dei Test Unitari e di Integrazione:
-
Motivazione: Verificare che le modifiche non abbiano introdotto regressioni.
-
Azione: Eseguire tutti i test esistenti e risolvere eventuali fallimenti.
# Maven mvn clean test # Gradle ./gradlew clean test -
-
Verifica del Comportamento dell’Applicazione:
-
Motivazione: Assicurarsi che le funzionalità chiave siano operative.
-
Azione: Eseguire manualmente scenari di utilizzo critici e monitorare il comportamento dell’applicazione.
-
-
Utilizzo di Strumenti di Analisi Statico:
-
Motivazione: Identificare potenziali problemi nel codice.
-
Azione: Integrare strumenti come SonarQube o SpotBugs per analizzare il codice e risolvere le segnalazioni.
-
18.2.6 Risoluzione dei Problemi Comuni
Durante la migrazione, possono emergere vari problemi. Di seguito sono riportate alcune delle sfide più comuni e come affrontarle.
-
Errore di Compatibilità con Java:
-
Sintomo: L’applicazione non si avvia o genera errori durante la compilazione.
-
Soluzione: Verificare che la versione di Java specificata nel progetto corrisponda a quella richiesta da Spring Boot 3 (Java 17 o superiore). Aggiornare la versione di Java se necessario.
-
-
Problemi con le Annotazioni di Persistenza:
-
Sintomo: Le entità JPA non vengono riconosciute correttamente.
-
Soluzione: Assicurarsi di aver aggiornato gli import da
javax.persistence.*ajakarta.persistence.*e verificare la configurazione di Hibernate.
-
-
Incompatibilità delle Dipendenze Esterne:
-
Sintomo: Errori di runtime dovuti a librerie esterne non compatibili.
-
Soluzione: Verificare la compatibilità delle librerie esterne con Spring Boot 3 e aggiornare o sostituire le librerie problematiche.
-
-
Problemi di Configurazione di Spring Security:
-
Sintomo: Autenticazione o autorizzazione non funzionano correttamente.
-
Soluzione: Rivedere le configurazioni di Spring Security alla luce delle modifiche introdotte in Spring Boot 3, adattando eventuali configurazioni personalizzate.
-
18.2.7 Best Practices per una Migrazione di Successo
Per garantire una migrazione efficace e ridurre al minimo i rischi, è consigliabile seguire alcune best practices:
-
Migrazione Incrementale:
-
Motivazione: Aggiornare gradualmente i componenti dell’applicazione permette di isolare e risolvere i problemi più facilmente.
-
Azione: Dividere la migrazione in piccoli passi, aggiornando una funzionalità o un modulo alla volta.
-
-
Automatizzazione del Processo di Build:
-
Motivazione: Automatizzare la build e i test consente di rilevare rapidamente eventuali regressioni.
-
Azione: Integrare strumenti di CI/CD (ad es., Jenkins, GitHub Actions) per eseguire build e test automatici ad ogni commit.
-
-
Documentazione delle Modifiche:
-
Motivazione: Tenere traccia delle modifiche facilita la risoluzione dei problemi e la comprensione delle decisioni prese durante la migrazione.
-
Azione: Documentare ogni passo significativo, inclusi aggiornamenti delle dipendenze, modifiche al codice e soluzioni ai problemi riscontrati.
-
-
Coinvolgimento del Team:
-
Motivazione: La collaborazione e la condivisione delle conoscenze all’interno del team migliorano l’efficacia della migrazione.
-
Azione: Organizzare sessioni di revisione del codice e condividere le best practices emerse durante il processo.
-
18.2.8 Esempio Pratico di Migrazione
Per illustrare concretamente il processo di migrazione, consideriamo un’applicazione Spring Boot 2 che utilizza Spring Data JPA e Spring Security.
Passo 1: Aggiornamento del pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/>
</parent>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<!-- Spring Boot Starter Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- Spring Security -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<!-- Database Driver -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Altre dipendenze -->
</dependencies>Passo 2: Aggiornamento degli Import nelle Entità
// Prima (Spring Boot 2)
import javax.persistence.Entity;
import javax.persistence.Id;
// Dopo (Spring Boot 3)
import jakarta.persistence.Entity;
import jakarta.persistence.Id;Passo 3: Revisione della Configurazione di Spring Security
Supponiamo di avere una configurazione di sicurezza personalizzata in Spring Boot 2:
// Spring Boot 2
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/public/**").permitAll()
.anyRequest().authenticated()
.and()
.formLogin();
}
}In Spring Boot 3, WebSecurityConfigurerAdapter è deprecato. La configurazione deve essere aggiornata utilizzando il nuovo approccio basato sui bean:
// Spring Boot 3
@Configuration
@EnableWebSecurity
public class SecurityConfig {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(authorize -> authorize
.requestMatchers("/public/**").permitAll()
.anyRequest().authenticated()
)
.formLogin(withDefaults());
return http.build();
}
}Passo 4: Esecuzione dei Test e Validazione
-
Eseguire i Test Unitari:
mvn clean test- Verificare che tutti i test passino e risolvere eventuali fallimenti.
-
Avviare l’Applicazione:
mvn spring-boot:run- Accedere ai vari endpoint per assicurarsi che l’applicazione funzioni come previsto.
-
Monitorare i Log:
- Verificare i log dell’applicazione per identificare eventuali errori o avvisi.
18.2.9 Conclusioni
La migrazione da Spring Boot 2 a Spring Boot 3, seppur complessa, offre numerosi vantaggi in termini di performance, sicurezza e accesso a nuove funzionalità. Seguendo una strategia metodica e adottando le best practices descritte in questa sezione, è possibile effettuare un aggiornamento efficace minimizzando i rischi e garantendo la continuità operativa dell’applicazione.
Ricordarsi di:
-
Pianificare attentamente ogni fase della migrazione.
-
Testare approfonditamente l’applicazione dopo ogni modifica significativa.
-
Consultare la documentazione ufficiale e la community di Spring per supporto e aggiornamenti.
Con una migrazione ben eseguita, la tua applicazione potrà beneficiare delle ultime innovazioni offerte da Spring Boot 3, migliorando la sua scalabilità, sicurezza e manutenibilità.
18.3 Supporto per Java 17 e Jakarta EE
Implicazioni dell’Aggiornamento delle Dipendenze
Con l’evoluzione di Spring Boot dalla versione 2 alla versione 3, è emersa la necessità di allinearsi con le ultime versioni di Java e delle specifiche enterprise. In particolare, Spring Boot 3 richiede Java 17 come versione minima e adotta Jakarta EE al posto di Java EE. Questa sezione esplora le implicazioni di tali aggiornamenti, analizzando le nuove funzionalità di Java 17 e il passaggio a Jakarta EE, nonché come questi cambiamenti influenzano le dipendenze delle applicazioni.
18.3.1 Java 17: Nuove Funzionalità e Miglioramenti
Java 17, rilasciato come Long-Term Support (LTS), introduce diverse nuove funzionalità e miglioramenti delle prestazioni che possono essere sfruttati nelle applicazioni Spring Boot 3. Alcune delle principali novità includono:
-
Pattern Matching for
switch(Preview): Migliora la leggibilità e la manutenzione del codice consentendo una sintassi più concisa per le istruzioniswitch. -
Sealed Classes: Permettono di controllare quali classi possono estendere o implementare una determinata classe o interfaccia, aumentando la sicurezza e l’incapsulamento.
-
Record Types: Offrono una sintassi compatta per dichiarare classi immutabili che fungono da semplici contenitori di dati.
-
Performance Enhancements: Ottimizzazioni della JVM che migliorano le prestazioni generali delle applicazioni.
Esempio: Utilizzo dei Record Types in Java 17
// Dichiarazione di un record per rappresentare un utente
public record User(Long id, String name, String email) {}
// Utilizzo del record
public class UserService {
public User getUserById(Long id) {
// Logica per recuperare l'utente
return new User(id, "Mario Rossi", "mario.rossi@example.com");
}
}I record semplificano la creazione di classi che sono principalmente contenitori di dati, riducendo il boilerplate e migliorando la leggibilità del codice.
18.3.2 Migrating to Jakarta EE
Uno dei cambiamenti più significativi con Spring Boot 3 è il passaggio da Java EE a Jakarta EE. Questo cambiamento implica una riorganizzazione dei pacchetti da javax.* a jakarta.*, il che richiede aggiornamenti alle dipendenze e al codice esistente.
18.3.2.1 Motivazioni del Passaggio a Jakarta EE
Jakarta EE è la continuazione di Java EE sotto la governance della Eclipse Foundation, offrendo una piattaforma aggiornata e modulare per lo sviluppo di applicazioni enterprise. Le principali motivazioni per il passaggio includono:
-
Modernizzazione: Introduzione di nuove specifiche e aggiornamenti per rispondere alle esigenze attuali dello sviluppo software.
-
Flessibilità: Architettura più modulare che facilita l’adozione di nuove tecnologie e l’integrazione con framework moderni.
-
Supporto Continuativo: Jakarta EE continua a evolversi con il supporto della comunità open source, garantendo aggiornamenti regolari e miglioramenti.
18.3.2.2 Implicazioni sul Codice e sulle Dipendenze
Il passaggio a Jakarta EE richiede modifiche sia al codice sorgente che alle dipendenze del progetto. Ecco i passaggi principali per effettuare questa migrazione:
-
Aggiornamento delle Dipendenze Maven/Gradle:
Le dipendenze che utilizzano
javax.*devono essere sostituite con quelle che utilizzanojakarta.*. Ad esempio,javax.servletdiventajakarta.servlet.Esempio: Aggiornamento di una Dipendenza Maven
<!-- Dipendenza Java EE (pre-migrazione) --> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>4.0.1</version> <scope>provided</scope> </dependency> <!-- Dipendenza Jakarta EE (post-migrazione) --> <dependency> <groupId>jakarta.servlet</groupId> <artifactId>jakarta.servlet-api</artifactId> <version>5.0.0</version> <scope>provided</scope> </dependency> -
Modifica del Codice Sorgente:
Aggiornare i pacchetti importati nel codice per riflettere i nuovi namespace
jakarta.*.Esempio: Aggiornamento degli Import nel Codice Java
// Import Java EE (pre-migrazione) import javax.servlet.http.HttpServlet; // Import Jakarta EE (post-migrazione) import jakarta.servlet.http.HttpServlet; -
Verifica delle API Deprecate:
Alcune API potrebbero essere state deprecate o sostituite in Jakarta EE. È necessario verificare e aggiornare il codice per utilizzare le nuove API dove necessario.
-
Testing e Validazione:
Dopo aver effettuato le modifiche, è fondamentale eseguire test approfonditi per assicurarsi che l’applicazione funzioni correttamente con le nuove dipendenze.
18.3.2.3 Strumenti e Risorse per la Migrazione
Esistono diversi strumenti e risorse che possono facilitare il processo di migrazione da Java EE a Jakarta EE:
-
Jakarta EE Migration Tool: Strumenti ufficiali e plugin per Maven/Gradle che automatizzano la sostituzione dei pacchetti
javax.*conjakarta.*. -
Documentazione Ufficiale: La documentazione di Jakarta EE fornisce linee guida dettagliate e best practices per la migrazione.
-
Comunità e Forum: Partecipare a comunità online come Stack Overflow o i forum di Eclipse può offrire supporto e soluzioni a problemi comuni durante la migrazione.
18.3.3 Best Practices per l’Aggiornamento delle Dipendenze
Per garantire una migrazione senza intoppi e mantenere l’integrità dell’applicazione, è consigliabile seguire alcune best practices:
-
Backup del Progetto: Prima di iniziare la migrazione, eseguire un backup completo del progetto o utilizzare un sistema di controllo versione come Git per gestire le modifiche.
-
Aggiornamenti Incrementali: Effettuare aggiornamenti graduali, iniziando dalle dipendenze di base e verificando il funzionamento dell’applicazione a ogni passaggio.
-
Utilizzo di Strumenti di Compatibilità: Utilizzare strumenti come
jdepsper analizzare le dipendenze del progetto e identificare potenziali problemi di compatibilità. -
Test Completi: Implementare una suite di test completa (unitari, di integrazione e funzionali) per rilevare tempestivamente eventuali regressioni o problemi introdotti durante la migrazione.
-
Monitoraggio delle Dipendenze: Utilizzare gestori di dipendenze come Maven o Gradle per mantenere le dipendenze aggiornate e gestire le versioni in modo efficiente.
18.3.4 Esempio Pratico di Migrazione
Per illustrare concretamente il processo di migrazione, consideriamo un semplice progetto Spring Boot 2 che utilizza Java EE e migrarlo a Spring Boot 3 con Java 17 e Jakarta EE.
Passo 1: Aggiornamento del pom.xml
<properties>
<java.version>17</java.version>
<spring.boot.version>3.0.0</spring.boot.version>
</properties>
<dependencies>
<!-- Dipendenza aggiornata a Jakarta EE -->
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<version>5.0.0</version>
<scope>provided</scope>
</dependency>
<!-- Altre dipendenze aggiornate secondo necessità -->
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Passo 2: Aggiornamento degli Import nel Codice Java
// Prima della migrazione
import javax.servlet.http.HttpServlet;
// Dopo la migrazione
import jakarta.servlet.http.HttpServlet;Passo 3: Aggiornamento della Configurazione di Spring Boot
Con Spring Boot 3, alcune configurazioni potrebbero aver subito modifiche. Ad esempio, se si utilizzano proprietà specifiche del server, verificare che siano compatibili con la nuova versione.
# application.yml prima della migrazione
server:
port: 8080
servlet:
context-path: /app
# application.yml dopo la migrazione
server:
port: 8080
servlet:
context-path: /appPasso 4: Esecuzione dei Test
Eseguire tutti i test per assicurarsi che l’applicazione funzioni correttamente con le nuove dipendenze e la versione aggiornata di Java.
mvn clean testPasso 5: Verifica e Debug
In caso di errori, utilizzare i log e strumenti di debug per identificare e risolvere i problemi. Ad esempio, se un’API specifica di Java EE non è più disponibile in Jakarta EE, cercare un’alternativa o una soluzione compatibile.
18.3.5 Considerazioni Finali
L’aggiornamento a Java 17 e il passaggio a Jakarta EE sono passi fondamentali per mantenere le applicazioni Spring Boot aggiornate e sicure. Sebbene il processo di migrazione possa comportare sfide, seguendo le best practices e utilizzando gli strumenti appropriati, è possibile effettuare un aggiornamento efficace minimizzando i rischi e garantendo la continuità operativa dell’applicazione.
Adottare le ultime versioni di Java e Jakarta EE non solo migliora le prestazioni e la sicurezza, ma apre anche la porta a nuove funzionalità e opportunità di sviluppo, rendendo le applicazioni più robuste e mantenibili nel lungo termine.
Capitolo 19: Deployment e Monitoraggio delle Applicazioni
19.1 Packaging e Esecuzione
Introduzione
Il packaging e l’esecuzione delle applicazioni sono fasi cruciali nello sviluppo software, poiché determinano come un’applicazione viene distribuita, eseguita e gestita in diversi ambienti. In questa sezione, esploreremo i concetti fondamentali relativi al packaging delle applicazioni Java e Spring Boot, le diverse tipologie di pacchetti, gli strumenti di build più comuni e le best practices per l’esecuzione efficace delle applicazioni. Comprendere questi aspetti è essenziale per garantire che le applicazioni siano facilmente distribuibili, scalabili e mantenibili.
19.1.1 Tipologie di Packaging in Java
In Java, il packaging si riferisce al processo di aggregazione del codice compilato, delle librerie dipendenti e delle risorse in un unico file o insieme di file che possono essere distribuiti ed eseguiti. Le due tipologie principali di pacchetti sono:
-
JAR (Java ARchive):
-
Descrizione: Un file JAR è un archivio compresso che contiene file
.class(codice compilato Java), risorse come immagini e file di configurazione, e un file di manifest che specifica le informazioni di configurazione del pacchetto. -
Utilizzo: Ideale per applicazioni standalone, librerie e componenti riutilizzabili.
-
Esecuzione: Un JAR eseguibile può essere eseguito tramite il comando
java -jar nomefile.jarse include una classe principale definita nel manifest.
-
-
WAR (Web Application Archive):
-
Descrizione: Un file WAR è un archivio destinato a contenere applicazioni web Java. Include servlet, JSP, librerie, risorse statiche e file di configurazione specifici per le applicazioni web.
-
Utilizzo: Utilizzato principalmente per distribuire applicazioni web su server di applicazioni come Apache Tomcat, Jetty o WildFly.
-
Esecuzione: Il WAR viene distribuito su un server di applicazioni che gestisce l’esecuzione dell’applicazione web.
-
Tabella Comparativa: JAR vs WAR
java -jarServer di applicazioni web19.1.2 Strumenti di Build: Maven e Gradle
Per automatizzare il processo di packaging, vengono utilizzati strumenti di build come Maven e Gradle. Questi strumenti gestiscono le dipendenze, compilano il codice, eseguono i test e creano i pacchetti finali.
-
Maven:
-
Descrizione: Maven utilizza un file di configurazione XML (
pom.xml) per definire il progetto, le dipendenze e i plugin. -
Vantaggi:
-
Convenzione sulla configurazione: struttura standardizzata dei progetti.
-
Ampio supporto della comunità e numerosi plugin disponibili.
-
-
Esempio di
pom.xmlper un’applicazione Spring Boot:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>demo</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!-- Altre dipendenze --> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
-
-
Gradle:
-
Descrizione: Gradle utilizza un file di configurazione basato su DSL (Domain Specific Language) scritto in Groovy o Kotlin (
build.gradleobuild.gradle.kts). -
Vantaggi:
-
Maggiore flessibilità e performance rispetto a Maven.
-
Sintassi più concisa e leggibile.
-
-
Esempio di
build.gradleper un’applicazione Spring Boot:plugins { id 'org.springframework.boot' version '3.0.0' id 'io.spring.dependency-management' version '1.0.11.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '17' repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter' // Altre dipendenze } tasks.named('test') { useJUnitPlatform() }
-
19.1.3 Packaging di un’Applicazione Spring Boot
Spring Boot semplifica il processo di packaging grazie ai suoi plugin dedicati per Maven e Gradle, che consentono di creare JAR eseguibili con tutte le dipendenze incluse. Questo approccio, noto come “fat JAR” o “uber JAR”, facilita la distribuzione e l’esecuzione dell’applicazione.
Esempio Pratico con Maven:
-
Configurazione del
pom.xml:Assicurarsi di avere il plugin
spring-boot-maven-pluginconfigurato:<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> -
Compilazione e Packaging:
Eseguire il comando Maven per compilare e creare il JAR eseguibile:
mvn clean package -
Esecuzione dell’Applicazione:
Una volta creato il JAR, eseguirlo con il comando:
java -jar target/demo-0.0.1-SNAPSHOT.jar
Esempio Pratico con Gradle:
-
Configurazione del
build.gradle:Assicurarsi di avere il plugin
org.springframework.bootapplicato:plugins { id 'org.springframework.boot' version '3.0.0' id 'io.spring.dependency-management' version '1.0.11.RELEASE' id 'java' } -
Compilazione e Packaging:
Eseguire il comando Gradle per costruire il JAR eseguibile:
gradle clean build -
Esecuzione dell’Applicazione:
Eseguire il JAR generato:
java -jar build/libs/demo-0.0.1-SNAPSHOT.jar
19.1.4 Best Practices per il Packaging e l’Esecuzione
-
Gestione delle Dipendenze:
-
Utilizzare Gestori di Dipendenze: Strumenti come Maven e Gradle gestiscono automaticamente le dipendenze, assicurando che tutte le librerie necessarie siano incluse nel pacchetto finale.
-
Versionamento Coerente: Mantenere versioni coerenti delle dipendenze per evitare conflitti e problemi di compatibilità.
-
-
Configurazione Esterna:
-
Parametrizzazione: Utilizzare file di configurazione esterni (ad esempio,
application.propertiesoapplication.yml) per gestire parametri che possono variare tra gli ambienti (sviluppo, test, produzione). -
Variabili di Ambiente: Favorire l’uso di variabili di ambiente per configurazioni sensibili, come credenziali di accesso.
-
-
Profilazione:
-
Spring Profiles: Utilizzare i profili di Spring per attivare configurazioni specifiche in base all’ambiente di esecuzione.
-
Esempio: Definire profili
dev,testeprodper gestire diverse configurazioni di database.
-
-
Ottimizzazione del Pacchetto:
-
Esclusione delle Dipendenze Non Necessarie: Ridurre la dimensione del pacchetto finale escludendo librerie non utilizzate.
-
Minimizzare le Risorse: Ottimizzare le risorse incluse (immagini, file statici) per migliorare i tempi di caricamento e l’efficienza.
-
-
Sicurezza:
-
Gestione delle Chiavi e delle Credenziali: Evitare di includere chiavi API o credenziali nel pacchetto; utilizzare sistemi di gestione delle segreti.
-
Aggiornamenti Regolari: Mantenere aggiornate le dipendenze per beneficiare delle ultime patch di sicurezza.
-
-
Automazione del Processo di Build:
-
CI/CD: Integrare il processo di packaging con pipeline di integrazione continua e distribuzione continua per automatizzare build, test e deployment.
-
Script di Build: Utilizzare script di build per standardizzare e automatizzare i processi ripetitivi.
-
19.1.5 Esempio Completo: Creazione e Esecuzione di un JAR Eseguibile con Spring Boot
Vediamo un esempio pratico completo che illustra come creare e eseguire un JAR eseguibile utilizzando Spring Boot e Maven.
1. Creazione di un Progetto Spring Boot:
Utilizzare Spring Initializr per generare un progetto base:
-
Configurazione:
-
Project: Maven Project
-
Language: Java
-
Spring Boot: 3.0.0
-
Group:
com.example -
Artifact:
demo -
Dependencies: Spring Web
-
2. Struttura del Progetto:
demo
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com.example.demo
│ │ │ └── DemoApplication.java
│ │ └── resources
│ │ └── application.properties
│ └── test
│ └── java
│ └── com.example.demo
│ └── DemoApplicationTests.java
├── pom.xml
└── README.md
3. Codice dell’Applicazione:
DemoApplication.java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.*;
@SpringBootApplication
@RestController
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@GetMapping("/")
public String home() {
return "Benvenuto nel tuo JAR eseguibile Spring Boot!";
}
}4. Configurazione del pom.xml:
Assicurarsi che il pom.xml includa il plugin di Spring Boot:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Altre dipendenze -->
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<!-- Configurazioni aggiuntive se necessarie -->
</plugin>
</plugins>
</build>
</project>5. Compilazione e Packaging:
Eseguire i seguenti comandi nel terminale all’interno della directory del progetto:
mvn clean packageQuesto comando esegue le seguenti operazioni:
-
Clean: Rimuove le directory di build precedenti.
-
Compile: Compila il codice sorgente.
-
Test: Esegue i test unitari.
-
Package: Crea il JAR eseguibile.
6. Esecuzione del JAR:
Dopo la compilazione, eseguire il JAR generato:
java -jar target/demo-0.0.1-SNAPSHOT.jar7. Verifica:
Aprire un browser web e navigare all’indirizzo http://localhost:8080/. Dovrebbe apparire il messaggio:
Benvenuto nel tuo JAR eseguibile Spring Boot!
19.1.6 Considerazioni Finali
Il processo di packaging e esecuzione delle applicazioni Java e Spring Boot è fondamentale per garantire una distribuzione efficace e un’esecuzione senza problemi in diversi ambienti. Utilizzando strumenti di build moderni come Maven e Gradle, e adottando best practices come la gestione esterna delle configurazioni e l’automazione del processo di build, gli sviluppatori possono creare applicazioni robuste, scalabili e facilmente gestibili.
Punti Chiave:
-
Scelta del Tipo di Pacchetto: Comprendere la differenza tra JAR e WAR e scegliere quello più adatto alle esigenze dell’applicazione.
-
Automazione del Build: Utilizzare Maven o Gradle per gestire dipendenze, compilazione e packaging.
-
Configurazione Esterna: Separare le configurazioni dall’applicazione per facilitare la gestione degli ambienti.
-
Sicurezza e Ottimizzazione: Gestire le dipendenze in modo sicuro e ottimizzare il pacchetto per prestazioni migliori.
-
Esecuzione Consistente: Creare pacchetti eseguibili che garantiscono coerenza tra diversi ambienti di esecuzione.
Con queste conoscenze, sarai in grado di gestire efficacemente il packaging e l’esecuzione delle tue applicazioni Java e Spring Boot, assicurando una distribuzione fluida e una gestione ottimale delle applicazioni in produzione.
19.2 Deployment su Cloud e Container
Nel contesto moderno dello sviluppo software, il deployment delle applicazioni si è evoluto significativamente, abbracciando tecnologie come i container e i servizi cloud. Questa sezione esplora come utilizzare Docker per la containerizzazione delle applicazioni e come eseguire il deployment su piattaforme cloud come AWS, Azure e Google Cloud. Comprendere queste tecnologie è fondamentale per garantire che le applicazioni siano scalabili, resilienti e facilmente gestibili in ambienti di produzione.
19.2.1 Utilizzo di Docker
Cos’è Docker?
Docker è una piattaforma open-source che consente di automatizzare il deployment di applicazioni all’interno di container leggeri e portatili. Un container include tutto il necessario per eseguire un’applicazione: codice, runtime, librerie di sistema e impostazioni. Questo assicura che l’applicazione funzioni in modo coerente indipendentemente dall’ambiente in cui viene eseguita.
Perché utilizzare Docker?
-
Portabilità: I container Docker possono essere eseguiti su qualsiasi sistema che supporta Docker, rendendo facile spostare le applicazioni tra ambienti di sviluppo, testing e produzione.
-
Isolamento: Ogni container è isolato dagli altri e dall’host, riducendo i conflitti di dipendenze e migliorando la sicurezza.
-
Scalabilità: Docker facilita la scalabilità delle applicazioni, consentendo di avviare più istanze di un container in modo rapido e semplice.
-
Efficienza: I container condividono il kernel del sistema operativo, rendendoli più leggeri rispetto alle macchine virtuali tradizionali.
Componenti Principali di Docker:
-
Dockerfile: Un file di testo che contiene una serie di istruzioni per costruire un’immagine Docker. Specifica l’ambiente necessario per eseguire l’applicazione.
-
Immagini Docker: Modelli read-only da cui vengono creati i container. Possono essere versionate e distribuite tramite registri pubblici o privati.
-
Container Docker: Istanza eseguibile di un’immagine Docker. Può essere avviato, fermato, spostato e cancellato.
-
Docker Compose: Strumento per definire e gestire applicazioni multi-container. Utilizza file YAML per configurare i servizi, le reti e i volumi.
Esempio Pratico: Creazione di un Container Docker per un’Applicazione Spring Boot
Supponiamo di avere un’applicazione Spring Boot che vogliamo containerizzare.
-
Creare un Dockerfile nella root del progetto:
# Utilizza un'immagine base di OpenJDK FROM openjdk:17-jdk-alpine # Imposta la directory di lavoro WORKDIR /app # Copia il jar dell'applicazione nel container COPY target/myapp.jar myapp.jar # Espone la porta su cui l'applicazione sarà in ascolto EXPOSE 8080 # Comando per eseguire l'applicazione ENTRYPOINT ["java", "-jar", "myapp.jar"] -
Costruire l’immagine Docker:
docker build -t myapp:1.0 . -
Eseguire il container:
docker run -p 8080:8080 myapp:1.0
Questo comando avvierà l’applicazione Spring Boot all’interno di un container Docker, mappando la porta 8080 del container alla porta 8080 del host.
Best Practices per Docker:
-
Minimizzare le Dimensioni delle Immagini: Utilizzare immagini base leggere (come
alpine) e rimuovere file non necessari per ridurre lo spazio e migliorare i tempi di deploy. -
Multi-Stage Builds: Separare il processo di build dall’ambiente di runtime per ottenere immagini più pulite e sicure.
-
Gestione delle Variabili d’Ambiente: Utilizzare variabili d’ambiente per configurare l’applicazione senza modificare il codice.
-
Sicurezza: Mantenere aggiornate le immagini base e limitare i privilegi dei container per ridurre i rischi di sicurezza.
19.2.2 Deployment su AWS, Azure e Google Cloud
Le piattaforme cloud offrono soluzioni scalabili e gestite per il deployment delle applicazioni, semplificando la gestione dell’infrastruttura e consentendo agli sviluppatori di concentrarsi sullo sviluppo del codice. Esamineremo brevemente come effettuare il deployment su Amazon Web Services (AWS), Microsoft Azure e Google Cloud Platform (GCP).
Amazon Web Services (AWS)
Servizi Principali per il Deployment:
-
Elastic Beanstalk: Piattaforma come servizio (PaaS) che facilita il deploy e la gestione di applicazioni sviluppate in diversi linguaggi, incluso Java con Spring Boot.
-
Amazon ECS/EKS: Servizi di orchestrazione di container che supportano Docker e Kubernetes rispettivamente.
-
AWS Lambda: Servizio di computing serverless per eseguire funzioni in risposta a eventi.
Esempio di Deployment con Elastic Beanstalk:
-
Preparare l’Applicazione:
Assicurarsi che l’applicazione Spring Boot sia confezionata come un file
.jar. -
Configurare Elastic Beanstalk:
-
Accedere alla console AWS e navigare verso Elastic Beanstalk.
-
Creare una nuova applicazione e ambiente, scegliendo “Java” come piattaforma.
-
Caricare il file
.jare configurare le impostazioni desiderate (dimensioni dell’istanza, variabili d’ambiente, ecc.).
-
-
Deploy:
Elastic Beanstalk gestirà automaticamente il provisioning delle risorse, il deploy dell’applicazione e la configurazione del bilanciamento del carico.
Vantaggi di AWS:
-
Scalabilità: Capacità di scalare automaticamente le risorse in base al traffico.
-
Integrazione: Ampia gamma di servizi integrati per database, monitoraggio, sicurezza, ecc.
-
Affidabilità: Infrastruttura altamente disponibile con data center distribuiti globalmente.
Microsoft Azure
Servizi Principali per il Deployment:
-
Azure App Service: Piattaforma PaaS per il deploy di applicazioni web, API e backend mobile.
-
Azure Kubernetes Service (AKS): Servizio gestito per l’orchestrazione di container con Kubernetes.
-
Azure Functions: Servizio di computing serverless per eseguire funzioni in risposta a eventi.
Esempio di Deployment con Azure App Service:
-
Preparare l’Applicazione:
Compilare l’applicazione Spring Boot come file
.jar. -
Configurare Azure App Service:
-
Accedere al portale di Azure e creare una nuova istanza di App Service.
-
Scegliere “Java” come stack runtime e selezionare la versione appropriata di Java.
-
Caricare il file
.jartramite FTP, Git, o integrazione continua.
-
-
Deploy:
Azure App Service gestirà il provisioning delle risorse, il deploy e il bilanciamento del carico.
Vantaggi di Azure:
-
Integrazione con Strumenti Microsoft: Perfetta integrazione con strumenti come Visual Studio, Active Directory, ecc.
-
Supporto Multi-Lingua: Supporto per una vasta gamma di linguaggi e framework.
-
Servizi Gestiti: Numerosi servizi gestiti per database, AI, analytics, e altro.
Google Cloud Platform (GCP)
Servizi Principali per il Deployment:
-
Google App Engine: Piattaforma PaaS per il deploy di applicazioni web scalabili.
-
Google Kubernetes Engine (GKE): Servizio gestito per l’orchestrazione di container con Kubernetes.
-
Cloud Functions: Servizio di computing serverless per eseguire funzioni in risposta a eventi.
Esempio di Deployment con Google App Engine:
-
Preparare l’Applicazione:
Creare un file
app.yamlnella root del progetto per configurare il servizio.runtime: java17 env: standard entrypoint: java -jar target/myapp.jar -
Configurare Google Cloud SDK:
Installare e configurare il Google Cloud SDK e autenticarsi.
-
Deploy:
Eseguire il comando di deploy:
gcloud app deployGoogle App Engine gestirà automaticamente il provisioning delle risorse, il deploy e la scalabilità.
Vantaggi di GCP:
-
Infrastruttura Globale: Ampia rete di data center per bassa latenza e alta disponibilità.
-
Innovazione Continua: Accesso a tecnologie avanzate come intelligenza artificiale, machine learning e big data.
-
Prezzi Competitivi: Modelli di pricing flessibili e competitivi.
Considerazioni Finali sul Deployment su Cloud e Container
Scelta della Piattaforma:
La scelta tra AWS, Azure e GCP dipende da diversi fattori, tra cui:
-
Integrazione con Strumenti Esistenti: Se la tua azienda utilizza già strumenti specifici di un fornitore, potrebbe essere vantaggioso rimanere all’interno dello stesso ecosistema.
-
Requisiti di Scalabilità: Valutare quale piattaforma offre la scalabilità più adatta alle esigenze dell’applicazione.
-
Costi: Considerare i modelli di pricing e i costi associati ai servizi utilizzati.
-
Supporto e Documentazione: La qualità del supporto e della documentazione può influenzare significativamente l’efficienza del deployment e della gestione.
Best Practices per il Deployment su Cloud e Container:
-
Automatizzare il Deployment: Utilizzare strumenti di integrazione continua e deployment continuo (CI/CD) come Jenkins, GitLab CI, o GitHub Actions per automatizzare il processo di deploy.
-
Gestire le Configurazioni: Separare le configurazioni dall’applicazione utilizzando variabili d’ambiente o servizi di gestione delle configurazioni come AWS Parameter Store o Azure App Configuration.
-
Monitorare e Loggare: Implementare soluzioni di monitoraggio e logging per tenere traccia delle performance e dei problemi in produzione. Strumenti come Prometheus, Grafana, ELK Stack o servizi cloud nativi possono essere utili.
-
Sicurezza: Assicurarsi che le applicazioni siano sicure implementando pratiche come la gestione delle credenziali, l’uso di reti private e la configurazione corretta dei firewall.
-
Gestione delle Dipendenze: Utilizzare immagini Docker con dipendenze ben definite e mantenere aggiornate le immagini base per includere le ultime patch di sicurezza.
Conclusione:
Il deployment su cloud e container rappresenta una componente essenziale nello sviluppo moderno delle applicazioni. Docker offre una soluzione efficace per la containerizzazione, garantendo portabilità e isolamento, mentre le piattaforme cloud come AWS, Azure e GCP forniscono infrastrutture scalabili e servizi gestiti che semplificano il processo di deployment e gestione delle applicazioni. Adottare queste tecnologie non solo migliora l’efficienza operativa, ma permette anche di costruire applicazioni resilienti e pronte per affrontare le sfide del mercato moderno.
Esempio Completo: Deployment di un’Applicazione Spring Boot su AWS con Docker
Per illustrare concretamente quanto discusso, consideriamo un esempio completo di deployment di un’applicazione Spring Boot containerizzata su AWS utilizzando Docker ed Elastic Beanstalk.
Passo 1: Preparare l’Applicazione
Assicurarsi che l’applicazione Spring Boot sia pronta e che il Dockerfile sia configurato correttamente come descritto nella sezione precedente.
Passo 2: Creare un’Immagine Docker e Caricarla su Amazon ECR
-
Creare un Repository ECR:
aws ecr create-repository --repository-name myapp-repo --region us-east-1 -
Autenticarsi con ECR:
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <account-id>.dkr.ecr.us-east-1.amazonaws.com -
Taggare e Pushare l’Immagine:
docker tag myapp:1.0 <account-id>.dkr.ecr.us-east-1.amazonaws.com/myapp-repo:1.0 docker push <account-id>.dkr.ecr.us-east-1.amazonaws.com/myapp-repo:1.0
Passo 3: Configurare Elastic Beanstalk per Utilizzare l’Immagine Docker
-
Creare un File
Dockerrun.aws.json:Nella root del progetto, creare un file
Dockerrun.aws.jsoncon il seguente contenuto:{ "AWSEBDockerrunVersion": 2, "containerDefinitions": [ { "name": "myapp", "image": "<account-id>.dkr.ecr.us-east-1.amazonaws.com/myapp-repo:1.0", "essential": true, "memory": 512, "portMappings": [ { "containerPort": 8080, "hostPort": 8080 } ] } ] } -
Creare un Ambiente Elastic Beanstalk:
Utilizzare la console AWS o l’AWS CLI per creare una nuova applicazione Elastic Beanstalk e caricare il file
Dockerrun.aws.json.eb init -p docker myapp eb create myapp-env
Passo 4: Monitorare l’Applicazione
Una volta effettuato il deploy, Elastic Beanstalk fornirà un URL pubblico per accedere all’applicazione. Utilizzare la console AWS per monitorare lo stato dell’ambiente, visualizzare i log e configurare le impostazioni di scaling automatico.
Conclusione dell’Esempio:
Seguendo questi passaggi, hai containerizzato un’applicazione Spring Boot utilizzando Docker e l’hai distribuita su AWS Elastic Beanstalk. Questo approccio garantisce che l’applicazione sia facilmente scalabile e gestibile, sfruttando i vantaggi offerti dalla containerizzazione e dai servizi cloud.
Riepilogo
Il deployment su cloud e container rappresenta una best practice nello sviluppo moderno, offrendo flessibilità, scalabilità e efficienza. Docker facilita la creazione di ambienti di esecuzione coerenti, mentre piattaforme cloud come AWS, Azure e GCP forniscono l’infrastruttura necessaria per eseguire e gestire le applicazioni in modo efficace. Acquisire competenze in queste tecnologie è essenziale per sviluppatori Java e Spring Boot che desiderano costruire applicazioni robuste e pronte per il futuro.
19.3 Monitoraggio con Spring Boot Actuator
Il monitoraggio delle applicazioni è una componente cruciale per garantire la loro affidabilità, performance e disponibilità. In ambienti di produzione, è fondamentale avere una visibilità completa sul comportamento dell’applicazione per identificare e risolvere tempestivamente eventuali problemi. Spring Boot Actuator è uno strumento potente che facilita il monitoraggio e la gestione delle applicazioni Spring Boot, offrendo una serie di endpoint pronti all’uso che forniscono informazioni dettagliate sullo stato dell’applicazione.
19.3.1 Introduzione a Spring Boot Actuator
Spring Boot Actuator è un modulo di Spring Boot che fornisce funzionalità pronte per il monitoraggio e la gestione delle applicazioni. Grazie a Actuator, è possibile esporre endpoint che offrono informazioni su metriche, salute, configurazioni e altro ancora. Questi endpoint possono essere utilizzati sia internamente dagli sviluppatori per diagnosticare problemi, sia esternamente da strumenti di monitoraggio per tenere sotto controllo l’applicazione in tempo reale.
Perché utilizzare Spring Boot Actuator?
-
Visibilità: Offre una panoramica completa dello stato dell’applicazione.
-
Facilità di integrazione: Si integra facilmente con strumenti di monitoraggio esterni come Prometheus, Grafana, New Relic, ecc.
-
Sicurezza: Permette di configurare l’accesso agli endpoint per proteggere le informazioni sensibili.
-
Estendibilità: Consente di creare endpoint personalizzati per esigenze specifiche.
19.3.2 Configurazione di Spring Boot Actuator
Per iniziare a utilizzare Actuator, è necessario aggiungere la dipendenza nel file pom.xml (per progetti Maven) o build.gradle (per progetti Gradle).
Esempio con Maven:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Esempio con Gradle:
implementation 'org.springframework.boot:spring-boot-starter-actuator'
Una volta aggiunta la dipendenza, Actuator fornirà automaticamente una serie di endpoint predefiniti. Tuttavia, per personalizzare il comportamento di Actuator, è possibile modificare il file di configurazione application.properties o application.yml.
Esempio di configurazione in application.properties:
management.endpoints.web.exposure.include=health,info,metrics,env
management.endpoint.health.show-details=always
Questa configurazione espone solo gli endpoint health, info, metrics ed env e mostra sempre i dettagli dello stato di salute.
19.3.3 Endpoint di Monitoraggio Predefiniti
Spring Boot Actuator offre numerosi endpoint pronti all’uso. Di seguito alcuni dei più utilizzati:
-
/actuator/health: Fornisce informazioni sullo stato di salute dell’applicazione. È possibile configurare diversi indicatori di salute (database, disco, servizi esterni, ecc.).
Esempio di risposta:
{ "status": "UP", "details": { "db": { "status": "UP", "database": "PostgreSQL", "hello": 1 }, "diskSpace": { "status": "UP", "total": 499963174912, "free": 392281604096, "threshold": 10485760 } } } -
/actuator/info: Fornisce informazioni personalizzate sull’applicazione, come versione, descrizione, ecc. È possibile definire queste informazioni nel file di configurazione.
Esempio di configurazione in
application.properties:info.app.name=Dalle basi di Java ai microservizi con Spring Boot info.app.version=1.0.0Esempio di risposta:
{ "app": { "name": "Dalle basi di Java ai microservizi con Spring Boot", "version": "1.0.0" } } -
/actuator/metrics: Fornisce metriche sulle prestazioni dell’applicazione, come utilizzo della CPU, memoria, numero di richieste HTTP, ecc.
-
/actuator/env: Espone le proprietà di configurazione dell’applicazione, utili per diagnosticare problemi legati alla configurazione.
19.3.4 Personalizzazione degli Endpoint
Spring Boot Actuator permette di personalizzare gli endpoint per soddisfare esigenze specifiche. È possibile abilitare o disabilitare determinati endpoint, aggiungere nuove metriche o creare endpoint personalizzati.
Abilitare tutti gli endpoint:
management.endpoints.web.exposure.include=*
Disabilitare un endpoint specifico:
management.endpoints.web.exposure.exclude=env
Creare un endpoint personalizzato:
import org.springframework.boot.actuate.endpoint.annotation.Endpoint;
import org.springframework.boot.actuate.endpoint.annotation.ReadOperation;
import org.springframework.stereotype.Component;
@Component
@Endpoint(id = "custom")
public class CustomEndpoint {
@ReadOperation
public String customEndpoint() {
return "Questo è un endpoint personalizzato!";
}
}Una volta creato, l’endpoint sarà accessibile tramite /actuator/custom.
19.3.5 Integrazione con Strumenti di Monitoraggio Esterni
Una delle potenti funzionalità di Spring Boot Actuator è la sua capacità di integrarsi con strumenti di monitoraggio esterni, facilitando l’aggregazione e l’analisi delle metriche.
Integrazione con Prometheus e Grafana:
-
Aggiungere la dipendenza per Prometheus:
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency> -
Configurare Actuator per Prometheus:
management.endpoints.web.exposure.include=health,info,metrics,prometheus management.endpoint.prometheus.enabled=true -
Accedere all’endpoint Prometheus:
L’endpoint sarà disponibile su
/actuator/prometheus, fornendo metriche nel formato compatibile con Prometheus. -
Configurare Grafana:
Utilizzare Grafana per visualizzare le metriche raccolte da Prometheus, creando dashboard personalizzate per monitorare le performance dell’applicazione.
Integrazione con altri strumenti:
Spring Boot Actuator supporta l’integrazione con vari altri strumenti come New Relic, Datadog, y etc., tramite Micrometer, un’astrazione per la raccolta di metriche.
19.3.6 Esempio Pratico: Configurazione di Actuator e Monitoraggio dello Stato di Salute
Consideriamo un’applicazione Spring Boot che utilizza Actuator per monitorare la salute del database e dello spazio su disco.
Passo 1: Aggiungere la dipendenza Actuator
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Passo 2: Configurare gli endpoint in application.properties
management.endpoints.web.exposure.include=health,info
management.endpoint.health.show-details=always
Passo 3: Definire le informazioni nell’endpoint info
info.app.name=Monitoraggio Applicazione
info.app.description=Un esempio di monitoraggio con Spring Boot Actuator
info.app.version=2.0.0
Passo 4: Avviare l’applicazione e accedere agli endpoint
-
Salute dell’applicazione:
http://localhost:8080/actuator/healthRisposta:
{ "status": "UP", "details": { "db": { "status": "UP", "database": "H2", "hello": 1 }, "diskSpace": { "status": "UP", "total": 499963174912, "free": 392281604096, "threshold": 10485760 } } } -
Informazioni sull’applicazione:
http://localhost:8080/actuator/infoRisposta:
{ "app": { "name": "Monitoraggio Applicazione", "description": "Un esempio di monitoraggio con Spring Boot Actuator", "version": "2.0.0" } }
19.3.7 Best Practices per il Monitoraggio con Actuator
-
Proteggere gli endpoint sensibili: Configurare la sicurezza per limitare l’accesso agli endpoint di monitoraggio, specialmente in ambienti di produzione.
Esempio di configurazione di sicurezza:
management.endpoints.web.exposure.include=health,info management.endpoint.health.show-details=when_authorizedConfigurare Spring Security per richiedere autenticazione agli endpoint.
-
Limitare la quantità di dati esposti: Evitare di esporre informazioni sensibili attraverso gli endpoint, filtrando i dettagli mostrati.
-
Utilizzare strumenti di monitoraggio esterni: Integrare Actuator con strumenti come Prometheus e Grafana per una visualizzazione avanzata delle metriche e alerting.
-
Monitorare solo ciò che è necessario: Configurare gli endpoint per esporre solo le metriche e le informazioni rilevanti, riducendo il carico sulla rete e migliorando la sicurezza.
-
Automatizzare il monitoraggio: Configurare pipeline di CI/CD per includere controlli di salute e metriche, assicurando che l’applicazione mantenga gli standard di qualità durante lo sviluppo.
19.3.8 Conclusioni
Spring Boot Actuator è uno strumento indispensabile per lo sviluppo di applicazioni Spring Boot robuste e affidabili. Fornendo una serie di endpoint pronti all’uso e la possibilità di personalizzazione, Actuator semplifica il processo di monitoraggio e gestione delle applicazioni, consentendo agli sviluppatori di mantenere un controllo costante sullo stato e le performance delle loro applicazioni. Integrando Actuator con strumenti di monitoraggio esterni, è possibile ottenere una visibilità completa e in tempo reale, facilitando la diagnosi e la risoluzione di eventuali problemi e garantendo un’elevata qualità del software.
Capitolo 20: Ripasso di Alcuni Concetti Fondamentali
20.1 Domande Frequenti su Java
In questa sezione vengono presentate le domande più comuni che possono emergere durante un colloquio tecnico su Java. Ogni domanda è accompagnata da una spiegazione dettagliata per assicurare una comprensione approfondita dei concetti coinvolti.
1. Cos’è la Java Virtual Machine (JVM) e qual è il suo ruolo?
Risposta:
La Java Virtual Machine (JVM) è un componente fondamentale dell’ecosistema Java. È un ambiente di esecuzione che permette ai programmi Java di funzionare su qualsiasi piattaforma, senza necessità di modifiche al codice sorgente.
Spiegazione:
La JVM esegue il bytecode generato dal compilatore Java (javac). Questo bytecode è indipendente dalla piattaforma, consentendo la portabilità del codice Java. La JVM gestisce l’allocazione della memoria, il garbage collection, la sicurezza e altre funzionalità necessarie per l’esecuzione delle applicazioni Java. Inoltre, la JVM fornisce un’interfaccia tra il codice Java e l’hardware sottostante, permettendo ottimizzazioni a runtime tramite il Just-In-Time (JIT) compiler.
2. Differenza tra == e equals() in Java
Risposta:
== confronta i riferimenti di memoria degli oggetti, verificando se due riferimenti puntano allo stesso oggetto. equals(), invece, è un metodo che può essere sovrascritto per definire una logica di uguaglianza basata sul contenuto degli oggetti.
Spiegazione:
-
==Operator: Utilizzato principalmente per tipi primitivi e per verificare se due riferimenti di oggetti puntano allo stesso indirizzo di memoria.String a = new String("test"); String b = new String("test"); System.out.println(a == b); // false -
equals()Method: Definisce l’uguaglianza logica tra due oggetti. Ad esempio, la classeStringsovrascriveequals()per confrontare il contenuto delle stringhe.String a = new String("test"); String b = new String("test"); System.out.println(a.equals(b)); // true
3. Cos’è l’ereditarietà in Java e come si implementa?
Risposta:
L’ereditarietà è un principio della programmazione orientata agli oggetti che permette a una classe di acquisire le proprietà e i metodi di un’altra classe. In Java, si implementa usando la parola chiave extends.
Spiegazione:
L’ereditarietà favorisce il riutilizzo del codice e facilita la creazione di gerarchie di classi. La classe che eredita è chiamata sottoclasse o classe derivata, mentre la classe da cui eredita è la superclass o classe base.
// Superclass
public class Animale {
public void mangiare() {
System.out.println("L'animale sta mangiando");
}
}
// Sottoclasse
public class Cane extends Animale {
public void abbaiare() {
System.out.println("Il cane sta abbaiando");
}
}
// Utilizzo
Cane cane = new Cane();
cane.mangiare(); // Eredita il metodo dalla classe Animale
cane.abbaiare();4. Spiega il concetto di polimorfismo in Java.
Risposta:
Il polimorfismo permette a oggetti di classi diverse di essere trattati come oggetti della stessa superclass, consentendo l’uso di metodi sovrascritti per comportamenti specifici.
Spiegazione:
Esistono due tipi di polimorfismo in Java:
-
Polimorfismo di Compilazione (Overloading): Si verifica quando più metodi hanno lo stesso nome ma firme diverse all’interno della stessa classe.
public class Calcolatrice { public int somma(int a, int b) { return a + b; } public double somma(double a, double b) { return a + b; } } -
Polimorfismo di Esecuzione (Overriding): Si verifica quando una sottoclasse fornisce una specifica implementazione di un metodo già definito nella superclass.
public class Animale { public void suono() { System.out.println("Suono generico"); } } public class Cane extends Animale { @Override public void suono() { System.out.println("Abbaio"); } } // Utilizzo Animale animale = new Cane(); animale.suono(); // Output: Abbaio
Il polimorfismo aumenta la flessibilità e la manutenzione del codice, permettendo di scrivere codice più generico e riutilizzabile.
5. Cosa sono le interfacce in Java e come differiscono dalle classi astratte?
Risposta:
Le interfacce definiscono un contratto che le classi devono seguire, specificando metodi senza implementazione (fino a Java 7) o con implementazioni predefinite (da Java 8). Le classi astratte, invece, possono contenere sia metodi astratti che concreti e permettono una maggiore flessibilità nella definizione dello stato.
Spiegazione:
-
Interfacce:
-
Consentono l’implementazione multipla, poiché una classe può implementare più interfacce.
-
Non possono avere stati (variabili d’istanza), solo costanti.
-
Da Java 8, possono includere metodi predefiniti (
default) e statici.
public interface Volante { void volare(); } public class Uccello implements Volante { @Override public void volare() { System.out.println("L'uccello sta volando"); } } -
-
Classi Astratte:
-
Possono avere variabili d’istanza e metodi concreti.
-
Consentono di definire comportamenti comuni che possono essere ereditati dalle sottoclassi.
-
Una classe può estendere solo una classe astratta.
public abstract class Animale { public abstract void suono(); public void mangiare() { System.out.println("L'animale sta mangiando"); } } public class Cane extends Animale { @Override public void suono() { System.out.println("Abbaio"); } } -
6. Cos’è l’incapsulamento e perché è importante?
Risposta:
L’incapsulamento è un principio della programmazione orientata agli oggetti che nasconde lo stato interno di un oggetto e richiede che tutte le interazioni avvengano tramite metodi pubblici. Questo protegge l’integrità dei dati e facilita la manutenzione del codice.
Spiegazione:
Attraverso l’uso di modificatori di accesso (private, protected, public), si può controllare l’accesso ai campi e ai metodi di una classe. Fornendo metodi getter e setter, si permette un controllo più preciso su come i dati vengono letti e modificati.
public class ContoBancario {
private double saldo;
public double getSaldo() {
return saldo;
}
public void deposita(double importo) {
if (importo > 0) {
saldo += importo;
}
}
public void preleva(double importo) {
if (importo > 0 && importo <= saldo) {
saldo -= importo;
}
}
}In questo esempio, il saldo è protetto da accessi diretti, e le operazioni di deposito e prelievo sono gestite tramite metodi che garantiscono la validità delle operazioni.
7. Spiega la gestione della memoria in Java, in particolare il Garbage Collector.
Risposta:
Java gestisce automaticamente la memoria tramite il Garbage Collector (GC), che si occupa di liberare la memoria occupata dagli oggetti che non sono più raggiungibili dall’applicazione, prevenendo perdite di memoria.
Spiegazione:
La JVM alloca la memoria per gli oggetti nel heap. Quando gli oggetti non sono più referenziati, il Garbage Collector li identifica e libera la memoria. Esistono diversi algoritmi di garbage collection, come:
-
Mark and Sweep: Segna gli oggetti raggiungibili e libera quelli non segnati.
-
Generational GC: Divide l’heap in generazioni (young, old) per ottimizzare la raccolta.
-
G1 (Garbage-First) GC: Progettato per applicazioni con grandi heap e requisiti di bassa latenza.
Il GC riduce il carico sullo sviluppatore, ma è importante scrivere codice che facilita il lavoro del GC, evitando ad esempio di mantenere riferimenti inutili agli oggetti.
8. Quali sono le differenze tra ArrayList e LinkedList in Java?
Risposta:
ArrayList e LinkedList sono entrambe implementazioni della interfaccia List, ma differiscono nella loro struttura interna e nelle performance per diverse operazioni.
Spiegazione:
-
ArrayList:
-
Basata su array dinamici.
-
Accesso rapido agli elementi tramite indice (O(1)).
-
Inserimenti e cancellazioni lente, soprattutto in posizioni diverse dalla fine (O(n)).
-
Consuma meno memoria rispetto a
LinkedListper memorizzare gli stessi elementi.
-
-
LinkedList:
-
Basata su una struttura a nodi doppiamente collegati.
-
Accesso lento agli elementi tramite indice (O(n)).
-
Inserimenti e cancellazioni efficienti in qualsiasi posizione (O(1)), se si ha il riferimento al nodo.
-
Consuma più memoria per memorizzare i riferimenti ai nodi.
-
Quando usarli:
-
ArrayList è preferibile quando si ha bisogno di accesso rapido agli elementi e le operazioni di inserimento/cancellazione sono rare.
-
LinkedList è più adatta quando si effettuano frequenti inserimenti e cancellazioni in posizioni arbitrarie della lista.
9. Cos’è un Stream in Java e quali sono i suoi vantaggi?
Risposta:
Un Stream in Java rappresenta una sequenza di elementi su cui è possibile eseguire operazioni aggregate in modo dichiarativo. I vantaggi includono una sintassi più concisa, miglioramento della leggibilità del codice e la possibilità di eseguire operazioni in parallelo in modo semplice.
Spiegazione:
Introdotto in Java 8, il framework Stream permette di elaborare collezioni di dati tramite operazioni come filter, map, reduce, collect, ecc.
List<String> nomi = Arrays.asList("Mario", "Luigi", "Peach", "Yoshi");
List<String> nomiFiltrati = nomi.stream()
.filter(nome -> nome.startsWith("P"))
.collect(Collectors.toList());Vantaggi:
-
Dichiarativo: Permette di esprimere il “cosa” anziché il “come”.
-
Lazy Evaluation: Le operazioni intermedie vengono eseguite solo quando necessario, ottimizzando le performance.
-
Parallelismo: Facilita l’elaborazione parallela senza complessità aggiuntive.
10. Differenza tra abstract class e interface in Java 8 e versioni successive
Risposta:
A partire da Java 8, le interfacce possono avere metodi predefiniti (default) e metodi statici, mentre le classi astratte possono avere sia metodi astratti che concreti e variabili d’istanza. Inoltre, una classe può implementare più interfacce ma estendere solo una classe astratta.
Spiegazione:
-
Interfacce:
-
Possono contenere metodi astratti, predefiniti e statici.
-
Non possono avere variabili d’istanza (solo costanti).
-
Consentono l’implementazione multipla.
public interface Volante { void volare(); default void atterraggio() { System.out.println("Atterraggio sicuro"); } } -
-
Classi Astratte:
-
Possono avere metodi astratti e concreti.
-
Possono avere variabili d’istanza.
-
Una classe può estendere solo una classe astratta.
public abstract class Animale { private String nome; public Animale(String nome) { this.nome = nome; } public abstract void suono(); public String getNome() { return nome; } } -
Scelta tra abstract class e interface:
-
Utilizzare un’interfaccia quando si vuole definire un contratto senza imporre una struttura di ereditarietà.
-
Utilizzare una classe astratta quando si vuole condividere codice comune tra classi correlate.
11. Cos’è il synchronized in Java e quando usarlo?
Risposta:
La parola chiave synchronized in Java è utilizzata per controllare l’accesso a blocchi di codice o metodi, garantendo che solo un thread alla volta possa eseguirli. È fondamentale per prevenire condizioni di race e garantire la coerenza dei dati in ambienti multithreading.
Spiegazione:
Quando un metodo o un blocco di codice è dichiarato synchronized, il thread che lo esegue acquisisce un lock sull’oggetto specificato (o sulla classe se è un metodo statico). Altri thread devono attendere fino a quando il lock non viene rilasciato.
public class Contatore {
private int count = 0;
public synchronized void incrementa() {
count++;
}
public synchronized int getCount() {
return count;
}
}Considerazioni:
-
Performance: L’uso eccessivo di
synchronizedpuò ridurre le performance a causa del blocking dei thread. -
Deadlock: Una gestione inappropriata dei lock può portare a deadlock, dove due o più thread si bloccano a vicenda aspettando lock.
-
Alternatives: Java fornisce alternative come le classi nel pacchetto
java.util.concurrent, che offrono meccanismi di sincronizzazione più sofisticati e performanti.
12. Spiega il concetto di immutabilità in Java.
Risposta:
Un oggetto immutabile è un oggetto il cui stato non può essere modificato dopo la sua creazione. In Java, classi come String sono esempi di classi immutabili.
Spiegazione:
Creare classi immutabili può portare a codice più sicuro e semplice da comprendere, soprattutto in contesti multithreading.
Come creare una classe immutabile:
-
Dichiarare la classe come
final: Evita che la classe venga estesa. -
Rendere tutti i campi privati e finali: Impedisce modifiche esterne e garantisce l’immutabilità.
-
Non fornire metodi setter: Solo metodi getter per accedere ai campi.
-
Inizializzare tutti i campi tramite il costruttore.
-
Se i campi sono oggetti mutabili, restituire copie invece dei riferimenti originali.
public final class Persona {
private final String nome;
private final int eta;
public Persona(String nome, int eta) {
this.nome = nome;
this.eta = eta;
}
public String getNome() {
return nome;
}
public int getEta() {
return eta;
}
}Vantaggi:
-
Sicurezza: Oggetti immutabili sono intrinsecamente thread-safe.
-
Facilità di utilizzo: Non è necessario preoccuparsi di cambiamenti di stato inaspettati.
-
Caching e ottimizzazione: Possono essere facilmente memorizzati nella cache senza rischi.
13. Cos’è il final in Java e come viene utilizzato?
Risposta:
La parola chiave final in Java viene utilizzata per dichiarare costanti, impedire l’ereditarietà di classi e la sovrascrittura di metodi.
Spiegazione:
-
Variabili: Quando una variabile è dichiarata
final, il suo valore non può essere modificato una volta assegnato.public final int COSTO = 100; -
Metodi: Un metodo dichiarato
finalnon può essere sovrascritto dalle sottoclassi.public final void mostraMessaggio() { System.out.println("Messaggio finale"); } -
Classi: Una classe dichiarata
finalnon può essere estesa.public final class Costante { // Implementazione }
Utilizzi comuni:
-
Costanti: Definire valori che non devono cambiare durante l’esecuzione del programma.
-
Sicurezza: Prevenire la modifica di comportamenti critici attraverso l’ereditarietà.
-
Ottimizzazione: Il compilatore può effettuare ottimizzazioni su metodi e classi
final.
14. Spiega il concetto di “boxing” e “unboxing” in Java.
Risposta:
Il “boxing” è il processo di conversione di un tipo primitivo in un oggetto wrapper corrispondente, mentre l’“unboxing” è la conversione inversa, da un oggetto wrapper a un tipo primitivo.
Spiegazione:
Java fornisce classi wrapper per tutti i tipi primitivi (Integer per int, Double per double, ecc.). A partire da Java 5, l’autoboxing e l’autounboxing permettono queste conversioni in modo implicito.
// Boxing
int numeroPrimitivo = 5;
Integer numeroOggetto = numeroPrimitivo; // Autoboxing
// Unboxing
Integer altroNumeroOggetto = new Integer(10);
int altroNumeroPrimitivo = altroNumeroOggetto; // AutounboxingVantaggi:
-
Collezioni Generiche: Le collezioni in Java possono contenere solo oggetti, quindi i tipi primitivi devono essere convertiti.
-
Convenienza: L’autoboxing semplifica il codice, eliminando la necessità di conversioni esplicite.
Considerazioni:
-
Performance: L’autoboxing e l’autounboxing possono introdurre overhead, specialmente in loop intensivi.
-
Null Pointer Exception: L’unboxing di un oggetto wrapper
nullcauserà unaNullPointerException.
15. Cos’è la gestione delle eccezioni in Java e quali sono i tipi principali?
Risposta:
La gestione delle eccezioni in Java è un meccanismo per gestire condizioni di errore durante l’esecuzione del programma. I principali tipi di eccezioni sono le checked exceptions e le unchecked exceptions.
Spiegazione:
-
Checked Exceptions: Eccezioni che il compilatore richiede di gestire, tramite
try-catcho dichiarandothrowsnel metodo. Esempi includonoIOException,SQLException.public void leggiFile(String percorso) throws IOException { BufferedReader reader = new BufferedReader(new FileReader(percorso)); // ... } -
Unchecked Exceptions: Eccezioni che non sono controllate dal compilatore, ereditano da
RuntimeException. Esempi includonoNullPointerException,ArrayIndexOutOfBoundsException.public void accediElemento(int[] array, int indice) { System.out.println(array[indice]); // Potrebbe lanciare ArrayIndexOutOfBoundsException } -
Error: Tipi di eccezioni gravi che indicano problemi a livello di JVM, come
OutOfMemoryError. Non dovrebbero essere catturate o gestite dall’applicazione.
Best Practices:
-
Gestire solo le eccezioni che si possono recuperare.
-
Non catturare
ExceptionoThrowablea meno che non sia strettamente necessario. -
Fornire messaggi di errore chiari e informativi.
-
Usare finally o try-with-resources per garantire il rilascio delle risorse.
Queste domande rappresentano solo una parte delle possibili tematiche che potrebbero essere affrontate durante un colloquio tecnico su Java. È fondamentale non solo memorizzare le risposte, ma comprendere a fondo i concetti per poter applicare le conoscenze in contesti pratici e risolvere problemi complessi.
20.2 Domande Frequenti su Spring Boot
In questa sezione, esploreremo una serie di domande frequenti su Spring Boot che possono emergere durante un colloquio tecnico. Ogni domanda è accompagnata da una risposta dettagliata che non solo fornisce la soluzione, ma anche una spiegazione approfondita dei concetti sottostanti. Questo approccio aiuta a consolidare la comprensione e a prepararsi efficacemente per affrontare domande simili in contesti reali.
1. Che cos’è Spring Boot e quali sono i suoi vantaggi principali?
Risposta:
Spring Boot è un framework open-source basato su Spring Framework che semplifica lo sviluppo di applicazioni Java stand-alone e production-ready. I principali vantaggi di Spring Boot includono:
-
Autoconfigurazione: Spring Boot tenta di configurare automaticamente l’applicazione in base alle dipendenze presenti nel classpath, riducendo la necessità di configurazioni manuali.
-
Starter POMs: Fornisce una serie di “starter” che aggregano le dipendenze necessarie per funzionalità comuni, facilitando l’inclusione di librerie senza gestire singole versioni.
-
Embedded Servers: Supporta server web embedded come Tomcat, Jetty o Undertow, permettendo di eseguire l’applicazione come un’applicazione Java standard senza necessità di un server esterno.
-
Actuator: Offre strumenti integrati per monitorare e gestire l’applicazione in produzione, come metriche, informazioni sull’ambiente, e altro.
-
Convezione sulla configurazione: Favorisce la configurazione automatica basata sulle convenzioni, riducendo la quantità di codice boilerplate e configurazioni necessarie.
Esempio:
Un’applicazione Spring Boot tipica può essere avviata con una sola classe:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MySpringBootApplication {
public static void main(String[] args) {
SpringApplication.run(MySpringBootApplication.class, args);
}
}2. Come funziona l’autoconfigurazione in Spring Boot?
Risposta:
L’autoconfigurazione in Spring Boot utilizza il meccanismo di “Conditional Beans” per configurare automaticamente i bean Spring in base alle dipendenze presenti nel classpath e alle proprietà definite nell’applicazione. Questo processo avviene durante l’avvio dell’applicazione e segue i seguenti passaggi:
-
Scan delle Dipendenze: Spring Boot esamina le dipendenze presenti nel
pom.xmlobuild.gradleper determinare quali moduli sono inclusi. -
Application Context: Carica il contesto dell’applicazione, applicando le configurazioni predefinite fornite dai “starter” e dai moduli di autoconfigurazione.
-
Conditional Configuration: Utilizza annotazioni come
@ConditionalOnClass,@ConditionalOnMissingBean, e altre per decidere quali bean configurare in base all’ambiente e alle dipendenze. -
Override delle Configurazioni: Gli sviluppatori possono personalizzare o sovrascrivere le configurazioni predefinite definendo i propri bean o modificando le proprietà.
Esempio:
Se nel classpath è presente spring-boot-starter-web, Spring Boot autoconfigurerà un server web embedded e configurazioni di base per Spring MVC senza che l’utente debba definirle manualmente.
// Nessuna configurazione necessaria per avviare un'applicazione web
@SpringBootApplication
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}3. Cosa sono gli “Starter” in Spring Boot e come vengono utilizzati?
Risposta:
Gli “Starter” in Spring Boot sono dipendenze POM (Project Object Model) predefinite che aggregano una serie di dipendenze correlate per una specifica funzionalità. Facilitano l’inclusione di librerie comuni senza la necessità di gestire singole versioni o dipendenze.
Vantaggi degli Starter:
-
Semplicità: Riduce la complessità di gestione delle dipendenze.
-
Consistenza: Garantisce che tutte le dipendenze siano compatibili tra loro.
-
Velocità di Sviluppo: Permette di iniziare rapidamente lo sviluppo con configurazioni predefinite.
Esempi di Starter:
-
spring-boot-starter-web: Include dipendenze per sviluppare applicazioni web, come Spring MVC, Tomcat, e Jackson. -
spring-boot-starter-data-jpa: Comprende dipendenze per Spring Data JPA e Hibernate. -
spring-boot-starter-security: Aggrega le dipendenze necessarie per implementare la sicurezza nelle applicazioni.
Esempio di Utilizzo:
Nel file pom.xml, si può includere uno starter come segue:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>4. Come si configurano le proprietà dell’applicazione in Spring Boot?
Risposta:
Spring Boot utilizza file di configurazione, tipicamente application.properties o application.yml, per definire le proprietà dell’applicazione. Queste proprietà possono includere configurazioni per il server, database, sicurezza, e altre componenti.
Esempio di application.properties:
# Configurazione del server
server.port=8081
# Configurazione del database
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
spring.datasource.username=root
spring.datasource.password=secret
# Configurazione di JPA
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
Esempio di application.yml:
server:
port: 8081
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb
username: root
password: secret
jpa:
hibernate:
ddl-auto: update
show-sql: trueProfili di Configurazione:
Spring Boot supporta profili (es. dev, prod) per gestire diverse configurazioni per ambienti differenti. È possibile definire file come application-dev.properties e attivare un profilo specifico tramite la proprietà spring.profiles.active.
# Attivazione del profilo 'dev'
spring.profiles.active=dev
5. Come gestire le dipendenze e le versioni in Spring Boot?
Risposta:
Spring Boot utilizza un meccanismo chiamato “Dependency Management” per gestire le versioni delle dipendenze automaticamente. Questo è ottenuto attraverso l’uso di “Starter POMs” e il parent POM di Spring Boot.
Vantaggi:
-
Compatibilità: Garantisce che tutte le dipendenze siano compatibili tra loro.
-
Semplificazione: Gli sviluppatori non devono specificare manualmente le versioni delle dipendenze comuni.
Esempio di Parent POM:
Nel pom.xml, si può estendere il parent di Spring Boot per utilizzare il suo management delle dipendenze.
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.0</version>
<relativePath/> <!-- cerca nel repository centrale -->
</parent>Aggiunta di Dipendenze:
Quando si aggiungono dipendenze, non è necessario specificare la versione se è già gestita dal parent POM.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<!-- Versione gestita dal parent -->
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>Override delle Versioni:
Se è necessario utilizzare una versione diversa, si può specificare esplicitamente la versione nella dipendenza.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>3.1.0</version> <!-- Versione personalizzata -->
</dependency>6. Come si crea un’API RESTful con Spring Boot?
Risposta:
Creare un’API RESTful con Spring Boot implica la definizione di controller che gestiscono le richieste HTTP e rispondono con dati, solitamente in formato JSON. Ecco i passaggi fondamentali:
-
Definizione del Controller:
Utilizzare l’annotazione
@RestControllerper indicare che la classe gestisce richieste REST. -
Mappatura delle Rotte:
Utilizzare annotazioni come
@GetMapping,@PostMapping,@PutMapping,@DeleteMappingper mappare le rotte HTTP ai metodi del controller. -
Gestione dei Dati:
Integrare con servizi e repository per gestire la logica di business e l’accesso ai dati.
Esempio:
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/api/users")
public class UserController {
private final UserService userService;
// Iniezione del servizio tramite costruttore
public UserController(UserService userService) {
this.userService = userService;
}
// GET /api/users
@GetMapping
public List<User> getAllUsers() {
return userService.findAllUsers();
}
// GET /api/users/{id}
@GetMapping("/{id}")
public User getUserById(@PathVariable Long id) {
return userService.findUserById(id);
}
// POST /api/users
@PostMapping
public User createUser(@RequestBody User user) {
return userService.saveUser(user);
}
// PUT /api/users/{id}
@PutMapping("/{id}")
public User updateUser(@PathVariable Long id, @RequestBody User user) {
return userService.updateUser(id, user);
}
// DELETE /api/users/{id}
@DeleteMapping("/{id}")
public void deleteUser(@PathVariable Long id) {
userService.deleteUser(id);
}
}Definizione del Modello:
import javax.persistence.*;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// Getter e Setter
// ...
}Definizione del Repository:
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
// Metodi di query personalizzati possono essere aggiunti qui
}Definizione del Servizio:
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
private final UserRepository userRepository;
// Iniezione del repository tramite costruttore
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public List<User> findAllUsers() {
return userRepository.findAll();
}
public User findUserById(Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new ResourceNotFoundException("User not found with id " + id));
}
public User saveUser(User user) {
return userRepository.save(user);
}
public User updateUser(Long id, User userDetails) {
User user = findUserById(id);
user.setName(userDetails.getName());
user.setEmail(userDetails.getEmail());
return userRepository.save(user);
}
public void deleteUser(Long id) {
User user = findUserById(id);
userRepository.delete(user);
}
}7. Come si implementa la sicurezza nelle applicazioni Spring Boot?
Risposta:
Spring Boot integra Spring Security per gestire la sicurezza delle applicazioni. Spring Security offre funzionalità per l’autenticazione, l’autorizzazione, la protezione CSRF, e altro ancora.
Passaggi per Implementare la Sicurezza:
-
Aggiunta della Dipendenza:
Includere
spring-boot-starter-securitynelpom.xml.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> -
Configurazione di Base:
Spring Boot applica una configurazione di sicurezza predefinita che richiede l’autenticazione per tutte le rotte e crea un utente con credenziali generate all’avvio.
-
Definizione delle Regole di Sicurezza Personalizzate:
Creare una classe di configurazione che estende
WebSecurityConfigurerAdapter(per Spring Boot 2) o utilizzare la nuova configurazione basata su bean (per Spring Boot 3).Esempio per Spring Boot 3:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.web.SecurityFilterChain; @Configuration public class SecurityConfig { @Bean public SecurityFilterChain filterChain(HttpSecurity http) throws Exception { http .csrf().disable() .authorizeHttpRequests(authorize -> authorize .requestMatchers("/public/**").permitAll() .anyRequest().authenticated() ) .httpBasic(); return http.build(); } } -
Definizione degli Utenti e dei Ruoli:
Configurare gli utenti e i loro ruoli, ad esempio utilizzando una configurazione in memoria o integrando con un database.
Esempio di Configurazione In-Memory:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.core.userdetails.User; import org.springframework.security.core.userdetails.UserDetailsService; import org.springframework.security.provisioning.InMemoryUserDetailsManager; @Configuration public class UserConfig { @Bean public UserDetailsService users() { InMemoryUserDetailsManager manager = new InMemoryUserDetailsManager(); manager.createUser(User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build()); manager.createUser(User.withDefaultPasswordEncoder() .username("admin") .password("admin") .roles("ADMIN") .build()); return manager; } }
Autenticazione e Autorizzazione:
-
Autenticazione: Verifica dell’identità dell’utente, ad esempio tramite username e password.
-
Autorizzazione: Controllo dei permessi dell’utente per accedere a determinate risorse o eseguire azioni specifiche.
Protezione CSRF:
Per applicazioni che utilizzano sessioni, Spring Security protegge contro attacchi Cross-Site Request Forgery (CSRF). È possibile disabilitare questa protezione se non necessaria, come mostrato nell’esempio precedente.
8. Che cos’è Spring Boot Actuator e come viene utilizzato?
Risposta:
Spring Boot Actuator è un modulo di Spring Boot che fornisce funzionalità pronte all’uso per monitorare e gestire un’applicazione in produzione. Offre endpoint REST che forniscono informazioni sull’applicazione, come metriche, stato di salute, informazioni sull’ambiente, e altro.
Caratteristiche Principali:
-
Endpoint di Monitoraggio: Accesso a informazioni dettagliate tramite endpoint come
/actuator/health,/actuator/metrics,/actuator/info, ecc. -
Personalizzazione degli Endpoint: Possibilità di abilitare o disabilitare specifici endpoint e configurare le informazioni esposte.
-
Integrazione con Sistemi di Monitoraggio: Facilita l’integrazione con strumenti esterni come Prometheus, Grafana, New Relic, ecc.
Come Utilizzare Spring Boot Actuator:
-
Aggiunta della Dipendenza:
Includere
spring-boot-starter-actuatornelpom.xml.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> -
Configurazione degli Endpoint:
Configurare quali endpoint sono esposti nel file
application.propertiesoapplication.yml.Esempio in
application.properties:management.endpoints.web.exposure.include=health,info,metrics management.endpoint.health.show-details=always -
Accesso agli Endpoint:
Avviare l’applicazione e accedere agli endpoint tramite URL, ad esempio:
-
Salute dell’Applicazione:
http://localhost:8080/actuator/health -
Metriche dell’Applicazione:
http://localhost:8080/actuator/metrics -
Informazioni sull’Applicazione:
http://localhost:8080/actuator/info
-
Esempio di Output di /actuator/health:
{
"status": "UP",
"details": {
"diskSpace": {
"status": "UP",
"details": {
"total": 499963174912,
"free": 243935437568,
"threshold": 10485760
}
},
"db": {
"status": "UP",
"details": {
"database": "PostgreSQL",
"hello": 1
}
}
}
}Sicurezza degli Endpoint:
Per proteggere gli endpoint di Actuator, è possibile configurare l’autenticazione e l’autorizzazione tramite Spring Security.
9. Come si gestiscono i profili in Spring Boot?
Risposta:
I profili in Spring Boot consentono di definire diverse configurazioni per differenti ambienti, come sviluppo, test e produzione. Ogni profilo può avere le proprie proprietà e configurazioni di bean.
Come Utilizzare i Profili:
-
Definizione dei Profili:
Creare file di configurazione specifici per ogni profilo, ad esempio
application-dev.properties,application-prod.properties. -
Attivazione di un Profilo:
Specificare il profilo attivo tramite la proprietà
spring.profiles.activenel fileapplication.propertieso tramite variabili di ambiente.spring.profiles.active=devOppure tramite la riga di comando:
java -jar myapp.jar --spring.profiles.active=prod -
Configurazione Condizionale dei Bean:
Utilizzare l’annotazione
@Profileper definire quali bean devono essere creati per ogni profilo.Esempio:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Profile; @Configuration public class DataSourceConfig { @Bean @Profile("dev") public DataSource devDataSource() { // Configurazione per lo sviluppo return new H2DataSource(); } @Bean @Profile("prod") public DataSource prodDataSource() { // Configurazione per la produzione return new MySQLDataSource(); } } -
Sovrascrittura delle Proprietà:
Le proprietà definite in un profilo specifico sovrascrivono quelle definite nel file
application.properties.Esempio in
application-dev.properties:spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.username=sa spring.datasource.password=Esempio in
application-prod.properties:spring.datasource.url=jdbc:mysql://prodserver:3306/proddb spring.datasource.username=produser spring.datasource.password=prodpass
Utilizzo Pratico:
I profili consentono di mantenere separate le configurazioni specifiche per ogni ambiente, facilitando il deployment e la gestione delle applicazioni in contesti diversi.
10. Come si eseguono i test in Spring Boot?
Risposta:
Spring Boot supporta diversi tipi di test, inclusi test unitari, test di integrazione e test delle API REST. Gli strumenti principali utilizzati per il testing sono JUnit, Mockito, e Spring Test.
Tipi di Test:
-
Test Unitari:
Verificano il comportamento di singoli componenti isolati, come servizi o repository.
Esempio:
import static org.mockito.Mockito.*; import static org.assertj.core.api.Assertions.*; import org.junit.jupiter.api.Test; import org.mockito.InjectMocks; import org.mockito.Mock; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest public class UserServiceTest { @Mock private UserRepository userRepository; @InjectMocks private UserService userService; @Test public void testFindAllUsers() { List<User> mockUsers = Arrays.asList(new User("Alice"), new User("Bob")); when(userRepository.findAll()).thenReturn(mockUsers); List<User> users = userService.findAllUsers(); assertThat(users).hasSize(2).extracting(User::getName).contains("Alice", "Bob"); } } -
Test di Integrazione:
Verificano l’interazione tra più componenti dell’applicazione e spesso coinvolgono il caricamento del contesto Spring.
Esempio:
import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.boot.test.web.client.TestRestTemplate; import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import static org.assertj.core.api.Assertions.*; @SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT) public class UserControllerIntegrationTest { @Autowired private TestRestTemplate restTemplate; @Test public void testGetAllUsers() { ResponseEntity<User[]> response = restTemplate.getForEntity("/api/users", User[].class); assertThat(response.getStatusCode()).isEqualTo(HttpStatus.OK); assertThat(response.getBody()).isNotEmpty(); } } -
Test delle API REST:
Verificano il corretto funzionamento degli endpoint REST, inclusi i comportamenti di autenticazione e autorizzazione.
Esempio:
import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.autoconfigure.web.servlet.AutoConfigureMockMvc; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.web.servlet.MockMvc; import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.*; import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.*; @SpringBootTest @AutoConfigureMockMvc public class UserApiTest { @Autowired private MockMvc mockMvc; @Test public void testGetUserById() throws Exception { mockMvc.perform(get("/api/users/1")) .andExpect(status().isOk()) .andExpect(jsonPath("$.name").value("Alice")); } }
Best Practices per il Testing:
-
Isolamento: Mantenere i test unitari isolati utilizzando mocking per dipendenze esterne.
-
Ripetibilità: Assicurarsi che i test siano ripetibili e non dipendano dallo stato esterno.
-
Copertura: Mirare a una buona copertura del codice, bilanciando tra test unitari e di integrazione.
-
Automazione: Integrare i test nel processo di build e deployment per garantire la qualità continua.
11. Quali sono le differenze principali tra Spring Boot 2 e Spring Boot 3?
Risposta:
Spring Boot 3 rappresenta un’evoluzione significativa rispetto a Spring Boot 2, introducendo diverse novità e miglioramenti. Ecco le principali differenze:
-
Supporto per Java 17 e Superiori:
Spring Boot 3 richiede Java 17 come versione minima, sfruttando le nuove funzionalità e miglioramenti delle prestazioni introdotti in Java.
-
Migrazione a Jakarta EE 9:
Con Spring Boot 3, tutte le dipendenze di Java EE sono state migrate a Jakarta EE 9, comportando il cambio del package namespace da
javax.*ajakarta.*.Esempio di Cambio Namespace:
- Da
javax.persistence.Entityajakarta.persistence.Entity.
- Da
-
Miglioramenti delle Prestazioni:
Spring Boot 3 include ottimizzazioni per migliorare le prestazioni dell’applicazione, riducendo il tempo di avvio e l’utilizzo delle risorse.
-
Nuove Funzionalità e Miglioramenti:
-
Enhanced Configuration: Miglioramenti nel supporto per la configurazione e l’autoconfigurazione.
-
Reactive Programming: Miglioramenti nel supporto per programmazione reattiva con Spring WebFlux.
-
Deprecazioni: Rimozione di alcune funzionalità e dipendenze obsolete presenti in Spring Boot 2.
-
-
Compatibilità con Librerie Esterne:
Alcune librerie esterne potrebbero aver subito modifiche per essere compatibili con Spring Boot 3, richiedendo aggiornamenti nei progetti esistenti.
Considerazioni per la Migrazione:
-
Aggiornamento delle Dipendenze: Aggiornare tutte le dipendenze per essere compatibili con Jakarta EE 9.
-
Refactoring del Codice: Modificare i riferimenti dei package da
javax.*ajakarta.*. -
Test Completi: Eseguire test approfonditi per garantire che l’applicazione funzioni correttamente con le nuove versioni delle dipendenze.
-
Documentazione: Consultare la guida ufficiale di migrazione fornita da Spring per dettagli specifici e best practices.
Esempio di Configurazione Migrazione:
Supponiamo di avere una classe User che utilizza javax.persistence.Entity. In Spring Boot 3, questa dovrebbe essere aggiornata a jakarta.persistence.Entity.
// Spring Boot 2
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class User {
@Id
private Long id;
// Altri campi e metodi
}
// Spring Boot 3
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
@Entity
public class User {
@Id
private Long id;
// Altri campi e metodi
}12. Come si implementa la comunicazione tra microservizi in Spring Boot?
Risposta:
La comunicazione tra microservizi può essere realizzata in vari modi, tra cui sincrona e asincrona. Spring Boot, in combinazione con Spring Cloud, fornisce strumenti potenti per gestire questa comunicazione in modo scalabile e resiliente.
Metodi di Comunicazione:
-
HTTP REST:
Utilizza chiamate HTTP sincrone per comunicare tra microservizi. È semplice da implementare ma può soffrire di latenza e dipendenze dirette.
Esempio:
Utilizzare
RestTemplateoWebClientper effettuare richieste HTTP.import org.springframework.web.reactive.function.client.WebClient; import reactor.core.publisher.Mono; public class UserServiceClient { private final WebClient webClient; public UserServiceClient(WebClient.Builder webClientBuilder) { this.webClient = webClientBuilder.baseUrl("http://userservice").build(); } public Mono<User> getUserById(Long id) { return webClient.get() .uri("/api/users/{id}", id) .retrieve() .bodyToMono(User.class); } } -
gRPC:
Un framework ad alte prestazioni per comunicazioni remote, basato su HTTP/2 e protocolli binari. È ideale per scenari che richiedono bassa latenza e alta efficienza.
-
Messaging Asincrono:
Utilizza broker di messaggi come RabbitMQ, Kafka o ActiveMQ per la comunicazione asincrona tra microservizi. Migliora la resilienza e la scalabilità.
Esempio con Spring Cloud Stream e Kafka:
import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.annotation.StreamListener; import org.springframework.messaging.handler.annotation.SendTo; @EnableBinding(Sink.class) public class MessageListener { @StreamListener(Sink.INPUT) @SendTo(Sink.INPUT) public String handle(String message) { // Logica di elaborazione del messaggio return "Processed: " + message; } } -
Service Discovery e Load Balancing:
Utilizzare strumenti come Eureka per la scoperta dei servizi e Ribbon o Spring Cloud LoadBalancer per il bilanciamento del carico tra istanze.
Esempio di Service Discovery con Eureka:
// Dipendenza nel pom.xml <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> // Configurazione in application.properties eureka.client.service-url.defaultZone=http://localhost:8761/eureka/
Best Practices per la Comunicazione tra Microservizi:
-
Resilienza: Implementare meccanismi di fallback e circuit breaker (ad esempio con Resilience4j) per gestire i guasti.
-
Idempotenza: Assicurarsi che le operazioni siano idempotenti per gestire ripetizioni di richieste in caso di fallimenti.
-
Monitoraggio: Monitorare le comunicazioni tra microservizi per identificare e risolvere problemi rapidamente.
-
Sicurezza: Proteggere le comunicazioni tra microservizi utilizzando autenticazione e crittografia adeguate.
13. Come si implementa la gestione delle transazioni in Spring Boot?
Risposta:
La gestione delle transazioni in Spring Boot è facilitata dall’uso dell’annotazione @Transactional, che consente di definire i confini delle transazioni in modo dichiarativo. Spring gestisce l’inizio, il commit e il rollback delle transazioni in base al successo o al fallimento delle operazioni all’interno del metodo annotato.
Passaggi per Implementare la Gestione delle Transazioni:
-
Configurazione del Transaction Manager:
Spring Boot configura automaticamente un transaction manager appropriato in base al tipo di database e alle dipendenze presenti. Per JPA, viene utilizzato
JpaTransactionManager. -
Annotazione dei Metodi Transazionali:
Utilizzare
@Transactionalper annotare i metodi che devono essere eseguiti all’interno di una transazione.Esempio:
import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Service public class OrderService { private final OrderRepository orderRepository; private final InventoryService inventoryService; public OrderService(OrderRepository orderRepository, InventoryService inventoryService) { this.orderRepository = orderRepository; this.inventoryService = inventoryService; } @Transactional public void placeOrder(Order order) { orderRepository.save(order); inventoryService.updateInventory(order.getProductId(), -order.getQuantity()); // Se una delle operazioni fallisce, entrambe verranno annullate } } -
Gestione dei Rollback:
Per impostazione predefinita, Spring effettua il rollback delle transazioni in caso di eccezioni non verificate (subclassi di
RuntimeException). È possibile personalizzare questo comportamento specificando quali eccezioni devono innescare il rollback.Esempio:
@Transactional(rollbackFor = { CustomException.class }) public void processPayment(Payment payment) throws CustomException { // Logica di pagamento if (paymentFailed) { throw new CustomException("Payment processing failed"); } } -
Propagazione delle Transazioni:
Spring supporta diversi livelli di propagazione delle transazioni, controllando come le transazioni si comportano quando chiamano altri metodi transazionali.
Livelli di Propagazione Comuni:
-
REQUIRED(predefinito): Un metodo utilizza la transazione corrente o ne crea una nuova se non esiste. -
REQUIRES_NEW: Sempre crea una nuova transazione, sospendendo quella corrente. -
SUPPORTS: Esegue il metodo all’interno della transazione corrente se esiste, altrimenti esegue senza transazione. -
NOT_SUPPORTED: Esegue il metodo senza alcuna transazione, sospendendo quella corrente se esiste.
Esempio di Propagazione:
@Transactional(propagation = Propagation.REQUIRES_NEW) public void updateStatistics() { // Logica di aggiornamento delle statistiche in una nuova transazione } -
Best Practices per la Gestione delle Transazioni:
-
Definire Chiaramente i Confini delle Transazioni: Limitare l’ambito delle transazioni ai metodi che richiedono effettivamente la gestione transazionale.
-
Evitare Transazioni Lunghe: Ridurre il tempo di esecuzione delle transazioni per migliorare le prestazioni e ridurre la contesa delle risorse.
-
Gestire le Eccezioni Appropriatamente: Assicurarsi che le eccezioni critiche vengano propagate per innescare il rollback.
-
Testare le Transazioni: Verificare che le transazioni si comportino come previsto in scenari di successo e fallimento.
14. Come si effettua il deployment di un’applicazione Spring Boot?
Risposta:
Il deployment di un’applicazione Spring Boot può avvenire in diversi ambienti e piattaforme, tra cui server on-premise, cloud provider, container Docker, e piattaforme serverless. Ecco alcuni dei metodi più comuni:
1. Deployment come JAR Eseguibile:
Spring Boot permette di impacchettare l’applicazione come un JAR eseguibile contenente un server web embedded.
-
Creazione del JAR: Utilizzare il comando
mvn packageo./gradlew buildper generare il JAR eseguibile. -
Esecuzione del JAR: Avviare l’applicazione con il comando:
java -jar myapp.jar
2. Deployment su Server Applicazioni Tradizionali:
È possibile impacchettare l’applicazione come WAR e distribuirla su server come Tomcat, Jetty o WildFly.
-
Configurazione del WAR: Modificare il
pom.xmlper generare un WAR e adattare la classe principale per estendereSpringBootServletInitializer.import org.springframework.boot.builder.SpringApplicationBuilder; import org.springframework.boot.web.servlet.support.SpringBootServletInitializer; public class MyServletInitializer extends SpringBootServletInitializer { @Override protected SpringApplicationBuilder configure(SpringApplicationBuilder application) { return application.sources(MySpringBootApplication.class); } } -
Creazione del WAR: Configurare il packaging in
pom.xml.<packaging>war</packaging> -
Deployment sul Server: Copiare il WAR generato nella cartella di deployment del server applicazioni.
3. Deployment su Cloud Provider:
Spring Boot si integra facilmente con vari cloud provider come AWS, Azure, e Google Cloud.
-
AWS Elastic Beanstalk:
-
Creare un’applicazione Elastic Beanstalk.
-
Caricare il JAR o WAR tramite la console o CLI.
-
Elastic Beanstalk gestisce l’infrastruttura sottostante.
-
-
Google App Engine:
-
Configurare il progetto per App Engine.
-
Utilizzare il comando
gcloud app deployper effettuare il deployment.
-
4. Deployment con Docker:
Containerizzare l’applicazione utilizzando Docker per garantire portabilità e coerenza tra gli ambienti.
-
Creazione del Dockerfile:
FROM openjdk:17-jdk-alpine VOLUME /tmp COPY target/myapp.jar myapp.jar ENTRYPOINT ["java","-jar","/myapp.jar"] -
Build dell’Immagine Docker:
docker build -t myapp:latest . -
Esecuzione del Container:
docker run -p 8080:8080 myapp:latest
5. Deployment su Kubernetes:
Orchestrare container Docker utilizzando Kubernetes per la scalabilità e la gestione avanzata.
-
Creazione di un File di Deployment YAML:
apiVersion: apps/v1 kind: Deployment metadata: name: myapp-deployment spec: replicas: 3 selector: matchLabels: app: myapp template: metadata: labels: app: myapp spec: containers: - name: myapp image: myapp:latest ports: - containerPort: 8080 -
Applicazione del Deployment:
kubectl apply -f deployment.yaml
Best Practices per il Deployment:
-
Automazione: Utilizzare strumenti di CI/CD (Continuous Integration/Continuous Deployment) come Jenkins, GitHub Actions, o GitLab CI per automatizzare il processo di build e deployment.
-
Gestione delle Configurazioni: Separare le configurazioni dalle build utilizzando variabili di ambiente o servizi di gestione delle configurazioni.
-
Sicurezza: Implementare misure di sicurezza adeguate, come la gestione dei segreti e la protezione delle porte di amministrazione.
-
Monitoraggio e Logging: Integrare strumenti di monitoraggio e logging per osservare lo stato dell’applicazione e diagnosticare problemi.
15. Come si configura la gestione delle dipendenze in un progetto Spring Boot?
Risposta:
La gestione delle dipendenze in un progetto Spring Boot è semplificata grazie all’uso dei “Starter POMs” e al parent POM di Spring Boot che fornisce una gestione centralizzata delle versioni delle dipendenze. Questo assicura compatibilità e riduce la necessità di specificare manualmente le versioni delle librerie.
Passaggi per Configurare la Gestione delle Dipendenze:
-
Estendere il Parent POM di Spring Boot:
Impostare il parent POM di Spring Boot nel
pom.xmlper ereditare la gestione delle dipendenze.<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.0.0</version> <relativePath/> <!-- Cerca nel repository centrale --> </parent> -
Aggiungere Dipendenze Tramite Starter POMs:
Includere le dipendenze necessarie utilizzando gli starter appropriati, che aggregano le dipendenze correlate.
<dependencies> <!-- Starter per applicazioni web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Starter per JPA e Hibernate --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <!-- Starter per la sicurezza --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-security</artifactId> </dependency> </dependencies> -
Aggiungere Dipendenze Extra:
Per librerie non incluse negli starter, aggiungerle manualmente specificando le versioni se necessario.
<dependencies> <!-- Dipendenza per Lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- Dipendenza per Test --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies> -
Override delle Versioni delle Dipendenze:
Se è necessario utilizzare una versione diversa di una libreria rispetto a quella gestita dal parent POM, specificarla esplicitamente.
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.14.0</version> <!-- Versione personalizzata --> </dependency> -
Utilizzo di Dependency Management:
Per gestire versioni specifiche in progetti multi-modulo, utilizzare la sezione
<dependencyManagement>.<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>3.0.0</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
Best Practices per la Gestione delle Dipendenze:
-
Evitare Conflitti di Versioni: Fare attenzione a non includere versioni incompatibili di librerie che potrebbero causare conflitti.
-
Aggiornamenti Regolari: Mantenere le dipendenze aggiornate per beneficiare di miglioramenti, correzioni di bug e patch di sicurezza.
-
Minimizzare le Dipendenze: Includere solo le dipendenze necessarie per ridurre la complessità e le dimensioni del progetto.
-
Utilizzare gli Starter di Spring Boot: Favorire l’uso degli starter per semplificare la gestione delle dipendenze e garantire la compatibilità.
16. Come si implementa la validazione dei dati in Spring Boot?
Risposta:
Spring Boot integra la Bean Validation API (JSR 380) per fornire un meccanismo robusto di validazione dei dati. Utilizzando annotazioni di validazione, è possibile definire regole di validità direttamente nei modelli e applicarle automaticamente durante il binding dei dati.
Passaggi per Implementare la Validazione:
-
Aggiungere la Dipendenza per la Validazione:
Includere
spring-boot-starter-validationnelpom.xml.<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency> -
Definire le Annotazioni di Validazione nei Modelli:
Utilizzare annotazioni come
@NotNull,@Size,@Email, ecc., per definire le regole di validità.Esempio:
import jakarta.validation.constraints.Email; import jakarta.validation.constraints.NotBlank; import jakarta.validation.constraints.Size; public class UserDTO { @NotBlank(message = "Il nome è obbligatorio") private String name; @Email(message = "L'email deve essere valida") private String email; @Size(min = 8, message = "La password deve avere almeno 8 caratteri") private String password; // Getter e Setter // ... } -
Applicare la Validazione nei Controller:
Utilizzare l’annotazione
@Validnei parametri del metodo del controller per attivare la validazione.Esempio:
import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.*; import jakarta.validation.Valid; @RestController @RequestMapping("/api/users") public class UserController { private final UserService userService; public UserController(UserService userService) { this.userService = userService; } @PostMapping public ResponseEntity<User> createUser(@Valid @RequestBody UserDTO userDTO) { User user = userService.createUser(userDTO); return new ResponseEntity<>(user, HttpStatus.CREATED); } } -
Gestire gli Errori di Validazione:
Spring Boot gestisce automaticamente gli errori di validazione restituendo una risposta HTTP 400 (Bad Request) con dettagli sugli errori. È possibile personalizzare questo comportamento definendo un
@ControllerAdvice.Esempio di Gestione Personalizzata degli Errori:
import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.MethodArgumentNotValidException; import org.springframework.web.bind.annotation.ExceptionHandler; import org.springframework.web.bind.annotation.RestControllerAdvice; import java.util.HashMap; import java.util.Map; @RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(MethodArgumentNotValidException.class) public ResponseEntity<Map<String, String>> handleValidationExceptions(MethodArgumentNotValidException ex) { Map<String, String> errors = new HashMap<>(); ex.getBindingResult().getFieldErrors().forEach(error -> errors.put(error.getField(), error.getDefaultMessage()) ); return new ResponseEntity<>(errors, HttpStatus.BAD_REQUEST); } }
Best Practices per la Validazione dei Dati:
-
Definire Regole di Validità Chiare: Utilizzare annotazioni di validazione appropriate per assicurare che i dati soddisfino i requisiti di business.
-
Separare i DTO dai Modelli di Dominio: Utilizzare Data Transfer Objects (DTO) per ricevere e inviare dati, separandoli dai modelli di dominio per maggiore flessibilità.
-
Personalizzare i Messaggi di Errore: Fornire messaggi di errore chiari e informativi per migliorare l’esperienza dell’utente.
-
Validare sia Lato Server che Client: Implementare validazioni sia sul client (se applicabile) che sul server per garantire la coerenza e la sicurezza dei dati.
17. Come si utilizza Spring Data JPA in un’applicazione Spring Boot?
Risposta:
Spring Data JPA semplifica l’interazione con i database relazionali fornendo un’astrazione di alto livello per la gestione delle operazioni CRUD (Create, Read, Update, Delete) e delle query personalizzate. Integra perfettamente con Spring Boot, riducendo la quantità di codice boilerplate necessario.
Passaggi per Utilizzare Spring Data JPA:
-
Aggiungere le Dipendenze Necessarie:
Includere
spring-boot-starter-data-jpae il driver del database nelpom.xml.<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies> -
Configurare il Database:
Definire le proprietà del database nel file
application.propertiesoapplication.yml.Esempio in
application.properties:spring.datasource.url=jdbc:h2:mem:testdb spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password= spring.jpa.database-platform=org.hibernate.dialect.H2Dialect spring.jpa.hibernate.ddl-auto=update -
Definire le Entità:
Creare classi di entità annotate con
@Entityche rappresentano le tabelle del database.Esempio:
import jakarta.persistence.Entity; import jakarta.persistence.GeneratedValue; import jakarta.persistence.GenerationType; import jakarta.persistence.Id; @Entity public class Product { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; private Double price; // Getter e Setter // ... } -
Creare i Repository:
Definire interfacce che estendono
JpaRepositoryper fornire operazioni CRUD e query personalizzate.Esempio:
import org.springframework.data.jpa.repository.JpaRepository; import java.util.List; public interface ProductRepository extends JpaRepository<Product, Long> { List<Product> findByNameContaining(String name); } -
Utilizzare i Repository nei Servizi:
Iniettare i repository nei servizi per eseguire operazioni sul database.
Esempio:
import org.springframework.stereotype.Service; import java.util.List; @Service public class ProductService { private final ProductRepository productRepository; public ProductService(ProductRepository productRepository) { this.productRepository = productRepository; } public List<Product> searchProducts(String name) { return productRepository.findByNameContaining(name); } public Product saveProduct(Product product) { return productRepository.save(product); } // Altri metodi CRUD // ... } -
Eseguire le Operazioni nel Controller:
Utilizzare i servizi nei controller per gestire le richieste HTTP.
Esempio:
import org.springframework.web.bind.annotation.*; import java.util.List; @RestController @RequestMapping("/api/products") public class ProductController { private final ProductService productService; public ProductController(ProductService productService) { this.productService = productService; } @GetMapping("/search") public List<Product> searchProducts(@RequestParam String name) { return productService.searchProducts(name); } @PostMapping public Product createProduct(@RequestBody Product product) { return productService.saveProduct(product); } // Altri endpoint CRUD // ... }
Best Practices per l’Uso di Spring Data JPA:
-
Utilizzare Query Methods: Sfruttare i metodi di query generati automaticamente per operazioni comuni, riducendo la necessità di definire query manualmente.
-
Definire Query Personalizzate Quando Necessario: Utilizzare annotazioni come
@Queryper definire query JPQL o SQL personalizzate quando le query methods non sono sufficienti. -
Gestire le Transazioni Adeguatamente: Utilizzare
@Transactionalnei servizi per assicurare la coerenza dei dati durante le operazioni multiple. -
Evitare la Logica Complessa nei Repository: Mantenere la logica di business nei servizi piuttosto che nei repository per una migliore separazione delle preoccupazioni.
-
Ottimizzare le Prestazioni delle Query: Utilizzare tecniche come il caching, la paginazione e il caricamento lazy per migliorare le prestazioni delle applicazioni.
18. Come si implementa l’Inversion of Control (IoC) e la Dependency Injection (DI) in Spring Boot?
Risposta:
L’Inversion of Control (IoC) e la Dependency Injection (DI) sono principi fondamentali di Spring Framework che permettono di gestire le dipendenze tra i componenti in modo flessibile e decoupled. In Spring Boot, questi principi sono implementati tramite il container IoC di Spring, che gestisce il ciclo di vita e l’assemblaggio dei bean.
Inversion of Control (IoC):
IoC è un principio di design in cui il controllo del flusso del programma e delle dipendenze è invertito rispetto alla programmazione tradizionale. Invece di creare direttamente le dipendenze all’interno delle classi, il controllo è delegato al container IoC di Spring.
Dependency Injection (DI):
DI è una tecnica per implementare IoC, in cui le dipendenze di un oggetto vengono fornite (iniettate) dall’esterno piuttosto che create internamente.
Come Implementare IoC e DI in Spring Boot:
-
Definizione dei Bean:
Annotare le classi con annotazioni come
@Component,@Service,@Repository, o@Controllerper indicare che devono essere gestite come bean dal container IoC di Spring.Esempio:
import org.springframework.stereotype.Service; @Service public class EmailService { public void sendEmail(String to, String subject, String body) { // Logica di invio email } } -
Iniezione delle Dipendenze:
Utilizzare l’annotazione
@Autowired, l’iniezione tramite costruttore, o l’iniezione tramite setter per fornire le dipendenze ai bean.Iniezione tramite Costruttore (Consigliata):
import org.springframework.stereotype.Service; @Service public class UserService { private final UserRepository userRepository; private final EmailService emailService; // Iniezione tramite costruttore public UserService(UserRepository userRepository, EmailService emailService) { this.userRepository = userRepository; this.emailService = emailService; } public void registerUser(User user) { userRepository.save(user); emailService.sendEmail(user.getEmail(), "Welcome", "Thank you for registering!"); } }Iniezione con
@Autowired:import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; @Service public class NotificationService { private EmailService emailService; @Autowired public void setEmailService(EmailService emailService) { this.emailService = emailService; } public void notifyUser(User user) { emailService.sendEmail(user.getEmail(), "Notification", "You have a new message."); } } -
Configurazione Manuale dei Bean (Se Necessario):
Utilizzare classi di configurazione annotate con
@Configuratione definire metodi annotati con@Beanper creare bean personalizzati.Esempio:
import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class AppConfig { @Bean public RestTemplate restTemplate() { return new RestTemplate(); } }Iniezione del Bean Personalizzato:
import org.springframework.stereotype.Service; import org.springframework.web.client.RestTemplate; @Service public class ExternalService { private final RestTemplate restTemplate; public ExternalService(RestTemplate restTemplate) { this.restTemplate = restTemplate; } public String fetchData(String url) { return restTemplate.getForObject(url, String.class); } }
Vantaggi di IoC e DI:
-
Decoupling: Riduce le dipendenze strette tra i componenti, facilitando la manutenzione e il testing.
-
Flessibilità: Permette di cambiare le implementazioni delle dipendenze senza modificare il codice che le utilizza.
-
Testabilità: Facilita il mocking delle dipendenze nei test unitari.
Best Practices per IoC e DI:
-
Preferire l’Iniezione tramite Costruttore: Migliora l’immutabilità e facilita il testing.
-
Evitare l’Iniezione di Dipendenze Statiche: Mantiene la flessibilità e la testabilità.
-
Limitare l’Uso di
@Autowired: Utilizzare l’iniezione tramite costruttore per una migliore leggibilità e manutenzione. -
Utilizzare Interfacce per le Dipendenze: Favorisce l’uso di implementazioni intercambiabili e facilita il mocking nei test.
19. Come si utilizzano le annotazioni @Controller, @RestController e @Service in Spring Boot?
Risposta:
In Spring Boot, le annotazioni @Controller, @RestController e @Service sono utilizzate per definire componenti gestiti dal container IoC di Spring, con ruoli e comportamenti specifici nell’architettura dell’applicazione.
1. @Controller:
L’annotazione @Controller viene utilizzata per definire una classe come controller MVC (Model-View-Controller) che gestisce le richieste HTTP e restituisce le viste (tipicamente template HTML).
Esempio:
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class HomeController {
@GetMapping("/")
public String home(Model model) {
model.addAttribute("message", "Benvenuto su Spring Boot!");
return "home"; // Nome del template HTML
}
}2. @RestController:
@RestController è una specializzazione di @Controller che combina @Controller e @ResponseBody. Viene utilizzato per definire controller che restituiscono direttamente i dati (tipicamente in formato JSON o XML) senza il passaggio attraverso una vista.
Esempio:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ApiController {
@GetMapping("/api/message")
public String getMessage() {
return "Hello, World!";
}
}3. @Service:
L’annotazione @Service viene utilizzata per definire una classe come servizio di business logic. È un tipo di @Component che indica che la classe contiene la logica di business e interagisce con i repository per gestire i dati.
Esempio:
import org.springframework.stereotype.Service;
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public User createUser(User user) {
// Logica di business per creare un utente
return userRepository.save(user);
}
// Altri metodi di business
// ...
}Differenze Principali:
-
@Controllervs@RestController:-
@Controllerè utilizzato per applicazioni web tradizionali che restituiscono viste (HTML). -
@RestControllerè utilizzato per API RESTful che restituiscono direttamente i dati (JSON, XML).
-
-
@Service:@Serviceidentifica una classe come contenitore della logica di business, separando il livello di presentazione dal livello di business e dal livello di accesso ai dati.
Best Practices nell’Uso delle Annotazioni:
-
Separazione delle Responsabilità: Utilizzare
@Controllerper la gestione delle interfacce utente,@RestControllerper API REST, e@Serviceper la logica di business. -
Consistenza: Mantenere un utilizzo coerente delle annotazioni per facilitare la comprensione e la manutenzione del codice.
-
Utilizzo di Interfacce: Definire interfacce per i servizi e implementarle, migliorando la testabilità e la flessibilità del codice.
-
Iniezione delle Dipendenze: Utilizzare l’iniezione tramite costruttore per garantire che le dipendenze siano fornite in modo chiaro e sicuro.
20.3 Esercizi Pratici e Problemi da Risolvere
In questa sezione, proponiamo una serie di esercizi pratici progettati per consolidare le conoscenze acquisite e migliorare le capacità di problem solving. Questi esercizi coprono vari aspetti di Java e Spring Boot, inclusi concetti di base, programmazione orientata agli oggetti, gestione delle eccezioni, persistenza dei dati, sicurezza, e sviluppo di microservizi.
Esercizio 1: Creazione di un’Applicazione CRUD con Spring Boot
Descrizione:
Crea un’applicazione Spring Boot che gestisce un’entità Book con i campi id, title, author, e isbn. Implementa le operazioni CRUD (Create, Read, Update, Delete) tramite un’API RESTful.
Requisiti:
-
Definire l’entità
Bookcon le annotazioni JPA appropriate. -
Creare un repository
BookRepositoryestendendoJpaRepository. -
Implementare un servizio
BookServiceche utilizza il repository. -
Definire un controller
BookControllercon endpoint per le operazioni CRUD. -
Implementare la validazione dei dati per assicurare che
titleeauthornon siano vuoti e cheisbnabbia una lunghezza valida.
Suggerimenti:
-
Utilizza
@RestControllerper il controller. -
Utilizza
@Validnei parametri del controller per attivare la validazione. -
Gestisci le eccezioni di entità non trovate con un
@ControllerAdvice.
Esercizio 2: Implementazione della Sicurezza con Spring Security
Descrizione:
Estendi l’applicazione CRUD creata nell’Esercizio 1 per includere la sicurezza. Solo gli utenti autenticati possono eseguire operazioni CRUD, e solo gli utenti con il ruolo ADMIN possono eliminare un libro.
Requisiti:
-
Configurare Spring Security per autenticare gli utenti.
-
Definire due utenti in memoria: uno con ruolo
USERe uno con ruoloADMIN. -
Proteggere gli endpoint CRUD in modo che solo gli utenti autenticati possano accedervi.
-
Limitare l’operazione di eliminazione (
DELETE) solo agli utenti con il ruoloADMIN.
Suggerimenti:
-
Utilizza
@EnableWebSecuritye configura ilSecurityFilterChain. -
Utilizza
@PreAuthorizeo@Securedper limitare l’accesso agli endpoint.
Esercizio 3: Gestione delle Eccezioni Personalizzate
Descrizione:
Implementa una gestione delle eccezioni personalizzata per l’applicazione CRUD. Crea un’eccezione BookNotFoundException che viene lanciata quando un libro con un determinato ID non viene trovato. Gestisci questa eccezione in modo da restituire una risposta HTTP 404 con un messaggio di errore dettagliato.
Requisiti:
-
Definire la classe
BookNotFoundExceptionestendendoRuntimeException. -
Modificare il servizio
BookServiceper lanciareBookNotFoundExceptionquando un libro non viene trovato. -
Creare un
@ControllerAdviceche gestisceBookNotFoundExceptione restituisce una risposta appropriata.
Suggerimenti:
- Utilizza
@ExceptionHandlernel@ControllerAdviceper gestire l’eccezione.
Esercizio 4: Implementazione di Paginazione e Ordinamento
Descrizione:
Aggiungi funzionalità di paginazione e ordinamento all’API RESTful dell’applicazione CRUD. Permetti agli utenti di ottenere una lista di libri paginata e ordinata per titolo o autore.
Requisiti:
-
Modificare il repository
BookRepositoryper supportare la paginazione e l’ordinamento. -
Aggiornare il controller
BookControllerper accettare parametri di pagina, dimensione e ordinamento. -
Restituire i risultati paginati e ordinati come risposta.
Suggerimenti:
-
Utilizza
PageableePagedi Spring Data. -
Esempio di richiesta:
GET /api/books?page=0&size=10&sort=title,asc
Esercizio 5: Creazione di un Microservizio con Spring Boot
Descrizione:
Dividi l’applicazione CRUD in due microservizi separati: BookService e AuthorService. Il BookService gestisce i libri, mentre l’AuthorService gestisce gli autori. Implementa la comunicazione tra i microservizi utilizzando REST.
Requisiti:
-
Creare due progetti Spring Boot distinti: uno per i libri e uno per gli autori.
-
Definire le entità
BookeAuthorin ciascun microservizio. -
Implementare endpoint REST in entrambi i microservizi per gestire le operazioni CRUD.
-
Nel
BookService, aggiungere un endpoint che, dato un libro, recupera le informazioni dell’autore dalAuthorService.
Suggerimenti:
-
Utilizza
RestTemplateoWebClientper la comunicazione tra microservizi. -
Configura Eureka per la scoperta dei servizi se desideri un approccio più avanzato.
Esercizio 6: Implementazione di Test Unitari e di Integrazione
Descrizione:
Scrivi test unitari per il servizio BookService e test di integrazione per il controller BookController dell’applicazione CRUD.
Requisiti:
-
Utilizzare JUnit e Mockito per scrivere test unitari che verificano le operazioni CRUD del
BookService. -
Utilizzare
@SpringBootTesteMockMvcper scrivere test di integrazione che verificano gli endpoint delBookController. -
Assicurarsi che i test coprano scenari positivi e negativi, inclusi casi di validazione e gestione delle eccezioni.
Suggerimenti:
-
Mockare le dipendenze nei test unitari per isolare il comportamento del servizio.
-
Utilizzare
@AutoConfigureMockMvcnei test di integrazione per configurareMockMvc.
Esercizio 7: Configurazione di un Ambiente di Deployment con Docker
Descrizione:
Containerizza l’applicazione CRUD utilizzando Docker e crea un’immagine Docker che può essere eseguita in qualsiasi ambiente.
Requisiti:
-
Creare un
Dockerfileche utilizza un’immagine base di Java e copia il JAR dell’applicazione. -
Configurare il
Dockerfileper eseguire l’applicazione all’avvio del container. -
Costruire l’immagine Docker e testarla localmente.
Esempio di Dockerfile:
FROM openjdk:17-jdk-alpine
VOLUME /tmp
COPY target/bookservice.jar bookservice.jar
ENTRYPOINT ["java","-jar","/bookservice.jar"]Comandi per Costruire ed Eseguire l’Immagine:
docker build -t bookservice:latest .
docker run -p 8080:8080 bookservice:latest
Esercizio 8: Implementazione di una Funzionalità di Ricerca Avanzata
Descrizione:
Aggiungi una funzionalità di ricerca avanzata all’API RESTful dell’applicazione CRUD che consente di cercare libri per titolo, autore e intervallo di prezzo.
Requisiti:
-
Modificare il repository
BookRepositoryper includere metodi di ricerca personalizzati. -
Aggiornare il controller
BookControllerper accettare parametri di ricerca tramite query string. -
Restituire i risultati filtrati in base ai criteri di ricerca forniti.
Suggerimenti:
-
Utilizza
@Queryper definire query JPQL personalizzate. -
Gestisci i parametri opzionali utilizzando oggetti DTO o
@RequestParamcon valori predefiniti.
Esercizio 9: Implementazione del Caching con Spring Boot
Descrizione:
Migliora le prestazioni dell’applicazione CRUD implementando il caching per le operazioni di lettura dei libri.
Requisiti:
-
Abilitare il supporto al caching nell’applicazione utilizzando
@EnableCaching. -
Configurare una cache, ad esempio con Caffeine o Ehcache.
-
Annotare i metodi di lettura nel servizio
BookServicecon@Cacheablee i metodi di modifica con@CacheEvict.
Esempio:
import org.springframework.cache.annotation.Cacheable;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.stereotype.Service;
@Service
public class BookService {
private final BookRepository bookRepository;
// Costruttore
@Cacheable(value = "books", key = "#id")
public Book getBookById(Long id) {
return bookRepository.findById(id)
.orElseThrow(() -> new BookNotFoundException("Book not found with id " + id));
}
@CacheEvict(value = "books", key = "#book.id")
public Book updateBook(Book book) {
return bookRepository.save(book);
}
@CacheEvict(value = "books", key = "#id")
public void deleteBook(Long id) {
bookRepository.deleteById(id);
}
// Altri metodi
}Configurazione del Caching:
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableCaching
public class CacheConfig {
// Configurazioni aggiuntive per la cache possono essere aggiunte qui
}Esercizio 10: Implementazione di WebSockets per Notifiche in Tempo Reale
Descrizione:
Aggiungi la funzionalità di notifiche in tempo reale all’applicazione CRUD utilizzando WebSockets. Quando un nuovo libro viene aggiunto, invia una notifica a tutti i client connessi.
Requisiti:
-
Configurare WebSockets nell’applicazione Spring Boot.
-
Definire un endpoint WebSocket per le notifiche.
-
Modificare il servizio
BookServiceper inviare notifiche quando un nuovo libro viene creato. -
Implementare un client WebSocket (ad esempio, utilizzando JavaScript) per ricevere e visualizzare le notifiche.
Suggerimenti:
-
Utilizza
@EnableWebSocketMessageBrokere configura i broker di messaggi. -
Utilizza
SimpMessagingTemplateper inviare messaggi ai client.
Esempio di Configurazione WebSocket:
import org.springframework.context.annotation.Configuration;
import org.springframework.messaging.simp.config.MessageBrokerRegistry;
import org.springframework.web.socket.config.annotation.*;
@Configuration
@EnableWebSocketMessageBroker
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/ws-notifications").withSockJS();
}
@Override
public void configureMessageBroker(MessageBrokerRegistry config) {
config.enableSimpleBroker("/topic");
config.setApplicationDestinationPrefixes("/app");
}
}Invio di Notifiche dal Servizio:
import org.springframework.messaging.simp.SimpMessagingTemplate;
import org.springframework.stereotype.Service;
@Service
public class BookService {
private final BookRepository bookRepository;
private final SimpMessagingTemplate messagingTemplate;
// Costruttore
public Book createBook(Book book) {
Book savedBook = bookRepository.save(book);
messagingTemplate.convertAndSend("/topic/books", savedBook);
return savedBook;
}
// Altri metodi
}Implementazione del Client WebSocket (JavaScript):
const socket = new SockJS('/ws-notifications');
const stompClient = Stomp.over(socket);
stompClient.connect({}, function (frame) {
console.log('Connected: ' + frame);
stompClient.subscribe('/topic/books', function (book) {
const bookData = JSON.parse(book.body);
console.log('New Book Added:', bookData);
// Aggiornare l'interfaccia utente con i nuovi dati
});
});Questi esercizi pratici offrono un’opportunità per applicare i concetti teorici appresi e sviluppare competenze concrete nello sviluppo di applicazioni Java e Spring Boot. È consigliabile affrontare ciascun esercizio passo dopo passo, verificando il funzionamento delle soluzioni implementate e approfondendo ulteriormente gli argomenti correlati.
20.4 Altri esercizi
Questa sezione offre un'altra serie di esercizi pratici e problemi progettati per mettere alla prova e rafforzare le tue competenze in Java e Spring Boot. Gli esercizi variano in difficoltà e coprono una vasta gamma di argomenti, permettendoti di consolidare le conoscenze acquisite e migliorare le tue capacità di risoluzione dei problemi. Ogni esercizio include una descrizione dettagliata e suggerimenti per aiutarti nell’implementazione.
Sezione 1: Esercizi di Programmazione in Java
Esercizio 1: Implementazione di una Linked List Singola
Descrizione:
Implementa una struttura dati Linked List singola in Java. La lista dovrebbe supportare le operazioni di inserimento in testa, inserimento in coda, rimozione di un elemento specifico e ricerca di un elemento.
Requisiti:
-
Definire una classe
Nodeche rappresenta un nodo della lista. -
Definire una classe
LinkedListcon i metodi:-
void insertAtHead(T data) -
void insertAtTail(T data) -
boolean remove(T data) -
boolean contains(T data) -
void display()
-
Suggerimenti:
-
Utilizza generics per rendere la lista generica.
-
Gestisci i casi particolari come l’inserimento o la rimozione di elementi in una lista vuota.
Esercizio 2: Gestione delle Eccezioni Personalizzate
Descrizione:
Crea un’applicazione che gestisce le operazioni bancarie di base, come prelievo e deposito. Implementa eccezioni personalizzate per gestire situazioni come saldo insufficiente e operazioni non valide.
Requisiti:
-
Definire una classe
InsufficientFundsExceptionche estendeException. -
Definire una classe
InvalidOperationExceptionche estendeException. -
Implementare una classe
BankAccountcon i metodi:-
void deposit(double amount) -
void withdraw(double amount)che lanciaInsufficientFundsExceptionse il saldo è insufficiente.
-
-
Gestire le eccezioni nel metodo
main.
Suggerimenti:
-
Assicurati di fornire messaggi di errore chiari nelle eccezioni.
-
Implementa controlli per evitare operazioni con importi negativi.
Esercizio 3: Utilizzo dei Generics e delle Collezioni
Descrizione:
Crea una classe generica Pair che memorizza due oggetti di tipi potenzialmente diversi. Implementa metodi per ottenere e impostare i valori. Successivamente, utilizza questa classe in una collezione per memorizzare coppie di elementi.
Requisiti:
-
Definire la classe
Pair<T, U>con i metodigetFirst(),getSecond(),setFirst(T first),setSecond(U second). -
Creare una
List<Pair<String, Integer>>che memorizza nomi e età. -
Popola la lista con almeno 5 elementi e stampa i contenuti.
Suggerimenti:
-
Utilizza i generics per garantire la tipizzazione sicura.
-
Esplora l’uso di
ArrayListper implementare la lista.
Sezione 2: Esercizi con Spring Boot
Esercizio 4: Creazione di una RESTful API per la Gestione di Libri
Descrizione:
Sviluppa una semplice API RESTful utilizzando Spring Boot per gestire un catalogo di libri. L’API dovrebbe supportare operazioni CRUD (Create, Read, Update, Delete).
Requisiti:
-
Definire un’entità
Bookcon attributi comeid,title,author,isbn. -
Configurare Spring Data JPA e un database in memoria (H2).
-
Implementare un repository
BookRepositoryestendendoJpaRepository. -
Creare un controller
BookControllercon endpoint:-
GET /books- recupera tutti i libri. -
GET /books/{id}- recupera un libro per ID. -
POST /books- aggiunge un nuovo libro. -
PUT /books/{id}- aggiorna un libro esistente. -
DELETE /books/{id}- elimina un libro.
-
Suggerimenti:
-
Utilizza le annotazioni di Spring come
@RestController,@RequestMapping,@Autowired. -
Gestisci le eccezioni per casi come libro non trovato.
Esercizio 5: Implementazione della Sicurezza con Spring Security
Descrizione:
Aggiungi sicurezza all’API creata nell’Esercizio 4 utilizzando Spring Security. Implementa l’autenticazione di base e limita l’accesso alle operazioni CRUD solo agli utenti autenticati.
Requisiti:
-
Configurare Spring Security nel progetto Spring Boot.
-
Definire un utente in memoria con username e password.
-
Proteggere gli endpoint dell’API in modo che solo gli utenti autenticati possano accedere.
-
Testare l’API utilizzando strumenti come Postman, fornendo le credenziali corrette.
Suggerimenti:
-
Utilizza la configurazione basata su Java con
@EnableWebSecurity. -
Esplora l’uso di
HttpSecurityper definire le regole di sicurezza.
Esercizio 6: Creazione di Microservizi con Spring Boot e Spring Cloud
Descrizione:
Sviluppa due microservizi separati utilizzando Spring Boot: uno per la gestione degli utenti e uno per la gestione degli ordini. Configura la discovery service utilizzando Eureka e abilita la comunicazione tra i microservizi.
Requisiti:
-
Microservizio Utenti:
-
Entità
Usercon attributi comeid,name,email. -
CRUD endpoints per gestire gli utenti.
-
-
Microservizio Ordini:
-
Entità
Ordercon attributi comeid,userId,product,quantity. -
CRUD endpoints per gestire gli ordini.
-
-
Discovery Service:
-
Configura un server Eureka.
-
Registra entrambi i microservizi su Eureka.
-
-
Comunicazione:
- Implementa la chiamata dall’ordine per recuperare i dettagli dell’utente tramite
RestTemplateoFeign.
- Implementa la chiamata dall’ordine per recuperare i dettagli dell’utente tramite
Suggerimenti:
-
Configura correttamente le proprietà
application.propertiesper ogni microservizio. -
Utilizza le annotazioni di Spring Cloud come
@EnableEurekaServere@EnableEurekaClient. -
Gestisci la resilienza e il failover con Ribbon o Hystrix.
Esercizio 7: Testing delle Applicazioni Spring Boot
Descrizione:
Implementa test unitari e di integrazione per l’API dei libri creata nell’Esercizio 4 utilizzando JUnit e Mockito.
Requisiti:
-
Scrivi test unitari per il
BookControllermockando ilBookRepository. -
Scrivi test di integrazione utilizzando
@SpringBootTeste testando gli endpoint REST conMockMvc. -
Assicurati che i test coprano scenari positivi e negativi, come la ricerca di un libro esistente e la gestione di un libro non trovato.
Suggerimenti:
-
Utilizza le annotazioni
@MockBeane@Autowiredper iniettare le dipendenze nei test. -
Configura il contesto di test per isolare le componenti da testare.
Esercizio 8: Ottimizzazione delle Prestazioni con la Cache
Descrizione:
Aggiungi una cache all’API dei libri per migliorare le prestazioni delle richieste di lettura. Utilizza Spring Cache con una implementazione come Caffeine o Ehcache.
Requisiti:
-
Configura Spring Cache nel progetto.
-
Annota i metodi di recupero dei libri (
GET /bookseGET /books/{id}) con@Cacheable. -
Implementa la cache eviction utilizzando
@CacheEvictnei metodi di aggiornamento e cancellazione. -
Testa l’efficacia della cache misurando i tempi di risposta prima e dopo l’implementazione.
Suggerimenti:
-
Scegli un provider di cache adatto e aggiungi le dipendenze necessarie.
-
Configura le proprietà della cache per gestire la dimensione e la scadenza degli elementi.
Esercizio 9: Implementazione di Validazioni Avanzate
Descrizione:
Migliora l’API dei libri implementando validazioni avanzate sui dati di input utilizzando Bean Validation (Hibernate Validator).
Requisiti:
-
Aggiungi annotazioni di validazione alle proprietà dell’entità
Book, come@NotNull,@Size,@Pattern. -
Gestisci le eccezioni di validazione globalmente utilizzando
@ControllerAdvicee@ExceptionHandler. -
Verifica che le richieste con dati non validi restituiscano risposte appropriate con messaggi di errore.
Suggerimenti:
-
Utilizza
@Validnei controller per attivare la validazione. -
Personalizza i messaggi di errore per renderli più chiari agli utenti dell’API.
Esercizio 10: Deploy dell’Applicazione su Docker
Descrizione:
Containerizza l’API dei libri utilizzando Docker e configura un file Dockerfile per creare un’immagine Docker dell’applicazione Spring Boot.
Requisiti:
-
Scrivi un
Dockerfileche utilizza una base Java appropriata (es.openjdk:17-jdk-slim). -
Compila l’applicazione in un jar eseguibile.
-
Configura il
Dockerfileper copiare il jar nell’immagine e definire il comando di avvio. -
Costruisci l’immagine Docker e avvia un container.
-
Verifica che l’API sia accessibile tramite Docker.
Suggerimenti:
-
Ottimizza il
Dockerfileper ridurre le dimensioni dell’immagine, ad esempio utilizzando più stadi di build. -
Utilizza
docker-composeper semplificare la gestione dei container, soprattutto se utilizzi un database separato.
Consigli per Sfruttare al Meglio gli Esercizi
-
Pianificazione e Organizzazione:
-
Dedica tempo a comprendere pienamente ogni esercizio prima di iniziare.
-
Suddividi gli esercizi in sotto-attività gestibili.
-
-
Documentazione e Risorse:
-
Utilizza la documentazione ufficiale di Java e Spring Boot per approfondire i concetti.
-
Cerca esempi e tutorial online per ottenere diverse prospettive sulla risoluzione dei problemi.
-
-
Debugging e Test:
-
Implementa test unitari e di integrazione per verificare il corretto funzionamento del tuo codice.
-
Utilizza strumenti di debugging per identificare e risolvere eventuali problemi.
-
-
Revisione e Ottimizzazione:
-
Rivedi il tuo codice per migliorare la leggibilità e l’efficienza.
-
Applica best practices come la scrittura di codice pulito, l’uso appropriato dei design pattern e l’ottimizzazione delle prestazioni.
-
-
Collaborazione e Feedback:
-
Condividi i tuoi esercizi con colleghi o nella community per ottenere feedback costruttivo.
-
Partecipa a code review per imparare da altri sviluppatori e migliorare le tue competenze.
-
-
Ripetizione e Consolidamento:
-
Ripeti gli esercizi più complessi fino a quando non ti senti completamente a tuo agio con essi.
-
Crea varianti degli esercizi per esplorare scenari diversi e approfondire la tua comprensione.
-
Completare questi esercizi ti permetterà di consolidare le tue conoscenze teoriche con competenze pratiche essenziali, preparandoti in modo efficace per affrontare colloqui tecnici e sfide reali nel mondo dello sviluppo Java e Spring Boot.
Appendice B: Argomenti Avanzati Spring
Questa appendice si propone di coprire una serie di argomenti avanzati relativi a Spring Boot e al framework Spring, fondamentali per affrontare con successo colloqui tecnici mirati all’assunzione di programmatori backend specializzati. Gli argomenti trattati includono concetti avanzati di programmazione, best practices, integrazioni e strumenti essenziali per lo sviluppo di applicazioni robuste e scalabili.
1. Spring AOP (Aspect-Oriented Programming)
Aspect-Oriented Programming (AOP) è un paradigma di programmazione che consente di separare le cross-cutting concerns (concetti trasversali) dal codice business, migliorando la modularità e la manutenzione del codice.
-
Concetti Fondamentali:
-
Join Point: Punti di esecuzione nel programma (es. chiamata di metodo, esecuzione di costruttore).
-
Pointcut: Espressioni che definiscono quali join point saranno intercettati.
-
Advice: Azioni eseguite in corrispondenza dei join point (es.
@Before,@After,@Around). -
Aspect: Combina pointcut e advice per definire un comportamento trasversale.
-
-
Esempio di Aspect:
@Aspect @Component public class LoggingAspect { @Before("execution(* com.esempio.service.*.*(..))") public void logBeforeMethod(JoinPoint joinPoint) { System.out.println("Esecuzione metodo: " + joinPoint.getSignature().getName()); } @After("execution(* com.esempio.service.*.*(..))") public void logAfterMethod(JoinPoint joinPoint) { System.out.println("Metodo eseguito: " + joinPoint.getSignature().getName()); } @Around("execution(* com.esempio.service.*.*(..))") public Object logAroundMethod(ProceedingJoinPoint joinPoint) throws Throwable { System.out.println("Prima dell'esecuzione: " + joinPoint.getSignature().getName()); Object result = joinPoint.proceed(); System.out.println("Dopo l'esecuzione: " + joinPoint.getSignature().getName()); return result; } } -
Applicazioni Pratiche:
-
Logging: Registrazione automatica delle chiamate ai metodi.
-
Gestione delle Transazioni: Controllo delle transazioni in modo trasparente.
-
Sicurezza: Applicazione di controlli di accesso a livello di metodo.
-
2. Spring Batch
Spring Batch è un framework che facilita lo sviluppo di applicazioni di elaborazione batch robuste ed efficienti.
-
Componenti Principali:
-
Job: Rappresenta un processo batch completo.
-
Step: Singoli passaggi all’interno di un job.
-
ItemReader: Legge i dati da una fonte (es. database, file).
-
ItemProcessor: Elabora i dati letti.
-
ItemWriter: Scrive i dati elaborati su una destinazione.
-
-
Configurazione di un Job Batch:
@Configuration @EnableBatchProcessing public class BatchConfig { @Autowired private JobBuilderFactory jobBuilderFactory; @Autowired private StepBuilderFactory stepBuilderFactory; @Bean public Job importUserJob(JobCompletionNotificationListener listener, Step step1) { return jobBuilderFactory.get("importUserJob") .listener(listener) .flow(step1) .end() .build(); } @Bean public Step step1(ItemReader<User> reader, ItemProcessor<User, User> processor, ItemWriter<User> writer) { return stepBuilderFactory.get("step1") .<User, User> chunk(10) .reader(reader) .processor(processor) .writer(writer) .build(); } } -
Gestione del Riavvio: Configurazione per permettere il riavvio dei job in caso di fallimenti.
3. Spring Integration
Spring Integration offre un’implementazione di Enterprise Integration Patterns (EIP) per facilitare la comunicazione tra componenti di un’applicazione.
-
Concetti Chiave:
-
Channel: Mezzo attraverso cui i messaggi vengono inviati e ricevuti.
-
Message: Un’unità di dati trasferita tra componenti.
-
Transformer: Modifica il contenuto dei messaggi.
-
Gateway: Punto di accesso per inviare o ricevere messaggi.
-
-
Esempio di Flusso di Messaggi:
@Configuration @EnableIntegration public class IntegrationConfig { @Bean public IntegrationFlow myFlow() { return IntegrationFlows.from("inputChannel") .transform(payload -> ((String) payload).toUpperCase()) .handle("myService", "process") .get(); } } -
Integrazione con Sistemi Esteri: JMS, Kafka, e altri sistemi di messaggistica.
4. WebFlux e Reattività
Spring WebFlux è un framework reattivo per lo sviluppo di applicazioni web non bloccanti.
-
Concetti Principali:
-
Reattività: Gestione asincrona delle richieste per migliorare la scalabilità.
-
Mono e Flux: Tipi reattivi che rappresentano flussi di dati.
-
-
Esempio di Controller Reattivo:
@RestController public class ReactiveController { @GetMapping("/mono") public Mono<String> getMono() { return Mono.just("Hello, WebFlux!"); } @GetMapping("/flux") public Flux<String> getFlux() { return Flux.just("Hello", "Reactive", "World!"); } } -
WebSockets: Comunicazione bidirezionale in tempo reale.
5. Annotazioni Avanzate
Le annotazioni in Spring sono fondamentali per la configurazione e la gestione dei componenti. Questo segmento approfondisce l’uso avanzato delle annotazioni, inclusa la creazione di annotazioni personalizzate.
-
Creazione di Annotazioni Personalizzate:
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface LogExecutionTime { } -
Meta-annotazioni:
-
@Retention: Specifica la durata dell’annotazione (es. RUNTIME).
-
@Target: Definisce dove può essere applicata l’annotazione (es. METHOD, TYPE).
-
@Inherited: Indica che l’annotazione è ereditata dalle sottoclassi.
-
-
Uso di Annotazioni Personalizzate con AOP:
@Aspect @Component public class LogExecutionTimeAspect { @Around("@annotation(com.esempio.annotations.LogExecutionTime)") public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable { long start = System.currentTimeMillis(); Object proceed = joinPoint.proceed(); long executionTime = System.currentTimeMillis() - start; System.out.println(joinPoint.getSignature() + " executed in " + executionTime + "ms"); return proceed; } }
6. Gestione di Profili e Configurazioni
La gestione di diverse configurazioni per ambienti differenti è cruciale per applicazioni enterprise.
-
Profili in Spring Boot:
-
@Profile: Definisce quali bean sono attivi in base al profilo corrente.
-
Attivazione dei Profili: Tramite proprietà
spring.profiles.activeo variabili d’ambiente.
-
-
Esempio di Configurazione per Profili:
@Configuration @Profile("dev") public class DevConfig { // Bean specifici per l'ambiente di sviluppo } @Configuration @Profile("prod") public class ProdConfig { // Bean specifici per l'ambiente di produzione } -
Iniezione di Valori di Configurazione:
@Value("${app.title}") private String appTitle;
7. Security Avanzata con Spring Security
La sicurezza è un aspetto fondamentale nello sviluppo di applicazioni backend. Spring Security offre strumenti avanzati per gestire autenticazione e autorizzazione.
-
Autenticazione e Autorizzazione Avanzate:
-
OAuth2 e JWT: Implementazione di autenticazione basata su token.
-
OAuth2 Resource Server: Protezione delle API RESTful.
-
-
Sicurezza a Livello di Metodo:
-
@PreAuthorize e @PostAuthorize: Controlli di sicurezza basati su espressioni SpEL.
@PreAuthorize("hasRole('ADMIN')") public void adminOnlyMethod() { // Metodo accessibile solo agli admin }
-
-
Configurazione Personalizzata:
@Configuration @EnableWebSecurity public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http .authorizeRequests() .antMatchers("/admin/**").hasRole("ADMIN") .antMatchers("/user/**").hasRole("USER") .anyRequest().authenticated() .and() .formLogin() .permitAll() .and() .logout() .permitAll(); } @Bean @Override public UserDetailsService userDetailsService() { UserDetails user = User.withDefaultPasswordEncoder() .username("user") .password("password") .roles("USER") .build(); UserDetails admin = User.withDefaultPasswordEncoder() .username("admin") .password("admin") .roles("ADMIN") .build(); return new InMemoryUserDetailsManager(user, admin); } }
8. Logging Avanzato
Il logging efficace è essenziale per il monitoraggio e il debugging delle applicazioni.
-
Framework di Logging Supportati:
-
Logback: Implementazione predefinita in Spring Boot.
-
Log4j2: Alternativa con funzionalità avanzate.
-
-
Configurazione Personalizzata:
logging: level: com.esempio: DEBUG pattern: console: "%d{yyyy-MM-dd HH:mm:ss} - %msg%n" -
Integrazione con Sistemi Esterni:
-
ELK Stack (Elasticsearch, Logstash, Kibana): Raccolta e visualizzazione dei log.
-
Grafana Loki: Sistema di aggregazione dei log.
-
-
Uso di MDC (Mapped Diagnostic Context):
import org.slf4j.MDC; public void someMethod() { MDC.put("userId", "12345"); logger.info("Esecuzione metodo con userId"); MDC.clear(); }
9. Deployment Avanzato
Il deployment efficiente delle applicazioni è cruciale per garantire scalabilità e affidabilità.
-
Docker:
-
Creazione di un Dockerfile:
FROM openjdk:17-jdk-alpine VOLUME /tmp COPY target/app.jar app.jar ENTRYPOINT ["java","-jar","/app.jar"] -
Costruzione e Esecuzione dell’Immagine:
docker build -t my-spring-boot-app . docker run -p 8080:8080 my-spring-boot-app
-
-
Orchestrazione con Kubernetes:
-
Definizione di un Deployment:
apiVersion: apps/v1 kind: Deployment metadata: name: spring-boot-deployment spec: replicas: 3 selector: matchLabels: app: spring-boot template: metadata: labels: app: spring-boot spec: containers: - name: spring-boot image: my-spring-boot-app:latest ports: - containerPort: 8080
-
-
Strategie di Scalabilità e Load Balancing:
-
Horizontal Pod Autoscaler: Aumenta o riduce il numero di pod in base al carico.
-
Service di Kubernetes: Bilanciamento del carico tra i pod.
-
-
Best Practices per il Deployment in Cloud:
-
Configurazione di Ambienti Separati: Dev, Staging, Production.
-
Gestione delle Migrazioni del Database: Uso di strumenti come Flyway o Liquibase.
-
10. Spring Cloud
Spring Cloud fornisce strumenti per lo sviluppo di applicazioni distribuite e microservizi.
-
Service Discovery:
-
Eureka:
@EnableEurekaClient @SpringBootApplication public class EurekaClientApplication { public static void main(String[] args) { SpringApplication.run(EurekaClientApplication.class, args); } } -
Consul: Alternativa a Eureka per la scoperta dei servizi.
-
-
Configurazione Centralizzata:
-
Spring Cloud Config Server:
@EnableConfigServer @SpringBootApplication public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class, args); } }
-
-
Circuit Breaker Pattern:
-
Resilience4j:
@CircuitBreaker(name = "backendService", fallbackMethod = "fallback") public String callBackendService() { // Chiamata al servizio esterno } public String fallback(Throwable t) { return "Fallback response"; }
-
-
API Gateway:
-
Spring Cloud Gateway:
@SpringBootApplication public class ApiGatewayApplication { public static void main(String[] args) { SpringApplication.run(ApiGatewayApplication.class, args); } }
-
11. Scheduling e Automazione dei Task
La pianificazione di task ricorrenti è spesso necessaria per operazioni periodiche come l’elaborazione dei dati o l’invio di notifiche.
-
Abilitazione dello Scheduling:
@Configuration @EnableScheduling public class SchedulingConfig { } -
Utilizzo dell’Annotazione
@Scheduled:@Component public class ScheduledTasks { @Scheduled(cron = "0 0 * * * ?") // Esegue ogni ora public void performTask() { System.out.println("Esecuzione task programmato"); } @Scheduled(fixedRate = 5000) // Esegue ogni 5 secondi public void performFixedRateTask() { System.out.println("Esecuzione task a intervallo fisso"); } @Scheduled(fixedDelay = 10000) // Esegue 10 secondi dopo la fine dell'ultima esecuzione public void performFixedDelayTask() { System.out.println("Esecuzione task a intervallo ritardato"); } } -
Esecuzione Asincrona con
@Async:@Configuration @EnableAsync public class AsyncConfig { @Bean(name = "taskExecutor") public Executor taskExecutor() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(2); executor.setMaxPoolSize(5); executor.setQueueCapacity(500); executor.setThreadNamePrefix("Async-"); executor.initialize(); return executor; } } @Component public class AsyncScheduledTasks { @Async("taskExecutor") @Scheduled(fixedRate = 7000) public void performAsyncTask() { System.out.println("Esecuzione task asincrono"); } } -
Integrazione con Spring Batch:
@Component public class BatchScheduledTasks { @Autowired private JobLauncher jobLauncher; @Autowired private Job importUserJob; @Scheduled(cron = "0 0 2 * * ?") // Esegue ogni giorno alle 2 AM public void runBatchJob() throws Exception { JobParameters params = new JobParametersBuilder() .addLong("time", System.currentTimeMillis()) .toJobParameters(); jobLauncher.run(importUserJob, params); } }
12. Testing Avanzato
Un’efficace strategia di testing garantisce la qualità e l’affidabilità delle applicazioni.
-
Mocking di Servizi Esterni:
@RunWith(SpringRunner.class) @SpringBootTest public class ServiceTest { @MockBean private ExternalService externalService; @Autowired private MyService myService; @Test public void testServiceMethod() { Mockito.when(externalService.call()).thenReturn("Mocked Response"); String result = myService.process(); assertEquals("Processed Mocked Response", result); } } -
Test End-to-End con Database in Memoria:
@RunWith(SpringRunner.class) @SpringBootTest @AutoConfigureTestDatabase public class RepositoryTest { @Autowired private UserRepository userRepository; @Test public void testSaveUser() { User user = new User("Luca", "luca@example.com"); userRepository.save(user); assertNotNull(userRepository.findById(user.getId())); } } -
Copertura dei Test e Analisi dei Risultati:
-
Strumenti: JaCoCo, SonarQube.
-
Configurazione di JaCoCo con Maven:
<plugin> <groupId>org.jacoco</groupId> <artifactId>jacoco-maven-plugin</artifactId> <version>0.8.7</version> <executions> <execution> <goals> <goal>prepare-agent</goal> </goals> </execution> <execution> <id>report</id> <phase>prepare-package</phase> <goals> <goal>report</goal> </goals> </execution> </executions> </plugin>
-
13. Pattern Avanzati di Architettura
L’adozione di pattern architetturali avanzati può migliorare la scalabilità, la manutenibilità e la robustezza delle applicazioni.
-
Circuit Breaker:
-
Implementazione con Resilience4j:
@Service public class ExternalService { @CircuitBreaker(name = "backendService", fallbackMethod = "fallback") public String callExternalService() { // Chiamata a servizio esterno } public String fallback(Throwable t) { return "Fallback response"; } }
-
-
CQRS (Command Query Responsibility Segregation):
- Separazione delle operazioni di scrittura e lettura per migliorare le performance e la scalabilità.
-
Event Sourcing:
- Persistenza dello stato dell’applicazione come una sequenza di eventi.
14. Ottimizzazioni delle Prestazioni
Migliorare le prestazioni delle applicazioni è essenziale per garantire un’esperienza utente fluida e una gestione efficiente delle risorse.
-
Profilazione con Actuator e Strumenti Esterni:
-
Spring Boot Actuator: Fornisce endpoint per monitorare le performance.
-
Micrometer: Integra metriche con sistemi di monitoraggio come Prometheus.
-
-
Caching Avanzato:
-
Configurazione di Cache con Ehcache:
spring: cache: type: ehcache<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="ehcache.xsd"> <cache name="users" maxEntriesLocalHeap="1000" timeToLiveSeconds="3600"> </cache> </ehcache> -
Uso di Redis per il Caching Distribuito:
@Cacheable("users") public User getUserById(Long id) { // Recupero utente dal database }
-
15. Integrazioni Avanzate
L’integrazione con altri sistemi e framework amplifica le capacità delle applicazioni Spring Boot.
-
Integrazione con Apache Kafka:
@Service public class KafkaProducerService { @Autowired private KafkaTemplate<String, String> kafkaTemplate; public void sendMessage(String topic, String message) { kafkaTemplate.send(topic, message); } } -
Integrazione con Sistemi di Messaggistica:
-
JMS: Java Message Service per la comunicazione asincrona.
-
RabbitMQ: Broker di messaggi basato su AMQP.
-
-
API Gateway per la Gestione delle API:
- Spring Cloud Gateway: Routing dinamico, filtraggio e sicurezza delle API.
16. Deployment e Scalabilità
Garantire che le applicazioni possano scalare efficacemente e siano facilmente distribuibili in diversi ambienti.
-
Strategie di Deployment:
-
Blue-Green Deployment: Riduce il downtime durante gli aggiornamenti.
-
Canary Releases: Distribuzione graduale delle nuove versioni per monitorare il comportamento.
-
-
Scalabilità Orizzontale e Verticale:
-
Orizzontale: Aggiunta di più istanze dell’applicazione.
-
Verticale: Aumento delle risorse (CPU, memoria) di un’istanza esistente.
-
-
Load Balancing:
-
Round Robin, Least Connections, IP Hash.
-
Configurazione con Spring Cloud Gateway o NGINX.
-
17. Best Practices e Consigli
-
Codice Pulito e Manutenibile:
-
Principi SOLID: Guida alla scrittura di codice robusto e flessibile.
-
Design Patterns: Applicazione di pattern come Singleton, Factory, Repository.
-
-
Gestione delle Dipendenze:
-
Maven e Gradle: Strumenti per la gestione efficiente delle dipendenze e del build.
-
Versioning delle Dipendenze: Evitare conflitti e garantire compatibilità.
-
-
Documentazione e Commenti:
-
Javadoc: Creazione di documentazione API utilizzando commenti Javadoc.
-
Swagger/OpenAPI: Documentazione interattiva delle API REST.
-
-
Sicurezza del Codice:
-
Sanitizzazione degli Input: Prevenzione di attacchi come SQL Injection e XSS.
-
Gestione delle Chiavi e dei Token: Uso sicuro delle credenziali e dei token di autenticazione.
-
18. Monitoraggio e Tracciamento
Il monitoraggio continuo e il tracciamento delle applicazioni sono essenziali per mantenere alta la qualità e l’affidabilità.
-
Spring Boot Actuator:
-
Endpoint di Monitoraggio:
/actuator/health,/actuator/metrics,/actuator/loggers. -
Personalizzazione degli Endpoint.
-
-
Tracciamento Distribuito:
-
Zipkin: Strumento per tracciare le chiamate tra microservizi.
-
Sleuth: Integrazione con Zipkin per tracciare le richieste.
-
-
Dashboard di Monitoraggio:
-
Grafana: Visualizzazione delle metriche raccolte.
-
Prometheus: Raccolta e archiviazione delle metriche.
-
19. Gestione degli Errori e delle Eccezioni
Una gestione efficace degli errori migliora l’affidabilità e l’esperienza utente delle applicazioni.
-
Gestione Globale delle Eccezioni:
-
@ControllerAdvice: Gestione centralizzata delle eccezioni.
@ControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(ResourceNotFoundException.class) public ResponseEntity<String> handleResourceNotFound(ResourceNotFoundException ex) { return new ResponseEntity<>("Risorsa non trovata: " + ex.getMessage(), HttpStatus.NOT_FOUND); } @ExceptionHandler(Exception.class) public ResponseEntity<String> handleGenericException(Exception ex) { return new ResponseEntity<>("Errore interno: " + ex.getMessage(), HttpStatus.INTERNAL_SERVER_ERROR); } }
-
-
Custom Error Responses:
@RestControllerAdvice public class CustomErrorController implements ErrorController { @RequestMapping("/error") public ResponseEntity<ErrorResponse> handleError(HttpServletRequest request) { Object status = request.getAttribute(RequestDispatcher.ERROR_STATUS_CODE); if (status != null) { int statusCode = Integer.parseInt(status.toString()); // Creazione di una risposta di errore personalizzata ErrorResponse error = new ErrorResponse("Errore", "Descrizione dell'errore"); return new ResponseEntity<>(error, HttpStatus.valueOf(statusCode)); } return new ResponseEntity<>(HttpStatus.INTERNAL_SERVER_ERROR); } } -
Logging delle Eccezioni:
-
SLF4J e Logback: Logging dettagliato degli stack trace.
@ExceptionHandler(Exception.class) public ResponseEntity<String> handleException(Exception ex) { logger.error("Errore durante l'elaborazione della richiesta", ex); return new ResponseEntity<>("Errore interno del server", HttpStatus.INTERNAL_SERVER_ERROR); }
-
20. Conclusioni
Questa appendice ha esplorato una vasta gamma di argomenti avanzati essenziali per chi si prepara a ruoli di sviluppatore backend specializzato in Spring Boot. La padronanza di questi concetti non solo migliora le competenze tecniche, ma fornisce anche una solida base per affrontare con successo colloqui tecnici e contribuire in modo significativo a progetti complessi.
Bibliografia
-
Spring Framework Documentation: https://spring.io/projects/spring-framework
-
Spring Boot Documentation: https://spring.io/projects/spring-boot
-
Spring Cloud Documentation: https://spring.io/projects/spring-cloud
-
Spring Batch Documentation: https://spring.io/projects/spring-batch
-
Resilience4j Documentation: https://resilience4j.readme.io/docs
-
Spring Integration Documentation: https://spring.io/projects/spring-integration
-
Spring Security Documentation: https://spring.io/projects/spring-security
-
Spring WebFlux Documentation: https://spring.io/projects/spring-webflux
-
Apache Kafka Documentation: https://kafka.apache.org/documentation/
-
Docker Documentation: https://docs.docker.com/
-
Kubernetes Documentation: https://kubernetes.io/docs/home/
-
Micrometer Documentation: https://micrometer.io/docs
-
JaCoCo Documentation: https://www.jacoco.org/jacoco/trunk/doc/
-
Flyway Documentation: https://flywaydb.org/documentation/
-
Liquibase Documentation: https://www.liquibase.org/documentation
Glossario
-
AOP (Aspect-Oriented Programming): Paradigma di programmazione che consente di separare le logiche trasversali dal codice core.
-
BPM (Business Process Management): Gestione e ottimizzazione dei processi aziendali.
-
CRUD (Create, Read, Update, Delete): Operazioni fondamentali per la gestione dei dati.
-
CQRS (Command Query Responsibility Segregation): Pattern che separa le operazioni di scrittura da quelle di lettura.
-
Dependency Injection (DI): Tecnica di programmazione per iniettare le dipendenze di un oggetto invece di crearle direttamente.
-
EIP (Enterprise Integration Patterns): Pattern per l’integrazione di sistemi aziendali.
-
JWT (JSON Web Token): Standard per la trasmissione sicura di informazioni tra parti come oggetti JSON.
-
Micrometer: Libreria per la raccolta di metriche applicative.
-
MDC (Mapped Diagnostic Context): Strumento per arricchire i log con informazioni contestuali.
-
Resilience4j: Libreria per implementare pattern di resilienza come circuit breaker e rate limiter.
-
SOLID: Principi di design orientato agli oggetti per creare software più comprensibile, flessibile e manutenibile.
-
Spring Boot Actuator: Strumento per monitorare e gestire applicazioni Spring Boot in produzione.
-
Spring Cloud: Suite di strumenti per lo sviluppo di applicazioni distribuite e microservizi.
-
Spring Data: Modulo per semplificare l’accesso ai dati con repository basati su interfacce.
-
Spring MVC: Framework per lo sviluppo di applicazioni web basate sul pattern Model-View-Controller.
-
Spring Security: Framework per la gestione della sicurezza nelle applicazioni Spring.
-
Spring WebFlux: Framework reattivo per lo sviluppo di applicazioni web non bloccanti.
-
Swagger/OpenAPI: Strumenti per la documentazione interattiva delle API REST.
-
WebFlux: Framework reattivo per applicazioni web con supporto per programmazione non bloccante.
Esercizi e Problemi Avanzati
Per consolidare la comprensione degli argomenti trattati in questa appendice, si consiglia di affrontare i seguenti esercizi pratici:
-
Implementare un Aspect per il Logging:
-
Crea un aspect che registra il tempo di esecuzione di ogni metodo in un determinato pacchetto.
-
Testa l’aspect su diversi metodi e verifica i log generati.
-
-
Sviluppare un Job Batch con Spring Batch:
-
Configura un job che legge dati da un file CSV, li elabora e li scrive su un database.
-
Implementa la gestione del riavvio del job in caso di fallimenti.
-
-
Creare un Flusso di Messaggi con Spring Integration:
-
Configura un flusso che riceve messaggi da una coda JMS, li trasforma e li invia a un altro sistema.
-
Implementa un transformer personalizzato.
-
-
Costruire un’API Reattiva con WebFlux:
-
Sviluppa un controller reattivo che gestisce richieste asincrone.
-
Integra WebSockets per una comunicazione in tempo reale.
-
-
Gestire Profili Multipli:
-
Configura diverse configurazioni per ambienti di sviluppo e produzione.
-
Implementa un endpoint che cambia comportamento in base al profilo attivo.
-
-
Implementare OAuth2 con JWT:
-
Configura Spring Security per utilizzare OAuth2 e JWT per l’autenticazione.
-
Proteggi alcune API con ruoli specifici.
-
-
Ottimizzare le Prestazioni con il Caching:
-
Implementa il caching con Redis per ridurre i tempi di risposta di alcune API.
-
Configura le politiche di invalidazione del cache.
-
-
Distribuire un’Applicazione su Kubernetes:
-
Crea un’immagine Docker dell’applicazione Spring Boot.
-
Configura un deployment e un service su Kubernetes.
-
Implementa un Horizontal Pod Autoscaler.
-
-
Scrivere Test Avanzati:
-
Crea test unitari e di integrazione per servizi complessi.
-
Utilizza MockMvc per testare i controller RESTful.
-
Configura JaCoCo per analizzare la copertura dei test.
-
-
Monitorare l’Applicazione in Produzione:
-
Configura Spring Boot Actuator per esporre metriche.
-
Integra Prometheus e Grafana per visualizzare le metriche raccolte.
-
Implementa alerting per monitorare le performance e gli errori.
-
Seguendo e approfondendo questi argomenti avanzati, sarai in grado di affrontare con competenza e sicurezza le sfide tecniche che incontrerai nel tuo lavoro.